How we design and build software systems has undergone extensive transformation as cloud and serverless computing usage continues to grow — various technologies within a single architecture used to be more of a puzzle than a common scenario. We are seeing a move from traditional monolithic architecture, where all components of an application are tightly coupled and run on a single server, being replaced by a more flexible and scalable approach: distributed architecture, mainly driven by cloud migrations.
As demand for high performance and reliability becomes the default, understanding the principles and benefits of distributed architectures is essential for architects and developers to build applications that meet customer demands. In this blog post, we’ll look at the fundamentals of distributed architecture, explore various types and examples, and discuss how modern tools can help when it comes to successfully building and scaling this architectural paradigm. First, let’s take a deeper dive into the fundamentals of distributed architecture.
What is a distributed architecture?
A distributed architecture is a software system deployed across multiple interconnected computational nodes. These nodes can be physical or virtual servers, containers, or serverless functions like AWS Lambda, Azure Functions, or Google Cloud Functions. In essence, a distributed architecture allocates an application’s workload across multiple nodes rather than relying on a single central server. This approach can enhance scalability, performance, and resilience by leveraging the processing power of multiple resources, however, its biggest benefit has to do with the ability to develop and deploy each node separately which allows to significantly increase engineering velocity. In this article we will focus on the operational benefits of distributed architecture, even though they are not always the main driver for transforming monolithic workloads into distributed ones, like microservices.
The primary operational goal of distributed computing systems is to enhance an application’s scalability, fault tolerance, and performance. By distributing the workload across multiple nodes, the system can handle variable volumes of traffic and data without compromising speed or reliability. Monolithic architectures tend to struggle with this aspect. Additionally, if one node fails, the others can continue operating, so processes not affected by an outage or issue can continue functioning as intended, ensuring minimal disruption to the overall application.
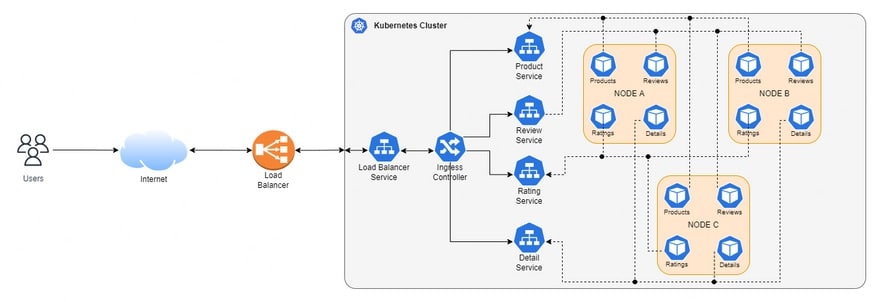
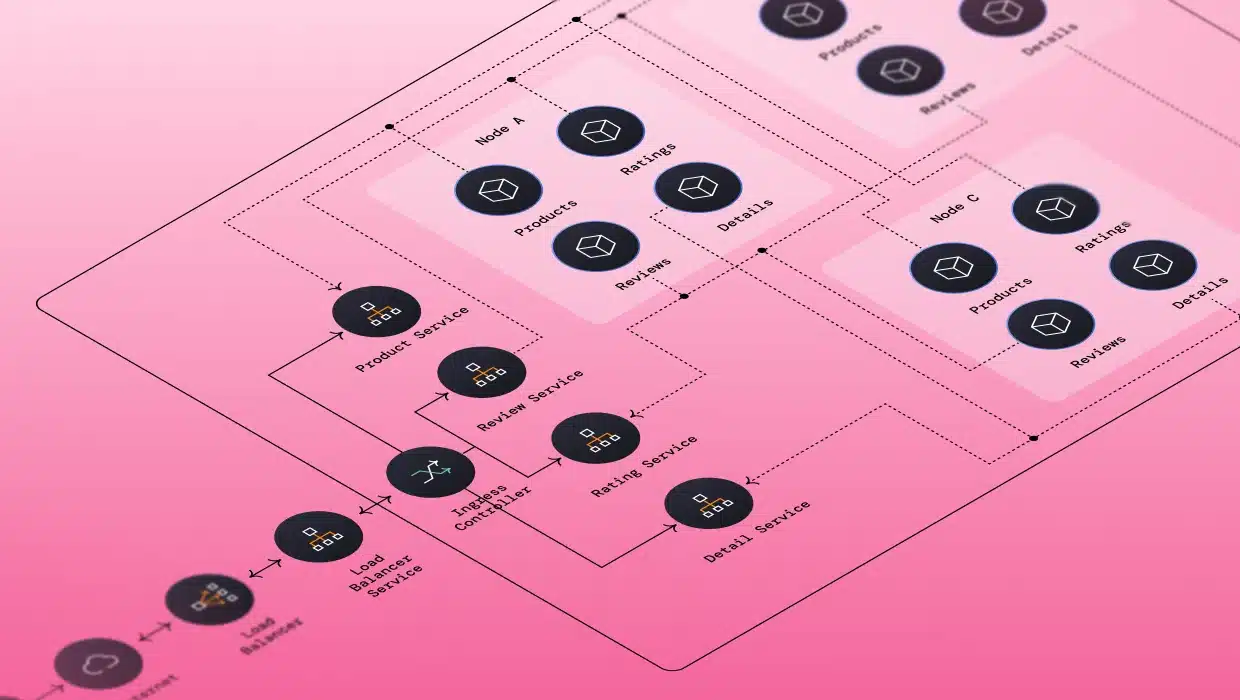
The above image exemplifies a distributed architecture over Kubernetes (K8S). A load balancer redirects traffic from users to one or more K8S clusters, which also uses an internal load balancer to redirect requests to multiple nodes in the cluster running different services (for more details, see the original post). You’ll likely recognize that some of the systems you’ve built fit into the distributed paradigm, intentionally or not. This style of architecture has become a go-to approach for most modern applications. How distributed architectures work might not be as apparent, so let’s cover that next.
How do distributed architectures work?
Distributed architectures operate through a network of interconnected services, each with roles and responsibilities regarding application functionality. Let’s examine some of these design choices that define a distributed architecture:
Communication
Services interact through well-defined protocols like REST (Representational State Transfer) or gRPC (Google Remote Procedure Call). These protocols enable services to request data or trigger actions from one another, facilitating seamless collaboration and enabling the connectivity between the components within the application architecture.
Depending on the requirements, various messaging and streaming frameworks, like Apache Kafka or Rabbit MQ, may be considered.
Coordination and synchronization
To maintain consistency and avoid conflicts, distributed architectures must employ techniques like leader election (a single service coordinates others), distributed consensus (services agree on a shared state), and distributed locks (preventing concurrent access to resources).
Data management strategies
Data within distributed architectures can be managed through replication (multiple copies across nodes for redundancy), sharding (partitioning data for scalability), or specialized distributed databases optimized for handling data spread across various locations. Overall, this aspect of a distributed application can be the most complex to manage and has the largest impact if implemented incorrectly.
Load balancing
Distributed architectures often employ load balancers to ensure optimal performance and prevent overload. These systems intelligently distribute incoming requests across multiple services, generally through an active-active or active-passive configuration, maximizing resource utilization and responsiveness.
Ensuring that each component can handle load, concurrency, and scalability should result in a highly functioning distributed architecture. These concerns differ from those of a more traditional centralized architecture. To understand more about how the two work differently, let’s do a quick comparison.
Distributed architecture vs. centralized architecture
Centralized architectures, the traditional approach to software design, rely on a single, powerful central server to handle all processing, storage, and management tasks. While a centralized system can be simpler to implement and manage initially, distributed computing can overcome several limitations. Both approaches still have advantages, so it makes sense to understand which architecture is better for your needs and what tradeoffs come into play.
Let’s look at a summary of the differences between the two covering operational and non-operational aspects (like development/engineering velocity):
| Feature | Centralized architecture | Distributed architecture |
| Scalability | Limited by the capacity of the central server. | Highly scalable; can be expanded by adding more nodes. |
| Fault tolerance | Vulnerable to single points of failure; if the central server fails, the system goes down. | Resilient to failures; if one node fails, other nodes can take over its responsibilities. |
| Performance | Can become a bottleneck under heavy loads as all requests go through the central server. | Offers better performance under high loads as the workload is distributed across multiple nodes. |
| Flexibility | Less flexible to change as all components are tightly coupled and dependent on the central server. | More flexible and adaptable as components are loosely coupled and can be modified or replaced independently, even deployed on different operating systems. |
| Cost | Can be expensive to scale as upgrading the central server requires significant investment. | More cost-effective to scale as it involves adding commodity hardware or virtual machines. |
| Deployment | Easy and fast deployment | Complicated for the entire system |
| Testing | Requires end-to-end testing and hard to achieve full coverage | Individual component testing |
| Development / Engineering Velocity | Harder to distribute efforts, often limited due to a large indivisible database | Teams can work independently on the various services |
As demand for applications has increased in various ways, this has naturally made architects and developers shift towards distributed computing as the go-to approach over centralized and monolithic ones. A few concrete reasons for this shift include:
- Increasing data volumes: Modern applications generate massive amounts of data, which can overwhelm centralized servers.
- Growing user demands: Users expect fast and responsive applications, even under peak loads.
- Cloud computing: Cloud platforms provide the infrastructure and tools to quickly deploy and manage distributed systems.
- Microservices: The rise of microservices architecture, where developers build applications as a collection of small, independent services, naturally lends itself to distributed deployments.
Although centralized architectures have their place, the advent of cloud computing has pushed teams to make many applications and their infrastructure more distributed. Under the umbrella of distributed architectures, though, we will look at a few specific types next and further explore the differences.
Types of distributed architectures
Just like most architectural paradigms, distributed application architecture also comes in various flavors. Each variant caters to specific use cases and requirements and offers different benefits. Let’s explore some of the most common types:
Client-server architecture
The most basic form of distributed architecture, a client-server architecture allows clients to request services from a central server. Examples include web browsers interacting with web servers and email clients connecting to email servers.
Peer-to-peer (P2P) architecture
In a P2P network, each node acts as a client and a server, sharing resources and responsibilities with other nodes. P2P architectures are commonly used for file-sharing networks, such as BitTorrent.
Multi-tier architecture
Sometimes referred to as “n-tier” architectures, this architecture divides an application into multiple layers or tiers, each with specific functionalities. Common tiers include presentation, business logic, and data access layers. By separating concerns, multi-tier architectures enhance scalability and maintainability.
Microservices architecture
Microservice architectures have been one of the hottest topics in architecture for the past few years. Teams build them as a collection of loosely coupled, independent software components, each responsible for a specific business capability. Engineers can develop, deploy, and scale microservices independently, offering agility, flexibility, and, if done poorly, hard-to-manage complexity.
Service-oriented architecture (SOA)
SOA applications, which gained traction in the early 2000s, are composed of reusable services that communicate with each other through standardized interfaces. By reusing services across different applications, SOA promotes interoperability and flexibility.
Event-driven architecture (EDA)
In an EDA, components often coupled with microservices communicate by producing and consuming events. EDA enables loose coupling and scalability by allowing components to react to events asynchronously.
Many of these architectural examples overlap slightly and come with their own set of advantages and tradeoffs. Depending on the application you are building, some types under the distributed architecture umbrella may make more or less sense to run with. An excellent way to understand which might be a good fit is to look at similar existing application examples. Let’s take a look at some examples in the next section.
Distributed architecture examples
Distributed system architectures are the backbone of many of today’s most successful companies and applications. A distributed system is likely deployed under the hood if it requires scale and resilience. Here are a few examples of companies that are using distributed architectures at scale:
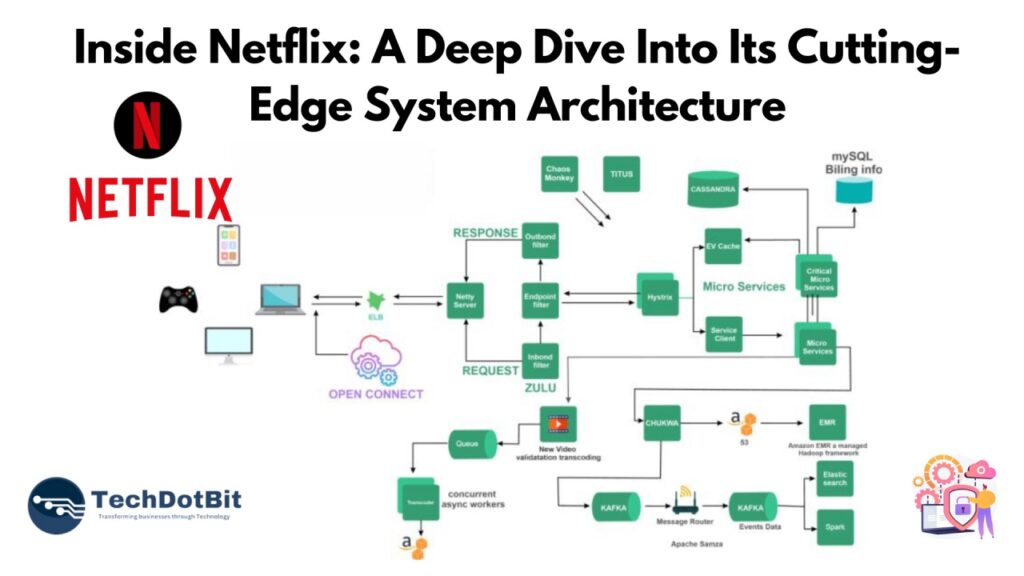
Netflix
The streaming giant utilizes a microservices architecture to deliver personalized content to millions of users worldwide. Each microservice handles a specific task, such as content recommendations, user authentication, or video streaming, allowing for independent scaling and rapid updates.
Amazon
For its massive e-commerce operations, Amazon employs a multi-tier architecture with various layers responsible for product catalogs, shopping carts, order processing, and inventory management. This distributed approach enables Amazon to handle massive traffic volumes and ensure high availability.
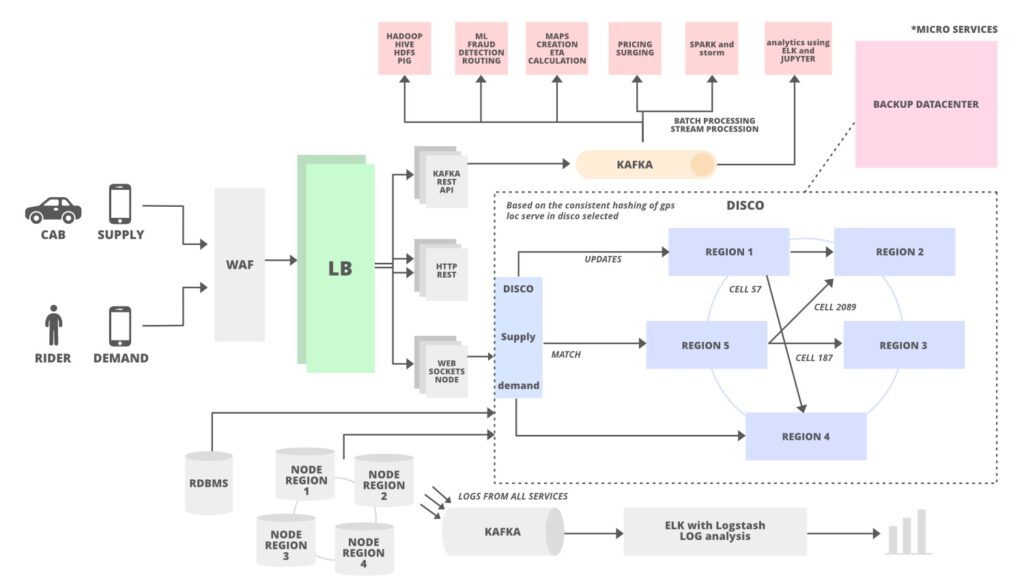
Uber
The ride-sharing app leverages a distributed system to match riders with drivers, process payments, and track rides in real-time. This architecture allows for seamless scalability and ensures a smooth user experience, even during peak hours.
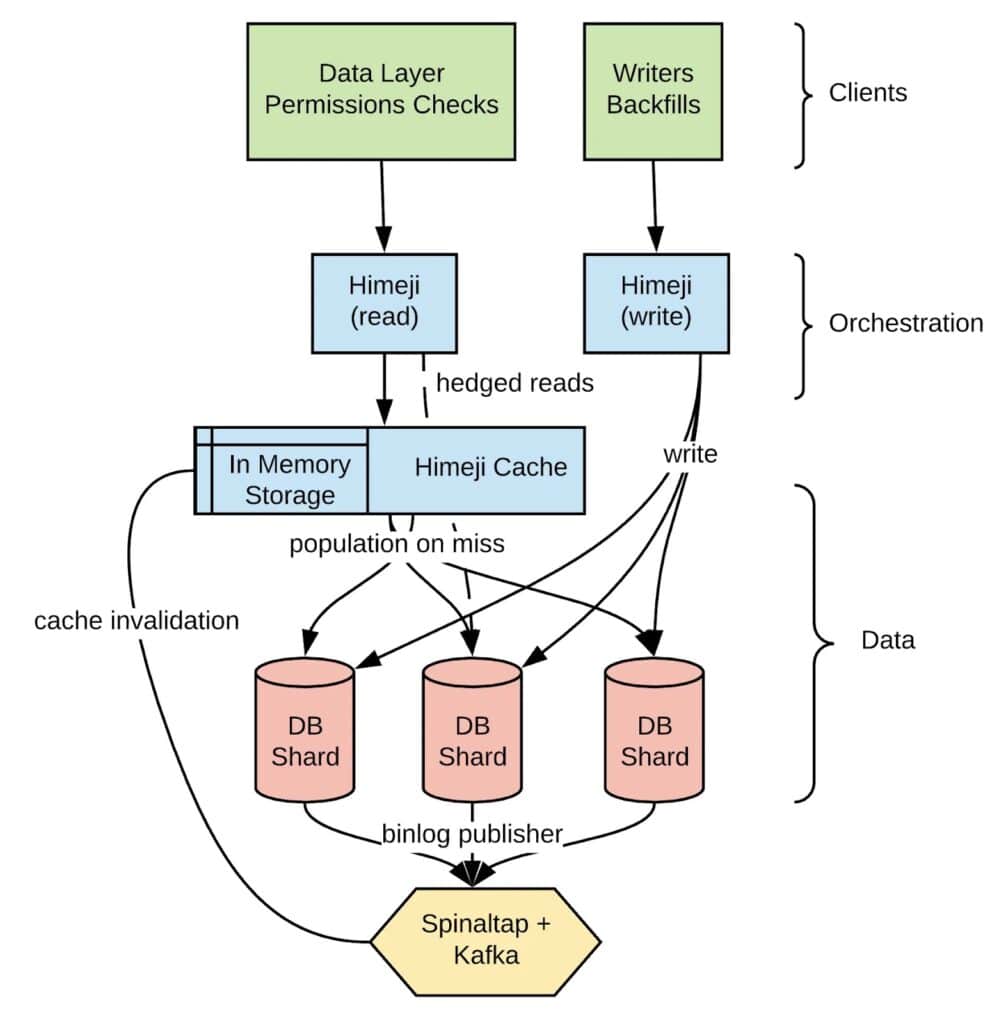
Airbnb
Airbnb’s platform utilizes distributed database systems to manage listings, bookings, and user profiles for guests and hosts worldwide. This enables efficient data retrieval regardless of the geographical distance between host and guest and ensures high availability, even under heavy traffic.
These examples show how ubiquitous distributed systems are within our app-centric and highly connected world. Without the ability to implement a distributed system, these platforms may not exist or would at least have severe growing pains as their user bases expand. Architects and developers can gain valuable insights into leveraging this paradigm to solve organizational challenges by analyzing how these companies have implemented distributed systems.
Benefits of distributed architectures
With so many large companies taking the distributed architecture approach to their applications, it’s no surprise that they offer many advantages over their centralized counterparts. Let’s look at a few highlights that distributed architectures bring to the table:
Scalability
Distributed computing architectures can be scaled horizontally by adding more nodes to the system. This allows them to handle increasing workloads and traffic without requiring costly upgrades to a single central server.
Fault tolerance and resilience
The distributed nature of these architectures provides inherent fault tolerance. If one node fails, the others can continue operating, ensuring the system remains available and responsive instead of succumbing to a single point of failure.
Performance and efficiency
Distributed architectures can achieve higher performance and efficiency than centralized systems by distributing tasks across multiple nodes and distinct services. Each service can focus on specific tasks, allowing them to be optimized for resource utilization and minimizing bottlenecks.
Modularity, flexibility, and engineering velocity
Distributed architectures are typically composed of modular components and services that can be developed, deployed, and managed independently. This modularity allows for greater flexibility and agility when tweaking functionality based on changing business requirements.
Cost-effectiveness
Components within distributed architectures can often be built using commodity hardware or cloud-based infrastructure. This is more cost-effective to scale than centralized architectures, which usually require expensive upgrades to a single server.
Geographic distribution
Distributed architectures can be deployed across multiple geographic locations, improving latency and providing redundancy in case of regional outages or disasters. This becomes increasingly easy when the distributed apps are hosted within public cloud environments with extensive regional coverage.
Data locality
Distributed architectures can improve data access times and reduce network latency by storing data closer to the users or processes that need it. A distributed database system can also allow companies to comply with data sovereignty legislation, which may require data only to be located and/or processed in the country of origin.
Depending on the project, some or all of these benefits may be applicable. Regardless, distributed architectures have become the standard for many apps because they offer more flexibility and scale faster than others. That being said, they also bring some challenges. Let’s explore them in the next section.
Challenges of distributed architectures
While distributed architectures offer the benefits we discussed in the previous section, they also present unique challenges that architects and developers must address. Here are a few critical challenges to be aware of when adopting a distributed approach.
Complexity
Due to the increased components, interactions, and potential failure points, distributed systems are inherently more complex than centralized ones. Managing this complexity requires careful planning, design, and monitoring.
Communication overhead
Nodes in a distributed system need to communicate with each other to coordinate tasks and share data. This communication, via REST APIs, gRPC, or message queues, can introduce overhead, especially at scale, and impact performance if not managed effectively.
Network latency
In addition to overhead, communication between nodes over a network introduces latency, which can impact the performance of real-time applications. This factor is not always predictable or within one’s control but should be accounted for in the system’s design and implementation.
Data consistency
Maintaining data consistency across multiple nodes can be challenging. Replicating data can introduce inconsistencies if not appropriately synchronized, and resolving conflicts can be complex. Many data platforms can be configured to handle distributed transactions and storage, but the complexity of implementing them varies.
Security
Distributed systems present a larger attack surface than centralized ones, as each node represents a potential entry point for attackers. Ensuring the security of distributed systems requires robust authentication, authorization, and encryption mechanisms to be rolled out across all components within the architecture.
Debugging and testing
Although unit testing can be more accessible, end-to-end debugging and testing of distributed systems can be more complex than centralized ones. This is due to the asynchronous nature of communication and the potential for race conditions and other timing and latency-related issues.
Deployment and management
Deploying and managing distributed systems can be complex because they require coordinating updates, monitoring multiple nodes, and handling potential failures. Many of these applications use containerization software, including tools like Docker and Kubernetes, which require specialized skills to configure and run properly.
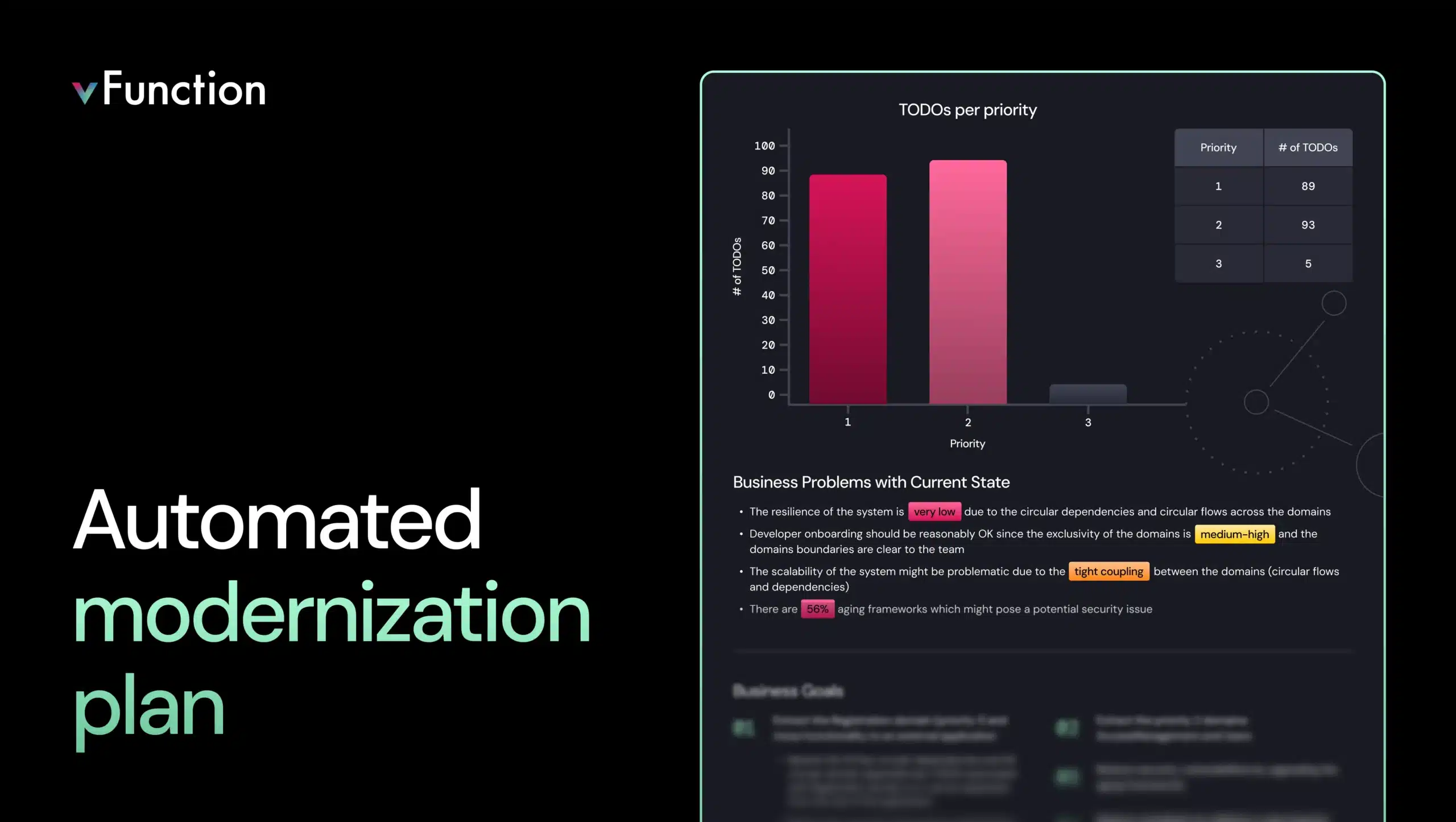
These challenges shouldn’t scare anyone off. By proactively addressing them, architects and developers can build distributed systems that are reliable, scalable, and secure despite potential issues that can arise. Many tools even exist to help manage these complexities. On the observability front, vFunction can assist in ensuring that your distributed architecture is designed and implemented for scale, resiliency, and according to architectural expectations. Let’s take a look at the specifics in the next section.
How vFunction can help with distributed architectures
vFunction offers powerful tools to aid architects and developers in designing, transforming, and maintaining distributed application architectures, helping address their potential weaknesses.
Architectural modernization
vFunction accelerates cloud-native transformation by turning monoliths into modular, distributed architectures. With runtime insights that power GenAI code assistants to modernize your architecture, you can eliminate complexity and take full advantage of advanced cloud services like serverless.
Architectural observability
Get deep insights into your application’s architecture with vFunction’s tracking of critical events, including new dependencies, domain changes, and increasing complexity over time. This visibility allows you to pinpoint areas for proactive optimization and creating modular business domains as you continue to work on the application after you’ve transformed it into distributed architecture.
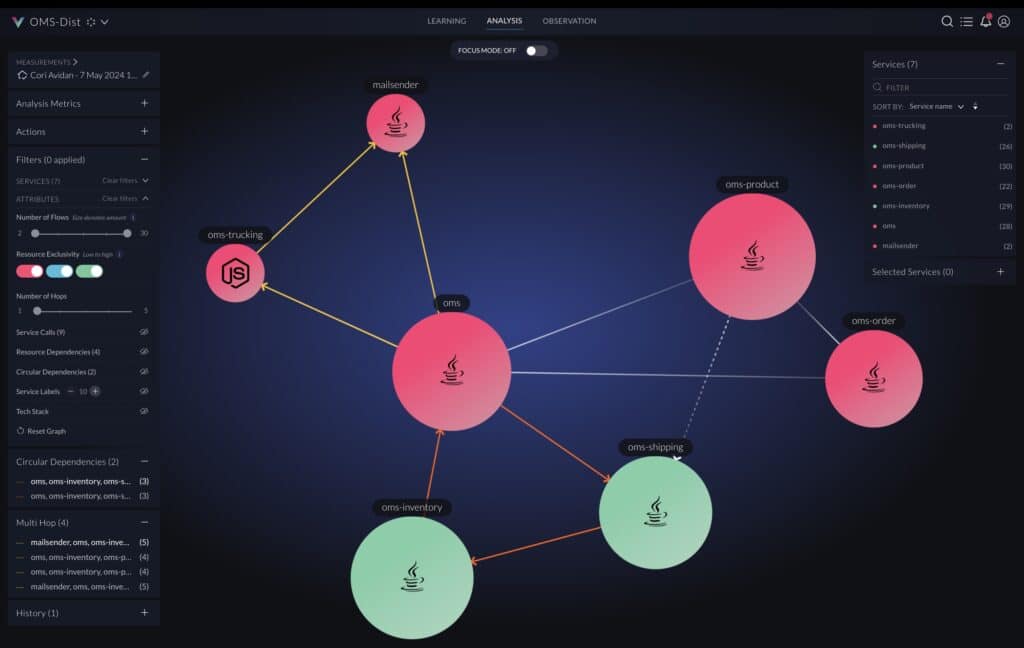
Architectural events
To avoid introducing new architectural technical debt in the cloud, vFunction architectural observability continuously tracks various architectural events. This proactive approach post-architectural-modernization is crucial for effective technical debt management. The events are associated with actionable tasks (to-do’s) to address the technical debt.
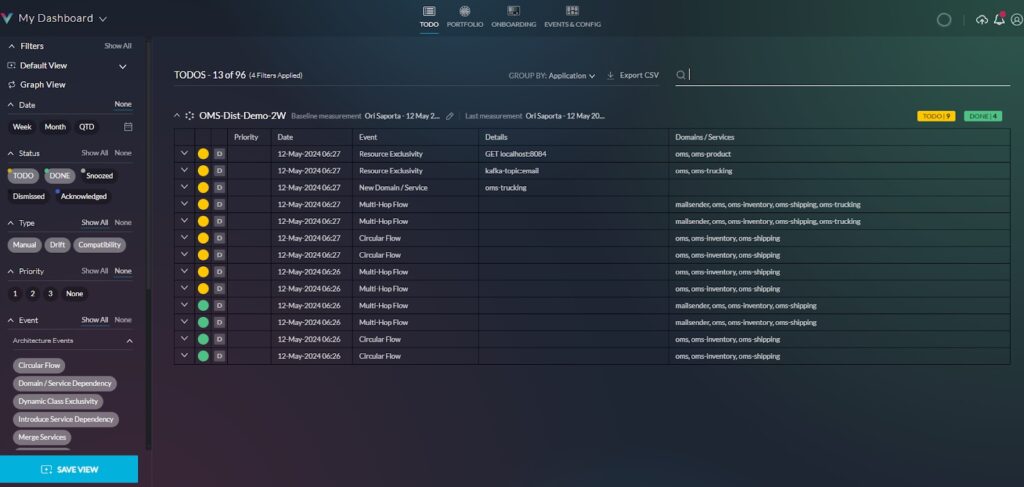
Here are examples of architectural events for distributed systems:
Event: New service added
This architectural event indicates that a new service has been detected within the application, potentially signaling unplanned expansion or architectural drift. Uncontrolled service growth can lead to increased complexity, reduced maintainability, and potential performance issues.
Event: Service dependency added
This event notifies vFunction users of newly added dependencies between services, which affect the complexity and potentially affect the application’s performance.
Event: Resource exclusivity between services
This event informs users about changes in resource exclusivity among services, which could signal potential conflicts or inefficiencies. If not managed properly, resource sharing can lead to performance issues or data integrity problems.
Conclusion
Distributed architectures are the future of software design, offering the scalability, resilience, engineering velocity, and efficiency required to meet modern demands. Whether you’re building the next big web application, developing a blockchain network, or modernizing legacy systems in the cloud, understanding how to leverage a distributed architecture is crucial.
If you want to unlock the full potential of distributed architecture and accelerate your application modernization efforts, vFunction can help. Our AI-driven architectural modernization platform simplifies the creation and maintenance of distributed systems and modernizes legacy applications.
Want to know more about how we can help your organization? Contact vFunction today and learn how we help companies build scalable, resilient, and efficient distributed systems.