Have you ever tried to debug a bit of code and been unable to get the breakpoint to hit it? Is there a variable that exists but is unused at the top of your file? In software engineering, these are typical examples of dead code existing within seemingly functional programs. There are quite a few ways that dead code comes into existence; nonetheless, this redundant and defunct code occupies valuable space and can hinder your application’s performance, maintainability, and even security.
Dead code often arises unintentionally during software evolution — feature changes, refactoring, or hasty patches can leave behind code fragments that are no longer utilized. Identifying and eliminating this clutter is crucial for any developer striving to create streamlined and optimized applications. Unfortunately, finding and removing such code is not always so straightforward.
In this blog, we’ll take a deep dive into dead code. We’ll define it, understand how it sneaks into our codebases, explore tools and techniques to pinpoint it, and discuss why it should be on every technical team’s radar. Let’s begin by digging deeper into the fundamentals, starting with a more complete explanation of what dead code is.
What is dead code?
Dead code is a deceptive element that lurks within many software projects. It refers to sections of source code that, even though they exist in the codebase, offer zero contribution to the program’s behavior. The outcome of this code is irrelevant and goes unused.
To better grasp how dead code can present itself, let’s take a look at a few common ways it pops up:
Unreachable code
Picture a block of code positioned after a definitive return statement or an unconditional jump (like a break out of a loop). Though it exists, this code will forever remain beyond the executing program’s reach.
Zombie code
A variant of unreachable code, zombie code is one of the hardest types of dead code to identify. This type occurs when code execution branches are simply never taken in production systems. It is also the most dangerous as slight changes to the code may cause this branch to “come alive” suddenly with potentially unexpected results. Listen to the podcast below for a deeper discussion on zombie code.
Unused variables
Imagine variables that are declared and seem to have a reason for existing, perhaps even given initial values, but ultimately left untouched — their existence unjustifiable within computations or expressions, mainly just leading to confusion for the developers working on the code.
Redundant functions
It is not uncommon to encounter functions mirroring the capabilities of their counterparts. These replicas contribute little to the application’s functionality but do add unnecessary bulk to the codebase.
Commented-out code
Fragments of code, often relics from a bygone era of debugging or experimentation, may be shrouded in comments. However, their abandonment, rather than deletion, transforms them into a great mystery for the developers who encounter them later (e.g., “Is this supposed to be commented out or what?”)
Legacy code
As software evolves, feature removals or refactoring can inadvertently cause dead code to remain in the codebase that is no longer relevant. Once-integral elements may become severed from the core functionality and are left behind as obsolete remnants.
It’s important to note that dead code isn’t always overtly obvious. It can manifest subtly, requiring manual audits and potentially specialized detection tools. Now that we know what dead code is and how it presents within code, the next logical question is why it occurs.
Why does dead code occur?
The phenomenon of dead code frequently emerges as a byproduct of the dynamic nature of the software development process. As the breakneck speed of software development continues to increase, knowing what causes it can help you be on the lookout and potentially prevent it. Let’s break down the key contributors:
Rapid development and iterations
The relentless focus on delivering new features or meeting strict deadlines can lead developers to unintentionally leave behind fragments of old code as they make modifications. This is even more common when multiple developers work simultaneously on a single code. Over time, these remnants become obsolete, subtly transforming into dead code.
Hesitance to delete
During debugging or experimental phases, developers often resort to “commenting out” code sections rather than removing them entirely. This stems from believing they might need to revert to these snippets later. Most developers have done this at some point, whether due to a reluctance to utilize source control or just an old habit. However, as the project progresses, these commented-out sections can quickly fade into the background and become forgotten relics, leading to confusion for the developers who later run into them.
Incomplete refactoring
Refactoring, the process of restructuring code to enhance its readability and maintainability, can sometimes inadvertently produce dead code. Functions or variables may become severed from the primary program flow during refactoring efforts. If the refactored code is not well-managed, usually through code reviews and other quality checks, these elements can persist as hidden inefficiencies.
Merging code branches
Redundancies can surface when merging code contributions from multiple developers or integrating different code branches. Lack of clear communication and coordination within the team can lead to duplicate functions or blocks of code, eventually making one version dead weight. Depending on the source control system used, this may not be as big of a concern.
Lack of awareness
Within large or complex projects, it’s challenging for every developer to understand all system components comprehensively. This lack of holistic visibility makes it difficult to identify when changes in code dependencies have rendered certain sections of code obsolete without anyone being explicitly aware of the situation.
You and your team have probably experienced many of the causes listed above at some point. Dead code is a fact of life for most developers. That being said, dead code can still affect an application’s performance and maintainability. Next, let’s look at how we can identify dead code.
How do you identify dead code?
Pinpointing dead code within a codebase is like detective work. As we have seen from previous sections, the way that dead code is introduced into a codebase can make it hard to detect. In some cases, it does a great job of hiding amongst the functional pieces of an application. Fortunately, you have several methods and tools at your disposal.
Manual code review
One way to identify dead code is to use manual code review methods to assess if code is redundant or tucked into unreachable logic branches. While feasible in smaller projects or targeting specific areas, manually combing through code for dead segments can be labor-intensive and doesn’t scale well.
Static code analysis tools
The first automated answer in our list for identifying dead code is static analysis tools. These tools dissect your codebase to detect potential dead code patterns and redundant code. Although different tools in this category have different approaches, most track control flow, analyze data usage, and map function dependencies to flag areas needing closer inspection. With static code analysis, there is always a chance that seemingly dead code is used when the app is executed, known as a false positive. There’s also the fact that static analysis can’t simulate every possible execution path, so “zombie” code will likely be identified as “live”.
Profilers
Code profilers are primarily used to measure performance but can also contribute to dead code discovery. Profiling runtime execution can expose functions or entire code blocks that are never invoked. Static code analysis tools scan the code in a static, not-running state, whereas profilers watch the running program in action so that there is runtime evidence of dead code. Unlike static analysis, profilers are limited to the code running when the application is profiled. This means there is never a way to prove that the profiler robustly covered all the relevant flows.
Test coverage
Building out high-coverage test suites that thoroughly test your code illuminates untouched areas. Many IDEs and testing frameworks can show code coverage, some highlighting areas of the code that tests have not executed. Although unexecuted code may signal poor test coverage and not necessarily denote dead code, it is a potential starting point for further investigation.
vFunction
With the ability to combine many of the abovementioned capabilities, vFunction’s architectural observability platform excels at pinpointing dead code. Using AI, analyzing static code structure and dynamic runtime behavior, vFunction can identify complex and deeply hidden cases of dead code that other tools might miss. If dead code is found, vFunction can provide clear visualizations and actionable recommendations for remediation. More on these exact features can be seen further down in the blog.
Complex codebases and dynamic behavior may still necessitate a developer’s understanding of the underlying application logic for the most effective dead code identification. Although automated methods are great for flagging areas that could be dead code, it still takes a human touch to verify if code should be removed. When it comes to which tools you should use, combining the above approaches is usually required to yield the most comprehensive results, balancing static and dynamic testing methods.
Why do you need to remove dead code?
The presence of dead code, though seemingly harmless, can have surprisingly far-reaching consequences for software health and development efficiency. Here’s why it’s crucial to address:
Keeping technical debt in check
Reducing the amount of dead code within your application remains highly important for reducing technical debt. From the perspective of architectural technical debt, having dead code stay within your project means that quite a few areas of the app can suffer. It’s hard to understand and optimize an application with chunks of code that do nothing but clutter the codebase and potentially skew various architectural metrics such as the size of the application, lines of code, complexity scoring, test coverage, etc.
Maintainability suffers
Dead code clutters your codebase, obscuring essential code paths and impeding a developer’s understanding of core logic. The result is increased difficulty with bug fixes, slower feature development, and increased overall maintenance effort.
Security risks rise
Dead code may contain outdated dependencies or overlooked vulnerabilities. Imagine a scenario where a vulnerable library, no longer used in active code, persists in an unused code section. This can lead to an expanded attack surface that attackers could still exploit.
Performance can degrade
Compilers may face challenges optimizing code with dead segments present since they generally do not detect whether code is actively used or not. Additionally, with the exception of commented-out code, which is normally removed from the compiler output, dead code could potentially be executed at runtime, unnecessarily wasting compute resources.
Confusion reigns
Dead code creates confusion for developers. Since the dead code’s purpose or previous function may not be apparent, developers must waste time investigating its purpose. In other cases, developers may fear that removal could cause unintended breakages or create challenges in the developer’s confidence in refactoring the application’s code.
The above reasons are quite compelling when it comes to taking the time to remove dead code. Of course, when it comes to developing software, dead code creates quite a few issues beyond what we just discussed. These consequences can manifest in the team’s workflow itself, impact the application at runtime, and other issues.
Consequences of dead code in software
Taking a further look at what was discussed in the previous section, let’s further explore the specific consequences of dead code living within a codebase.
Hidden bugs
Dormant bugs may also be present within dead code, waiting for unexpected circumstances to activate a defunct code path. This leads to unpredictable errors and potentially lengthy debugging processes down the line.
Security vulnerabilities
Obsolete functions or dependencies hidden within dead code can expose security weaknesses. If these remain undetected, your application is susceptible to being exploited through your application’s expanded attack surface.
Increased cognitive load
Dead code acts as a mental burden, forcing developers to spend time parsing its purpose, often to no avail or further confusion. This detracts from their focus on the core functionality and building out further features.
Slower development
Navigating around dead code significantly slows development progress. In projects with excessive dead code, developers must carefully ensure their changes don’t unintentionally trigger hidden dead code paths and affect the applications existing functionality.
Elevated testing overhead
Dead code artificially increases the amount of code requiring testing. This means more test cases to write and maintain, draining valuable resources. If code is unreachable, developers may waste cycles trying to increase code coverage or end up with skewed code coverage metrics since it is usually calculated on a line-by-line basis, regardless if the code is dead.
Larger application size
Lastly, dead code increases your application’s overall footprint, contributing to slower load times, increased memory usage, and increased infrastructure costs.
Overall, dead code may seem somewhat harmless. Maybe this is due to the abundance of dead code that exists within our projects, unknowingly causing issues that we see as “business as usual”. By reducing or eliminating dead code, many of the concerns above can be taken off the plates of developers working on an application.
How does vFunction help to identify and eliminate dead code?
vFunction is an architectural observability platform designed to help developers and architects conquer the challenges posed by technical debt, including dead code. Its unique approach differentiates it from traditional analysis tools, providing several key advantages:
Comprehensive AI-powered analysis
Automated analysis, leveraging AI, is what we do at vFunction. Our patented analysis methods compare the dynamic analysis with the static analysis in the context of your domains, services, and applications. By compiling a map of everything, you can quickly identify any holes in the dependency graph.
Deep visibility
By understanding how your code executes with dynamic analysis, vFunction can uncover hidden or complex instances of dead code that traditional static analysis tools might miss. This is especially valuable for code only triggered under specific conditions or within intricate execution branches.
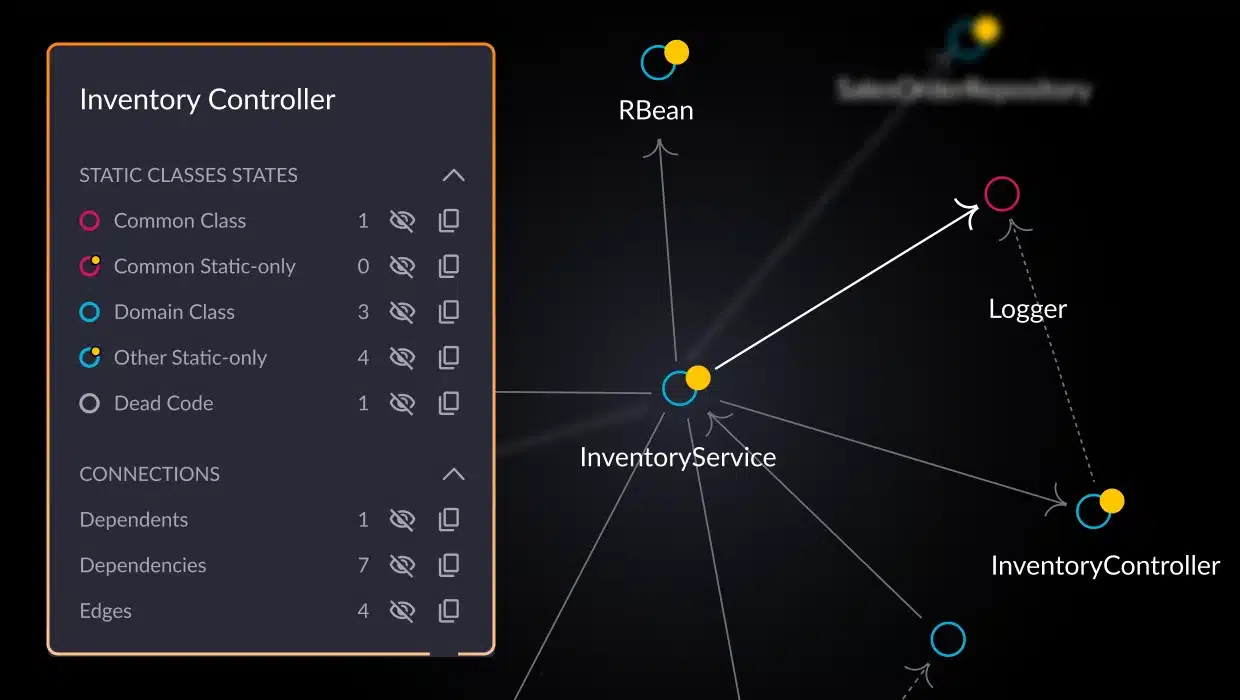
Domain dead code
For example, it can be particularly challenging to determine if code is truly unreachable if the class is used across domains, potentially using multiple execution paths. vFunction uniquely identifies this “domain dead code” with our patented comparisons of the dynamic analysis with the static analysis in the context of your domains, services and applications.
Contextual insights
vFunction doesn’t merely flag suspicious code; it presents its findings within the broader picture of your system’s architecture. You’ll understand how dead code relates to functional components, enabling informed remediation decisions.
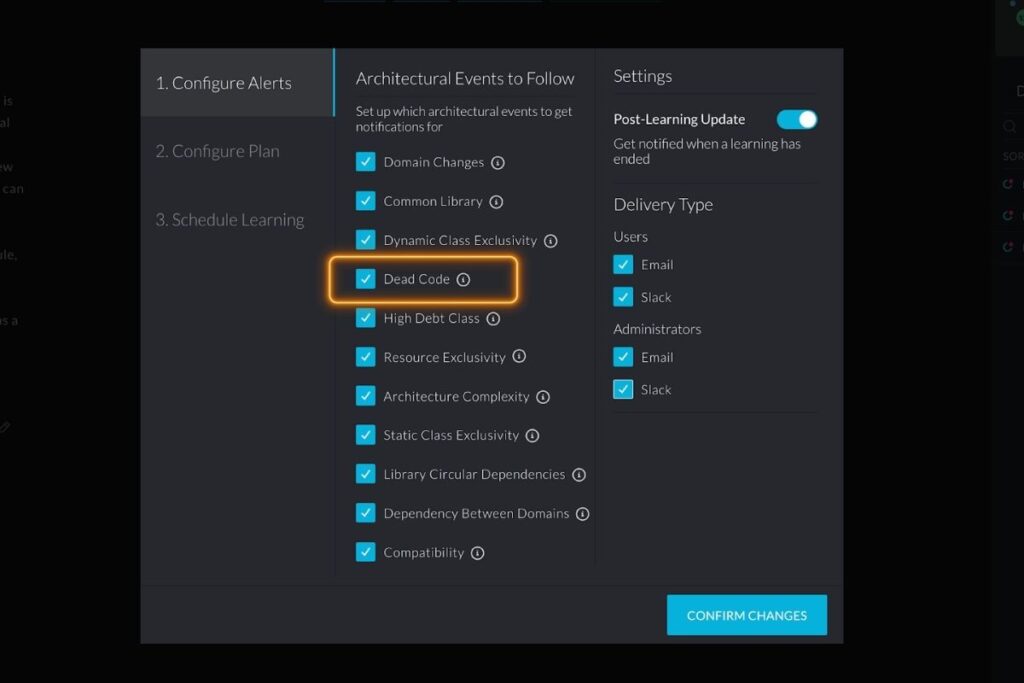
Alerting and prioritization
Architectural events provide crucial insights into the changes and issues that impact application architectures. vFunction identifies specific areas of high technical debt, including dead code, which can impact both engineering velocity and application scalability.
Actionable recommendations
Once identified, vFunction provides clear guidance on safely removing the dead code. vFunction supports iterative testing and refactoring. For example, vFunction can determine whether to refactor a class and eliminate two other classes while maintaining functionality. This minimizes the risk of making changes that could impact your application’s functionality and behavior.
By leveraging vFunction, developers and architects can quickly uncover dead code and see a path to remediation. The capabilities within vFunction allow you to pinpoint and eliminate dead code with accuracy and confidence, promoting a cleaner, more streamlined codebase that is easier to understand and maintain.
Conclusion
Though often overlooked, dead code threatens code quality, maintainability, and security. By understanding its origins, consequences, and detection techniques, you can arm yourself with the knowledge to fight against this common issue. While many tools can help find dead code in various ways, vFunction provides a new level of insight into finding and removing dead code. With architectural observability capabilities on deck, your team can achieve a deeper understanding of your application and codebase, empowering you to make informed and effective dead code removal decisions. Curious about dead code within your projects? Try vFunction today and see how easy it is to quickly identify and remediate dead code.