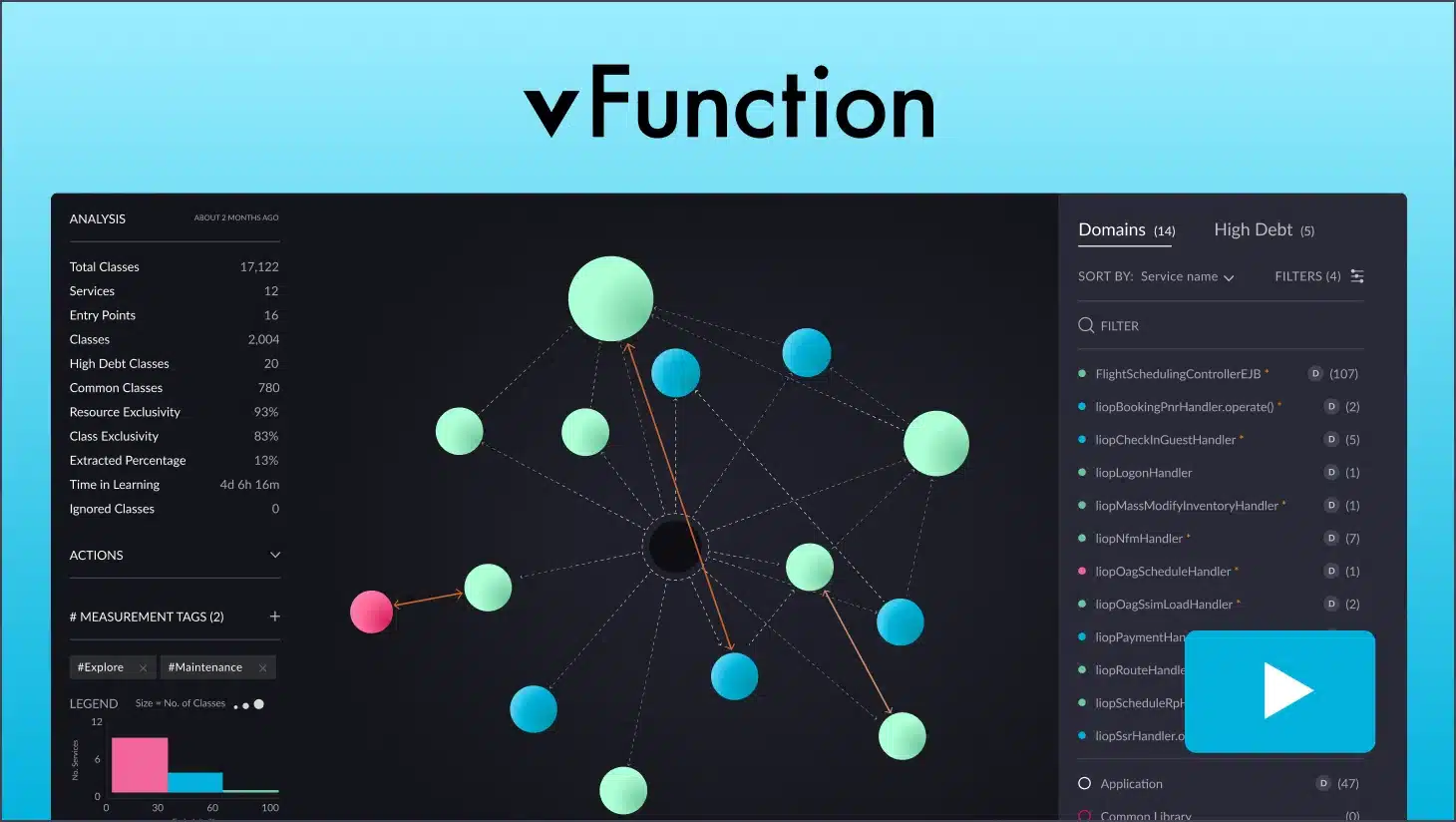
Architectural observability demo
Watch Now2025 Architecture in Software Development Report. Rethinking the role of architecture in the age of AI.
Download Now
Architectural observability demo
Watch Now
Ending Microservices Chaos
Download Now
Accelerate your AWS cloud migration journey
Learn More
Tips for CIOs to Jump-Start Stalled Application Modernization Initiatives
Download Now
DZone Observability & Performance Trend Report
Download Now
Discover how vFunction accelerates modernization and boosts application resiliency and scalability.