In this blog post, we’ll explore all the angles of software complexity: its causes, the different ways it manifests, and the metrics used to measure it. We’ll also discuss the benefits of measuring software complexity, its challenges, and how innovative solutions like vFunction transform how organizations can manage complexity within the software development lifecycle. First, let’s take an initial go at defining software complexity in more detail.
What is software complexity?
As mentioned previously, at its core, software complexity measures how complex a software system is to understand, modify, or maintain. It’s a multi-dimensional concept that can manifest in various ways, from convoluted code structures and tangled dependencies to intricate and potentially unwarranted interactions between components. Although software projects always have inherent complexity, a good question to ask is how software becomes complex in the first place.
Why does software complexity occur?
Although it sounds negative, software complexity is often an unavoidable byproduct of creating sophisticated applications that solve real-world problems.

Source: vFunction session with Turo at Gartner Summit, Las Vegas, 2024.
A few key factors make software more complex while creating these solutions.
Increasing scale
As software systems grow in size and functionality, the number of components, interactions, and dependencies naturally increases, making the application more complex and more challenging to grasp the overall picture.
Changing requirements
Software engineering is rarely a linear process. Requirements evolve, features get added or modified, and this constant flux introduces complexity as the codebase adapts, which may support the overall direction of the application but introduce complexity.
Tight coupling
When system components are tightly interconnected and dependent on each other, changes to one component can ripple through the system. This tight coupling between components can make the application more brittle, causing unforeseen consequences and making future modifications difficult.
Lack of modularity
Typical monolithic architectures, where all components integrate tightly, are more prone to complexity than modular designs. Modular applications, such as modular monoliths and those built with a microservices architecture, are more loosely coupled and can be modified independently and more efficiently.
Technical debt
Sometimes, software engineers take shortcuts or make quick fixes to meet deadlines. This “technical debt” accumulates over time, adding to the complexity and making future changes more difficult. It can involve both code and architectural technical debt and any piece of the application design or implementation that is not optimal — adding complexity that will generally cause issues down the line.
Inadequate design
A lack of clear design principles or a failure to adhere to good design practices can lead to convoluted code structures, making them harder to understand and maintain. For example, injecting an unrelated data access layer class to read one column of a table instead of the corresponding facade layer/service layer class. Applications should follow SOLID design principles to avoid becoming complex and convoluted.
How is software complexity measured?
Measuring complexity isn’t an exact science, but several metrics and techniques provide valuable insights into a system’s intricacy. By assessing the system in various ways, you can identify all the areas where it may be considered complex. Here are some common approaches:
Cyclomatic complexity
Cyclomatic complexity measures the number of independent paths through a program’s source code. High cyclomatic complexity indicates a complex control flow, potentially making the code harder to test and understand.
Here is a simple example of how to calculate complexity. Given this code:
def example_function(x):
if x > 0:
return x
else:
return -x
To calculate cyclomatic complexity:
- Count decision points (if, else): 1
- Add 1 to the count: 1 + 1 = 2
Cyclomatic complexity = 2
Halstead complexity measures
These metrics analyze the program’s vocabulary (operators and operands) to quantify program length, volume, and difficulty. Higher values suggest increased complexity.
For this metric, given the code below, we can calculate the metric using the following equation:
def example_function(x):
return x * 2
To calculate Halstead metrics:
- Distinct operators: def, return, * (3)
- Distinct operands: example_function, x, 2 (3)
- Total operators: 3
- Total operands: 3
Program length (N) = 3 + 3 = 6
Vocabulary size (n) = 3 + 3 = 6
Volume (V) = N log2(n) = 6 log2(6) ≈ 15.51
Maintainability index
This composite metric combines various factors, such as cyclomatic complexity, Halstead measures, and code size, to provide a single score indicating how maintainable the code is.
As an example, let’s calculate the maintainability index using the previous Halstead Volume (V ≈ 15.51), Cyclomatic Complexity (CC = 1), and Lines of Code (LOC = 3):
MI=171−5.2×log2(15.51)−0.23×1−16.2×log2(3)
MI≈171−20.54−0.23−25.58
MI≈124.65
Cognitive complexity
This newer metric attempts to measure how difficult it is for a human to understand the code by analyzing factors like nesting levels, control flow structures, and the cognitive load imposed by different language constructs.
We can calculate the cognitive complexity using the following formula based on the code example below.
def example_function(x):
if x > 0:
for i in range(x):
print(i)
To calculate cognitive complexity:
- if x > 0: adds 1 point
- for i in range(x): within the if adds 1 point (nested)
Total cognitive complexity = 1 + 1 = 2
Dependency analysis
This technique is less of a mathematical equation than the others. It visualizes the relationships between different system components, highlighting dependencies and potential areas of high coupling. As dependencies grow, application complexity increases.
Abstract Syntax Tree (AST) analysis
By analyzing the AST, which represents the code’s structure, developers can identify complex patterns, nesting levels, and potential refactoring opportunities. For code that looks like this:
def example_function(x):
return x * 2
The AST analysis would highlight the code’s structure and allow for an easy-to-understand assessment of its structures and operations within the code.
FunctionDef
└── arguments(args=[x])
└── Return(value=BinOp(left=x, op=Mult, right=2))
Code reviews and expert judgment
Lastly, experienced developers can often identify complex code areas through manual inspection and code reviews when assessing code complexity. Their expertise can complement automated metrics and provide valuable insights.
Object-oriented design metrics
In addition to the general software complexity metrics mentioned above, developers have specifically designed several metrics for object-oriented (OO) designs. These include:
- Weighted Methods per Class (WMC): This metric measures a class’s complexity based on the number and complexity of its methods. A higher WMC indicates a more complex class with a greater potential for errors and maintenance challenges.
- Depth of Inheritance Tree (DIT): This metric measures how far down a class is in the inheritance hierarchy. A deeper inheritance tree suggests increased complexity due to the potential for inheriting unwanted behavior and the need to understand a larger hierarchy of classes.
- Number of Children (NOC): This metric counts the immediate class subclasses. A higher NOC indicates that the class is likely more complex because its responsibilities are spread across multiple subclasses, potentially leading to unexpected code reuse and maintainability issues.
- Coupling Between Objects (CBO): This metric measures the number of other classes to which a class is coupled (i.e., how many other classes it depends on). High coupling can make a class more difficult to understand, test, and modify in isolation, as changes can have ripple effects throughout the system.
- Response For a Class (RFC): This metric measures the number of methods developers can execute in response to a message received by a class object. A higher RFC indicates a class with more complex behavior and potential interactions with other classes.
- Lack of Cohesion in Methods (LCOM): This metric assesses the degree to which methods within a class are related. A higher LCOM suggests that a class lacks cohesion, meaning its methods are not focused on a single responsibility. This could potentially indicate a god class that is harder to understand and maintain.
While no single metric in this list is perfect, combining them is often beneficial for a comprehensive view of software complexity. Using these metrics as tools, teams should combine them with a thorough understanding of the software’s architecture, design, and requirements. By taking a holistic look at the software, a more accurate assessment of complexity and if it is within a necessary level is more straightforward to determine. This is even easier to decide once you understand the different types of software complexity, a subject we will look at next.
Types of software complexities
As we can see from the metrics discussed above, software complexity can manifest in various forms, each posing unique challenges to developers regarding the maintainability and scalability of these applications. Here are a few ways to categorize software complexity.
Essential complexity
This type of complexity is inherent to the problem the software is trying to solve. It arises from the complexity within the problem domain, such as data complexity and the algorithms required to achieve the functionality needed by the application. Generally unavoidable, essential complexity cannot be eliminated but managed through careful design and abstraction.
Accidental complexity
This type of complexity is introduced by the tools, technologies, and implementation choices used during development. It can stem from overly complex frameworks, writing convoluted code, or tightly coupling components. Engineers can reduce or eliminate accidental complexity by refactoring with better design practices and more straightforward solutions. For example, in a 3-tier architecture (facade layer, business logic layer, and data access layer), move any data access logic from the business logic layer or facade layer to the data access layer, etc.
Cognitive complexity
This refers to the mental effort required to understand and reason about the implementation within the code. Some common factors, such as nested loops, deeply nested conditionals, complex data structures, and a lack of clear naming conventions, indicate increased cognitive complexity. Engineers can tackle this complexity by simplifying control flow, using meaningful names, and breaking down complex logic into smaller, more manageable pieces. Following coding best practices and standards is one way to dial down this complexity.
Structural complexity
This relates to the software system’s architecture and organization. It can manifest as tangled dependencies between components, monolithic designs involving overly normalized data models, or a lack of modularity.
Addressing structural complexity often involves:
- Refactoring code and architecture towards a more modular approach
- Applying appropriate design patterns
- Minimizing unnecessary dependencies
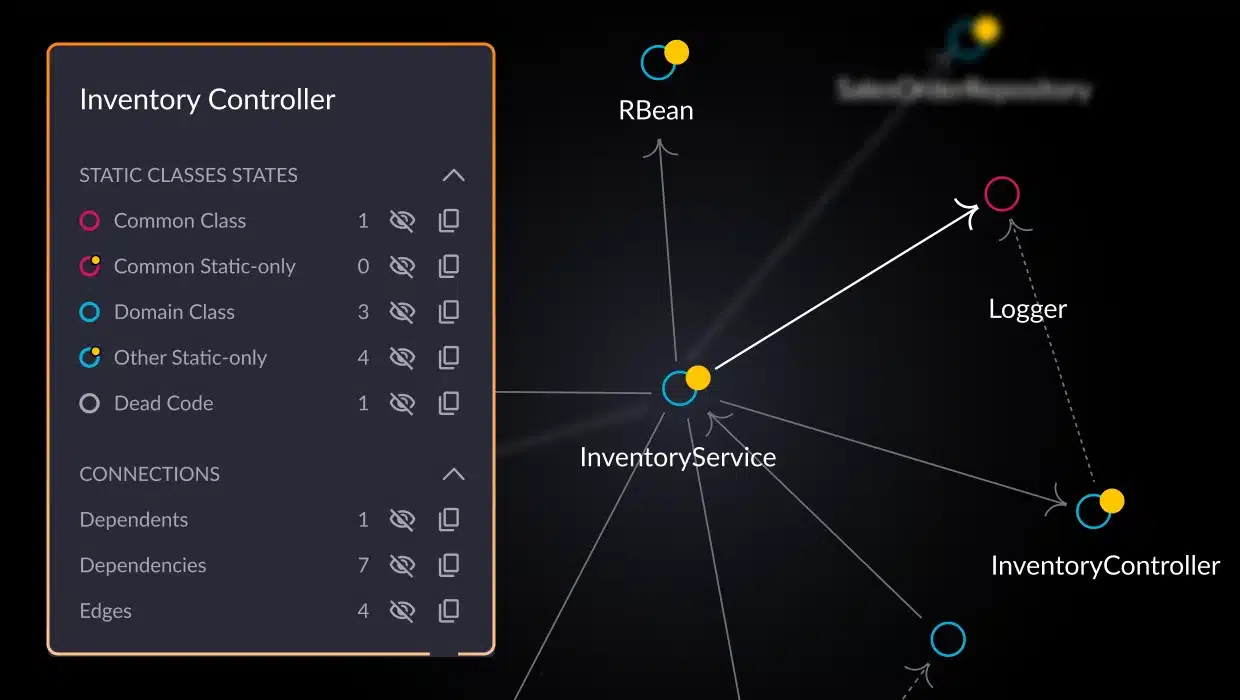
Temporal complexity
Lastly, this refers to the complexity arising from the interactions and dependencies between software components over time. Factors like asynchronous operations, concurrent processes, and real-time interactions can cause it. Managing temporal complexity often requires careful synchronization mechanisms, easy-to-follow communication between components, and robust error handling.
By recognizing the different types of complexity within their software, developers can tailor their strategies for managing and mitigating each one. Ultimately, understanding the different facets of software complexity allows application teams to make informed decisions and create software that serves a need and is also maintainable.
Why utilize software complexity metrics?
While understanding how software complexity manifests within a system is one thing, and metrics to calculate complexity might seem like abstract numbers, this understanding and analysis offer tangible benefits in the software development lifecycle. Let’s look at some areas where complexity metrics can help within the SDLC.
Early warning system
Metrics like cyclomatic and cognitive complexity can act as an early warning system, flagging areas of code that are becoming increasingly complex and potentially difficult to maintain. Addressing these issues early can prevent them from escalating into significant problems and developer confusion later on.
Prioritizing refactoring efforts
Complexity metrics help identify the most complex parts of a system, allowing development teams to prioritize their refactoring efforts. By focusing on the areas most likely to cause issues, they can make the most significant improvements in code quality and maintainability while leaving less concerning parts of the code.
Objective assessment of code quality
Complexity metrics provide an objective way to assess code quality. They remove the subjectivity from discussions about code complexity and allow developers to focus on measurable data when making decisions about refactoring or design improvements.
Estimating effort and risk
High complexity often translates to increased effort and risk in software development. By using complexity metrics, leaders, such as a technical lead or an architect, can better estimate the time and resources required to modify or maintain specific parts of the codebase without parsing through every line of code themselves. This allows for more realistic estimations, planning, and resource allocation.
Enforcing coding standards
Complexity metrics can be integrated into coding standards and automated checks, ensuring that new code adheres to acceptable levels of complexity. This helps prevent the accumulation of technical debt and promotes a culture of writing clean, maintainable code.
Monitoring technical debt
Regularly tracking complexity metrics can help monitor the accumulation of technical debt over time.By identifying trends and patterns, development teams can proactively address technical debt and, even more importantly, architectural, technical debt built into the software construction before it becomes unmanageable. Tracking the evolution of the application over time can also monitor technical debt and inform developers and architects of areas to watch as development proceeds.
Improving communication
Complexity metrics provide a common language for discussing code quality and maintainability. They facilitate communication between developers, managers, and stakeholders, enabling everyone to understand the implications of complexity and make informed decisions.
Incorporating complexity metrics into the software development process empowers teams to make data-driven decisions and prioritize their efforts. This focus on application resiliency results in a team that can create software that’s not only functional but also adaptable, and easy to maintain in the long run.
Benefits of software complexity analysis
As we saw above, complexity metrics offer developers and software engineers advantages. But what about the larger subject of investing time and effort in analyzing software complexity? Using software complexity analysis as part of the SDLC also brings many advantages to the software business in general, improving multiple areas. Here are a few benefits organizations see when they include software complexity analysis in their development cycles.
Improved maintainability
By understanding a system’s complexity, developers can identify areas that are difficult to modify or understand. This allows them to proactively refactor and simplify the code, making it easier to maintain and reducing the risk of introducing bugs during future changes and refactors.
Reduced technical debt
Complexity analysis helps pinpoint areas where technical debt has accumulated, such as overly complex code or tightly coupled components. By addressing these issues, teams can gradually reduce their technical debt and, more accurately, improve the overall health of their codebase.
Enhanced reliability
Complex code is often more prone to errors and bugs. By simplifying and refactoring complex areas, developers can quickly improve their ability to debug issues. This increases the software’s reliability, leading to fewer crashes, failures, and unexpected behavior.
Increased agility
When code is easier to understand and modify, development teams can respond more quickly to changing requirements and market demands. Adding new features quickly and confidently can be a significant advantage in today’s fast-paced environment.
Cost savings
Complex code is expensive to maintain and requires more time and effort to understand, modify, and debug. By simplifying their codebase, organizations can reduce development costs and allocate resources more efficiently and accurately.
Improved collaboration
Complexity analysis can foster collaboration between developers, engineers, and architects as they work together to understand and simplify complex parts of the system. Just like code reviews can add to a more robust codebase and application, complexity analysis can lead to a more cohesive team and a stronger sense of shared ownership of the codebase.
Risk mitigation
Lastly, complex code and unnecessary resource dependencies carry inherent risks, such as the potential for unforeseen consequences when refactoring, fixing, or adding to the application. By proactively managing complexity, teams can mitigate these risks and reduce the likelihood of an error or failure occurring from a change or addition.
Ultimately, software complexity analysis is an investment in the future of the application you are building. By adding tools and manual processes to gauge the complexity of your system, you can ensure that factors such as technical debt accumulation don’t hinder future opportunities your organization may encounter. That said, finding complexity isn’t always cut and dry. Next, we will look at some of the challenges in identifying complexity within an application.
Challenges in finding software complexity
While the benefits of addressing software complexity are evident from our above analysis, identifying and measuring it can present several challenges. Here are a few areas that can make assessing software complexity difficult.
Hidden complexity
Not all complexity is immediately apparent. Some complexity hides beneath the surface, such as tangled dependencies, implicit assumptions, or poorly written and documented code. Uncovering this hidden complexity requires careful analysis, code reviews, and a deep understanding of the system’s architecture.
Subjectivity
What one developer considers complex might seem straightforward to another. This subjectivity can make it difficult to reach a consensus on which parts of the codebase need the most attention. Objective metrics and establishing clear criteria for complexity can help mitigate this issue.
Dynamic nature of software
Software systems are constantly evolving. Teams add new features, change requirements, and refactor code. This dynamic nature means complexity can shift and evolve, requiring ongoing analysis and monitoring to stay on top since it can quickly fade into the background.
Integration with legacy systems
Many organizations have legacy systems that are inherently complex due to their age, outdated technologies and practices, or lack of documentation. Integrating new software with these legacy systems can introduce additional complexity and create challenges in managing, maintaining, and scaling the system.
Lack of tools and expertise
Not all development teams can access sophisticated tools, like vFunction, to analyze software complexity. Additionally, there might be a lack of expertise in interpreting complexity metrics and translating them into actionable insights for teams to tackle proactively. These factors can hinder efforts to manage complexity effectively.
Despite these challenges, addressing software complexity is essential for the long-term success of any software project. By acknowledging these hurdles and adopting a proactive approach to complexity analysis, a development team can overcome these obstacles and create robust and maintainable software.
How vFunction can help with software complexity
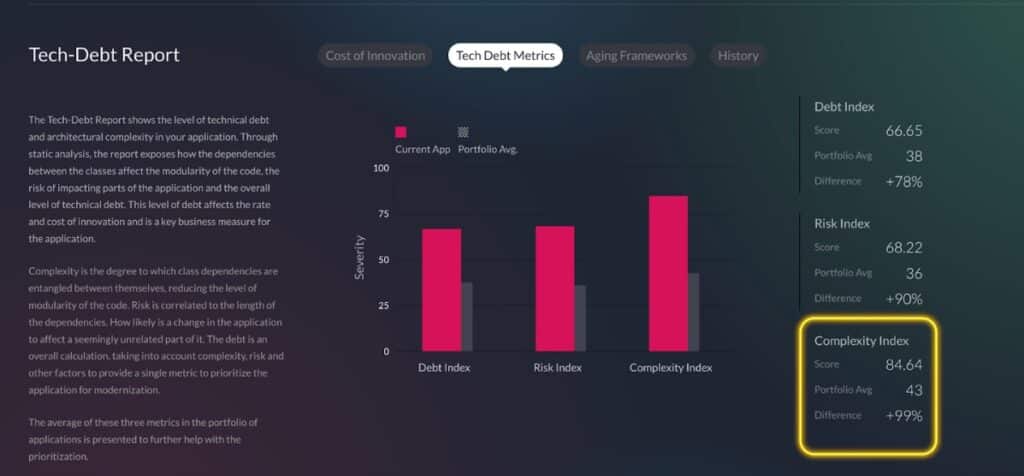
Managing software complexity on a large scale with legacy applications can feel like an uphill battle. vFunction is transforming how teams approach and tackle this problem. By using vFunction to assess an application’s complexity, vFunction will return a complexity score showing the main factors that contribute to the application’s complexity.
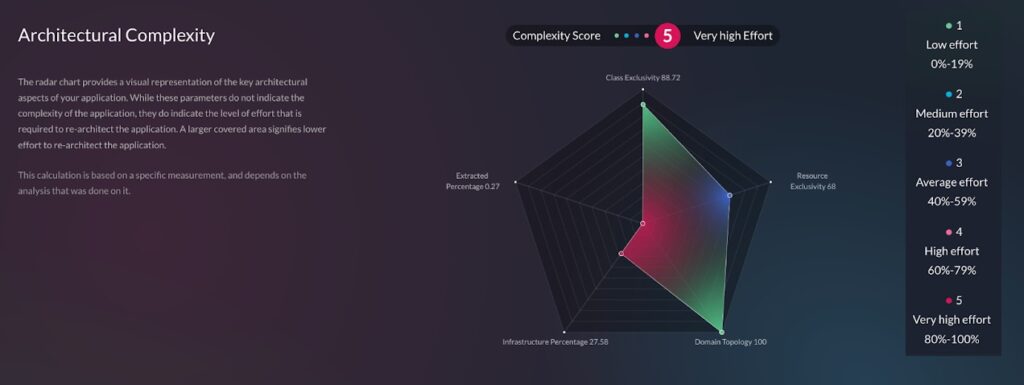
Also, as part of this report, vFunction will give a more detailed look at the factors in the score through a score breakdown. This includes more in-depth highlights of how vFunction calculates the complexity and technical debt within the application.

When it comes to software complexity, vFunction helps developers and architects get a handle on complexity within their platform in the following ways:
- Architectural observability: vFunction provides deep visibility into complex application architectures, uncovering hidden dependencies and identifying areas of high coupling. This insight is crucial for understanding an application’s true complexity.
- Static and dynamic complexity identification: Two classes can have the same static complexity in terms of size and the number of dependencies. However, their runtime complexities can be vastly different, i.e., methods of one class could be used in more flows in the system than the other. vFunction combines static and dynamic complexity to provide the complete picture.
- AI-powered decomposition: Leveraging advanced AI algorithms, vFunction analyzes the application’s structure and automatically identifies potential areas for modularization. This significantly reduces the manual effort required to analyze and plan the decomposition of monolithic applications into manageable microservices.
- Technical debt reduction: By identifying and quantifying technical debt, vFunction helps teams prioritize their refactoring efforts and systematically reduce the accumulated complexity in their applications.
- Continuous modernization: vFunction supports a continuous modernization approach, allowing teams to observe and incrementally improve their applications without disrupting ongoing operations. This minimizes the risk associated with large-scale refactoring projects.
Conclusion
Software complexity is inevitable in building modern applications, but it doesn’t have to be insurmountable. By understanding the different types of complexity, utilizing metrics to measure and track it, and implementing strategies to mitigate it, development teams can create software that sustainably delivers the required functionality. Try vFunction’s architectural observability platform today to get accurate insights on measuring and managing complexity within your applications.