This post was originally featured on TheNewStack, sponsored by vFunction.
“Dead Code,” aka zombie code, refers to unreachable legacy code residing inside applications and common libraries that is not called by any current services. It shows up unpredictably and grows over time, contributes to technical debt and presents an unknown potential security risk for cyberattacks.
What Is Zombie Code and Why Should We Worry about It?
Dead code is not something widely spoken about in the overall Java community, but it’s there. At vFunction, we’ve taken to calling it zombie code, since if it were “really dead” it wouldn’t be unpredictably accessed without developers knowing about it — and if left unattended, it gets more dangerous by the day.
So while many developers may be unaware that zombie code exists, it nevertheless requires some attention. If you’re an architect or developer looking to refactor your legacy systems and begin a process of continuous modernization, this will help you eliminate technical debt early on.
Fact #1: Zombie Code Is Hard to Discover
If you’re aware of this at all, then “dead code” is probably the term you’re more familiar with. Dead code is usually referred to as unreachable code — it resides in a service or application that’s never accessed.
Let’s imagine that you’ve inherited a legacy application that has been updated with significant changes over time based on new functionality and user demands. Legacy code that was once needed is now no longer using a certain functionality, so the code is still there but not used. As developers or architects, you rarely have insight into just what functionality and code isn’t used anymore.
Theoretically, you never touch this code. Depending on the complexity of this dead code, an integrated development environment (IDE) like IntelliJ IDEA or Visual Code Studio may point it out, which means you can just delete it. For the majority, however, there are situations where it’s not possible to identify code that doesn’t run because of the context in which it’s supposed to run.
This requires additional tools like profilers and dynamic analysis at runtime to really understand whether the code is used. If it’s really dead code, it never runs in the context of your production application, though it may run and be covered in your tests. While test coverage is good for ensuring basic security measures, it also makes this code extremely difficult to find.
Remember: Zombie code is left over from previous years, and even though your systems may run differently now, the same legacy code and classes are still called into your project. No one really knows how it’s going to be used; those classes may be called through a different API, or maybe not. It’s this lack of transparency and predictability that makes dead code in your application risky.
Fact #2: Zombie Code Accumulates Technical Debt (and Shouldn’t Be Ignored)
Development teams looking to modernize legacy applications are likely trying to escape the “don’t touch anything because it could break” mentality. Yet here it’s tempting to ask why can’t we just ignore dead code if it’s being tested (somehow) and not breaking anything.
The short answer is that dead code accumulates over time until its level of technical debt is so large that it begins to block development. In fact, high-velocity development teams will accumulate technical debt in the form of dead code even faster.
Let’s look at the best-case scenario of keeping dead code in your legacy system. You can simply continue to test and maintain this code that never runs. Then you’re just wasting time and resources on code that doesn’t actually do anything.
Now the worst-case scenario, which is that this code hasn’t been maintained or properly tested for a while. If you’re a developer adding new functionality, there is nothing preventing you from stumbling across this dead code — it’s not traced, monitored or identified.
This means that an ancient, forgotten class can easily be revived through some new behavior paths added to the functionality of the application. And because no one knows it’s there, you cannot be confident that this dead code won’t create downstream issues in the application later.
Fact #3: Zombie Code Adds Complexity Over Time
So far, we’ve talked about the type of zombie code that is more akin to extra baggage, just floating along and not really bothering anything (we hope). As dead code accumulates, however, it can easily become more entangled and complex.
Imagine a scenario in which Java classes are being used in several domains where multiple services might use the same class in different ways. A certain service may use a class one way, and a different service will use that same class a different way, calling different code paths.
When we analyze a specific class only in the context of a specific service, then everything that’s not called from that specific service can be seen as dead code. If we take the same class and look at how it’s used in another service, then half of the code is going to be dead, but standard code coverage tests and application performance management (APM) tools like New Relic and Datadog will show those classes running. No dead code, right?
Well, not really. This is where you start looking at the runtime environment, not at a specific class that perhaps your IDE was able to flag. This is the whole call tree and stack of classes being called one after the other. Only by looking at the context of where a class was called based on the service, domain and endpoint can you deeply understand which paths in the code shouldn’t be there.
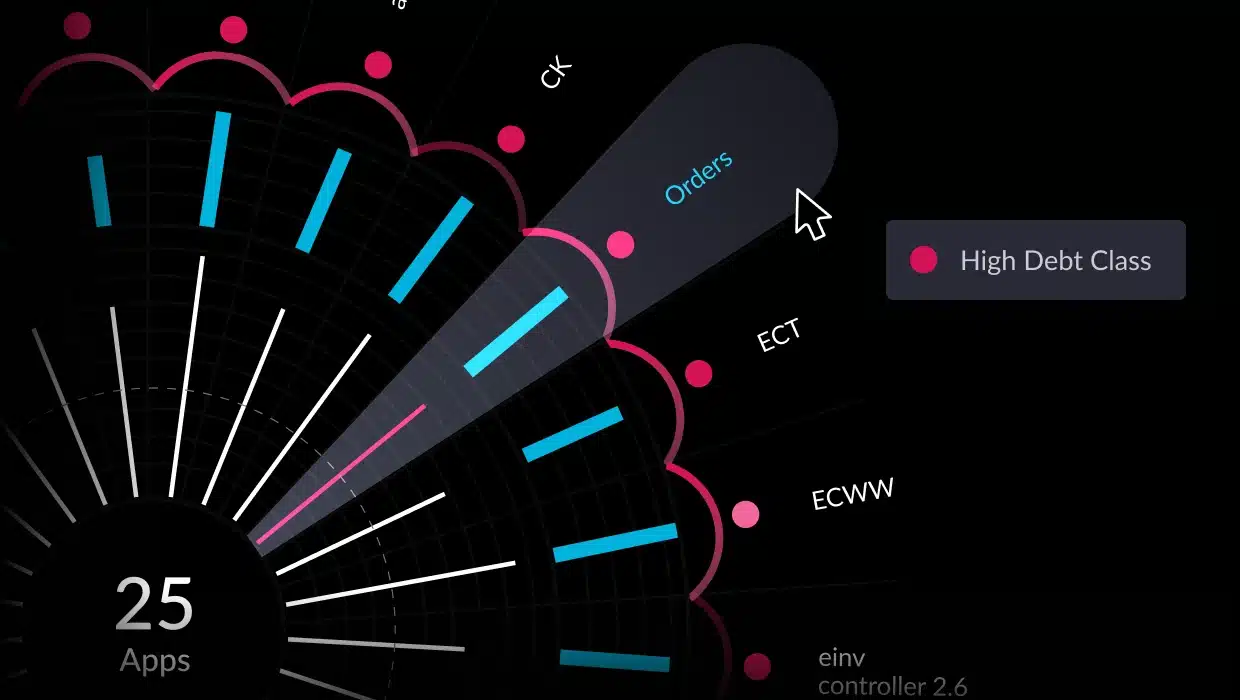
This is where you need better intelligence from your static and dynamic analysis (incidentally, what we do at vFunction) for identifying more complex classes of dead code that cause clutter, complexity and break the modularity of your code.
Fact #4: Zombie Code Is a Potential Security Threat
If you’re an architect or developer looking at your code base, you’ll generally spend more time with the classes that you’re actually working on, not the other 10 million lines of code in your legacy monolith.
The nature of zombie code is that unless something breaks at compile time, most developers working on a project would have no clue that this code even exists. The inability to have insights into your complete code base is a risk not only to productivity but also security.
Aside from famous data breaches on companies like Equifax and Yahoo, recently a group called Elephant Beetle figured out a way to exploit legacy Java apps to the tune of millions of dollars. So it’s well understood that legacy technologies present an opportunity for cyberattacks.
This is where technical debt rears its ugly head: The dead code in your code base is still being scanned with the same tools, but it’s not being maintained in the same way. Processes and best practices that were initiated five or 10 years ago when the code was written are unlikely to be the same in place today.
So if you’re not looking at this accumulation of dead code, who else might be? The security threat here is that dead code isn’t affecting your regular users. This means that any bad actor that tries to find it can potentially be able to exploit it using legacy vulnerabilities.
Fact #5: You Can Eliminate Zombie Code Manually (DIY) or Use Automation and AI
Searching for zombie code is a bit like trying to see a black hole with a telescope — it’s more about detecting the absence of something rather than witnessing the existence of it. When looking at the constellation of your application’s Java classes, you need to look for the dark places in the middle.
So what would it be like to identify and destroy zombie code in your own legacy monolith manually? Where does the DIY process begin, and how does it look?
Here is a list of processes and ideas for proceeding manually with analyzing your systems for dead code. Of course, it all starts with awareness, as with anything else regarding good software engineering.
- Don’t Pass Go: Did you spot a piece of code that seems familiar but you don’t really know what it’s used for? Next time, don’t skip it: Mark it for later investigation as the first proactive step toward removing dead code.
- Use Code Coverage Tools: If you use these, dig a little deeper to see which classes are covered — or not covered — by various tools. If a certain class is not covered at all, you can potentially consider it dead code after testing it.
- Create Specific Tests: If you stumble upon suspicious code, consider creating a simple set of specific tests to discover why it’s not covered. Some tests would be related to a specific service or module so you can see the coverage of those specific pieces rather than all the tests together of the entire system.
- Leverage APM Platforms: If you have APM tools like New Relic, Datadog, AppDynamics or Dynatrace running in your production systems, you can use this data to compare with your coverage reports to see which paths are covered.
If you’re able to prepare and run these different testing scenarios manually, then good for you! But what is the output, and how would you bring everything together?
Imagine a legacy application that has 10,000 Java classes and you need to distribute the manual interaction, test creation, CI/CD pipeline deployment and dive into the resulting reports and logs across a team. Different levels of expertise and motivation in the team will make it difficult to share out the work.
The dynamic flows provide the base information, giving you the real production flows running through the system. Dead code itself will not be running in those flows, so you need to take your static analysis and kind of carve out pieces that didn’t appear in the dynamic analysis in those specific flows.
Now, let’s look at another alternative, using artificial intelligence (AI) and automation to do the heavy lifting.
How to Eliminate Zombie Code — AI + Automation
The DIY modernization process is a fairly heavy lift for most teams; unless your organization can get buy-in from the executive team to reassign your best and most experienced engineers from their core objectives, any modernization project is going to be difficult.
Legacy monoliths present challenging, real-life problems that engineers have to deal with. So what if we could automate some or even most of this process? Compared to spending weeks and months to analyze some of the classes in the monolith, installing software to do this part for you ends up taking just minutes and hours.
Dead code must be deleted, but it’s difficult to know exactly where. Interdependencies in one class that tie into three other classes that are needed cannot simply be erased. We support iterative testing and refactoring so you can determine whether to refactor the first class and get rid of two other classes, for example.
Automated analysis, leveraging AI, is what we do at vFunction. Our patented methods of analysis compare the dynamic analysis with the static analysis in the context of your domains, services and applications. By compiling a map of everything, you’re able to quickly identify those black holes in the dependency graph, giving you a place to start.
Instead of showing long reports of individual data points, vFunction brings everything together into a big picture so that you can see what’s going on and then figure out how to take action.
If you are sick of managing old systems like we’ve been talking about, you can visit vfunction.com. This will give you an idea of how much legacy applications are costing you to maintain each year and potentially help you get project backing for modernization initiatives.
Feature image via Pixabay.