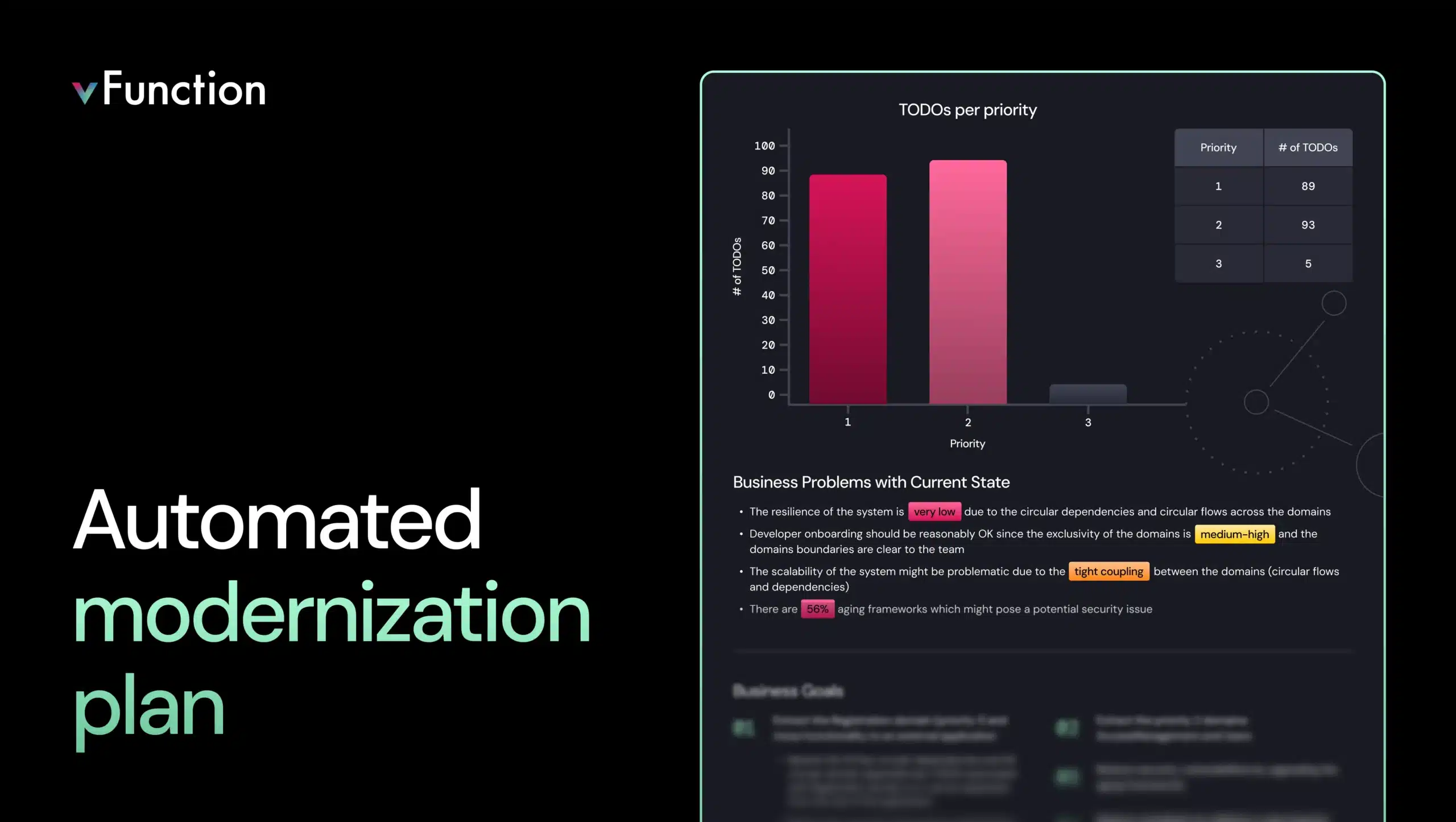
Modernizing complex applications requires more than tools and effort. It requires a clear application If your team made the leap from a monolithic application to microservices but deployments still require the entire organization to coordinate, you might be dealing with a distributed monolith. It’s one of the most common outcomes of a microservices migration, and more teams are running into it than you’d expect.
On paper, the software system looks modern. Separate services, independent repositories, maybe a service mesh. But in practice, nothing moves independently. A change to one service still triggers updates across other services. Releases still require lockstep coordination.
So the system ends up in an in-between state: distributed in form, but still tightly coupled in behavior. The autonomy that microservices promised never showed up.
Whether you’re coming from a traditional monolithic architecture or an older service-oriented architecture, the result is the same: the worst of both worlds. And understanding how it forms is the first step toward fixing it.
What is a distributed monolith?
A distributed monolith is a system that’s structured as a collection of separate services but behaves like a tightly coupled monolith.
The services are physically distributed and may run in different containers, communicate over APIs, and live in separate repos, but they can’t be developed, tested, or deployed independently.
The system appears to be a microservices architecture but retains the tight coupling of a monolith. You’ll often see:
- Shared databases,
- Synchronous communication between different services
- Shared libraries that force them to change in tandem
- Releases that require multiple services to deploy together.
A true monolithic application bundles everything into a single deployable unit, often with the user interface, business logic, and data access layer all living in a single codebase.
A true microservices architecture decouples these into loosely coupled services that can evolve independently.
The distributed monolith sits in a painful, yet common, middle ground and is referred to as an “antipattern.”
Distributed monolith vs. microservices architecture
At a glance, both distributed monoliths and microservices look similar.
The difference is in how those services are coupled and whether they can actually function on their own.
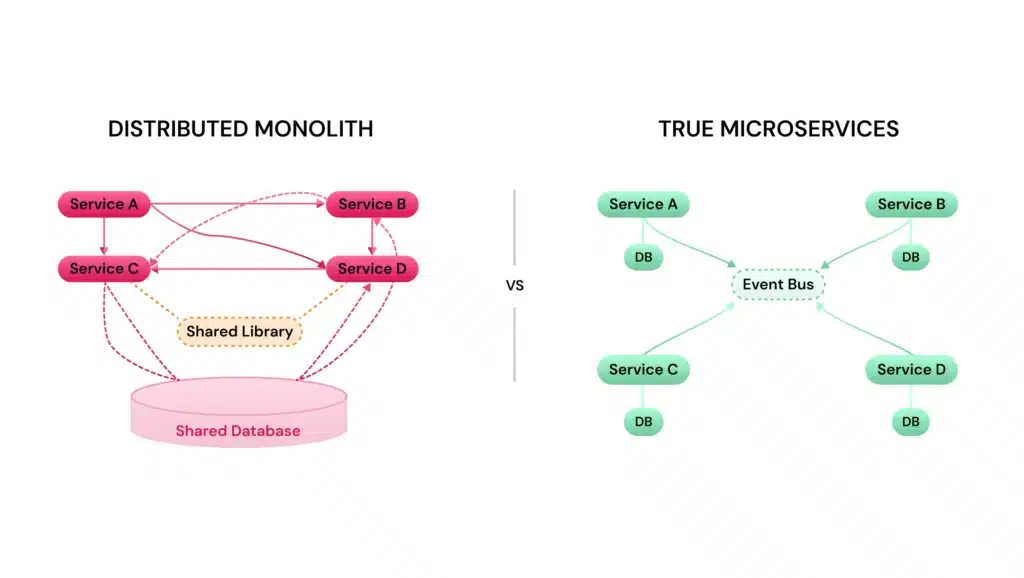
In a well-designed microservices architecture:
- Each service owns its own data, defines its own API contracts
- Services deploy independently without the need to coordinate releases
- Failures are isolated; the whole system degrades gracefully rather than failing across the board.
In a distributed monolith, those boundaries blur:
- Data is shared across services, i.e., two services share a database, so a database schema change in one can break the other
- APIs are tightly coupled and often synchronous
- Deployments require coordination, i.e., shared libraries and models that force coordinated updates
- Failures cascade across the system
Microservices aren’t defined by how many services you have; they’re defined by how independently those services can evolve.
A simple litmus test: if you can’t deploy independently for Service A without also deploying Service B, and you can’t test Service B without Service C running, you’re not operating microservices. You’re operating a distributed monolith.
| Characteristic | Microservices | Distributed monolith |
| Deployment | Independent per service | Coordinated across services |
| Data ownership | Each service owns its data | Shared databases |
| Communication | Async, event-driven preferred | Synchronous call chains |
| Failure isolation | Graceful degradation | Cascading failures |
| Team autonomy | High: teams own their service end-to-end | Low: cross-team coordination required |
| Testing | Services testable in isolation | Integration testing is required for most changes |
What causes a distributed monolith to emerge?
Distributed monoliths are a common yet unexpected antipattern, often emerging unintentionally during the shift from monoliths to microservices. They emerge gradually as teams migrate toward microservices without fully decoupling the architecture.
One of the most common causes is a “lift and shift” decomposition. Instead of decomposing service boundaries around business domains, teams split a monolith along existing code boundaries. This is a pattern explored in detail inmonoliths to microservices best practices. Teams create services that mirror the monolith’s internal structure and inherit its coupling. A product catalog service, for example, might still depend on the same shared tables and function calls as the order management service, even though they’re now separate service deployments.
Shared databases are another frequent driver. When multiple services read from and write to the same tables, a schema change can ripple across the system. What looked like an isolated update turns into a coordinated migration.
Tight API coupling plays a role, too. When services communicate through synchronous, point-to-point calls, especially when those calls chain together, a failure or slowdown in one service cascades through the entire request path. That kind of runtime dependency eliminates any real independence between services.
And finally, shared libraries and data models. If multiple services depend on a common library for serialization, validation, or domain logic, any update to that library forces all dependent services to rebuild and redeploy. The shared source code quietly becomes a monolith inside the distributed system.
Together, these decisions recreate the monolith in a distributed form.
Why distributed monoliths happen in modern systems
The technical causes are clear. But the pattern keeps showing up, even among experienced engineering teams.
Part of it is organizational. Conway’s Law tells us that systems reflect the communication structures of the teams that build them. If development teams don’t align with service boundaries, old patterns carry into the new architecture. You can decompose the code, but if the same group of people still coordinates every release, the coupling hasn’t changed; it’s just moved to a different layer.
There’s also a tendency to treat a microservices migration as an infrastructure problem. Containerize the app, deploy it on Kubernetes, set up an API gateway, and the architecture will sort itself out. A .NET Core application originally built around a Model View Controller pattern, for example, doesn’t become loosely coupled just because you containerize each controller. Without deliberately rethinking domain boundaries, data ownership, and communication patterns, the underlying coupling survives the migration.
Time pressure doesn’t help either. When modernization efforts are driven by deadlines (a cloud migration, a compliance requirement, a platform reaching end of life), teams take shortcuts. Temporary decisions become permanent under deadlines.
In many cases, the root issue is that the existing system wasn’t well understood before decomposition began. Without understanding runtime dependencies, teams define boundaries based on assumptions.
Key characteristics of a distributed monolith
If you’re trying to figure out whether your system has drifted into distributed monolith territory, a few patterns show up consistently.
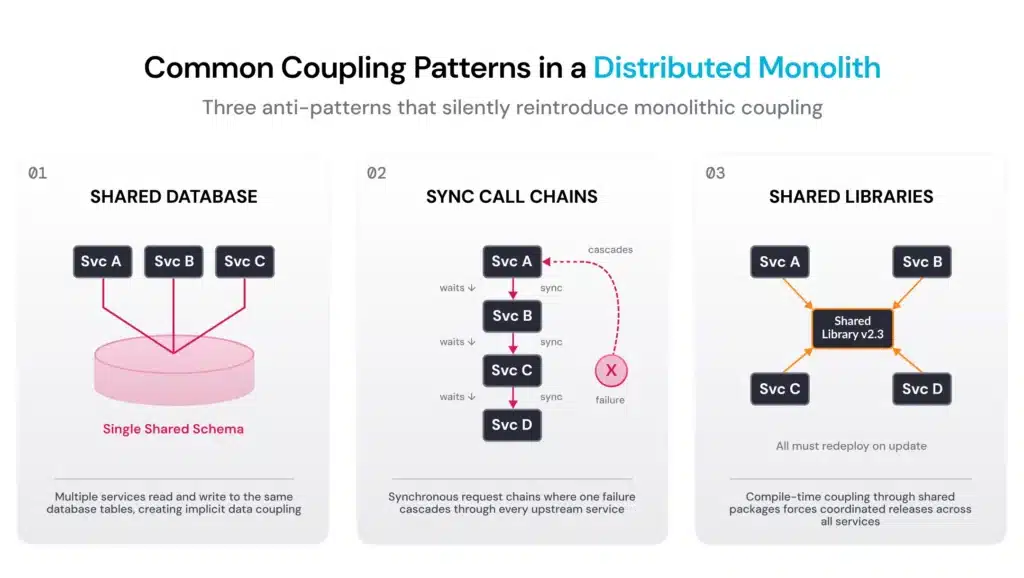
Shared persistent state: Multiple services access the same data, preventing independent evolution.
Excessive synchronous communication: If a single user request triggers a sequence of synchronous calls across three, four, or five services, the system’s availability becomes a function of every service in that chain. One slow or unavailable service blocks the entire application.
Coordinated deployments: If a change to one service requires updating, testing, and deploying other services simultaneously, those services aren’t independent in any real sense.
Shared code and libraries: A common utils package or a shared domain model might seem convenient, but it introduces a compile-time dependency that forces coordinated releases. Lack of fault isolation: Error handling should be self-contained within each service. In a distributed monolith, failures cascade because the services are too intertwined to degrade independently.
Common signs your system is a distributed monolith
Beyond the architectural characteristics, distributed monoliths are evident in your day-to-day work.
Releases need cross-team coordination. If shipping a feature requires multiple teams to coordinate timing and order, the system isn’t delivering on independent deployability.
You can’t run a service locally without spinning up half the system. When local development requires a sprawling Docker Compose file to launch dozens of dependent services, the boundaries between services aren’t clear.
A single service change breaks integration tests across the board; the coupling between services is tighter than the architecture diagram suggests.
Incident response spans multiple services. When debugging means tracing requests across multiple services and teams, the blast radius of failures isn’t being contained.
You’re not shipping faster. One of the core benefits of building microservices is the ability to ship individual services frequently and independently. If your deployment cadence hasn’t improved, it’s worth questioning whether the architecture is delivering the expected independence.
Distributed monolith anti-patterns
Several recurring anti-patterns either cause or reinforce the distributed monolith. Catching them early helps teams correct course before the coupling gets baked in.
- Shared database anti-pattern
Multiple services that read from and write to the same schema create implicit contracts among them. This is also one of the biggest barriers to extracting clean, independently deployable domains, something we see frequently when working with teams modernizing complex applications. - Synchronous chain anti-pattern
Shows up when services rely on real-time, synchronous calls to fulfill requests instead of using a message broker or event-driven patterns. The system’s latency and availability are dictated by the slowest or least reliable service in the chain. Any failure cascades upstream. - The mega-shared-library anti-pattern
Common functionality gets extracted into shared packages that multiple services depend on. Code reuse introduces coupling and forces services to change together. - The “distributed big ball of mud” anti-pattern
Service responsibilities overlap, APIs get bloated, and no single person or team is sure which service owns what. The architecture drifts into a state that’s harder to manage than the original monolith, accruing architectural debt faster than the monolith ever did. What makes more sense is to define logically separate domains from the start and enforce those boundaries as the system evolves.
The orchestration-heavy anti-pattern
A single service controls flow across multiple services, creating a bottleneck and a single point of failure. It also limits vertical scaling options because the orchestrator itself becomes the blocker, regardless of how independently downstream services scale.
Strategies to break a distributed monolith
Fixing a distributed monolith is about incrementally introducing the boundaries and decoupling that should have been there from the start.
Start with architectural analysis and visibility. Before changing anything, you need to understand how your system actually behaves at runtime, not what the architecture diagrams show. Map the dependencies. Understand the call patterns. Identify which services are truly coupled and where the real boundaries should be. Without this visibility, you’re running blind, which is how the distributed monolith formed in the first place.
Decompose around business domains, not technical layers. Services should align with bounded contexts from domain-driven design. Each should represent a meaningful business domain with its own data, logic, and lifecycle. That’s different from splitting a monolith along technical lines like “the data access layer” or “the API layer,” which tends to replicate the existing coupling rather than resolve it. For example, a product catalog should be its own independent service with its own data store, not a thin layer on top of a shared database.
Decouple data ownership. Each service should own its own data. This might mean migrating from a shared database to per-service stores and event-driven updates. The trade-offs here are real (data duplication and increased complexity in syncing), but the alternative is database coupling, which prevents independent deployments.
Shift from synchronous to asynchronous communication. Replace synchronous call chains with event-driven messaging through a message broker, or use the pub/sub pattern to cut runtime coupling. Move from chained calls to event-driven messaging. Services publish events, others react, and there’s a need for services to stay in sync.
Establish clear API contracts. Services should communicate through well-defined, versioned APIs. Contract testing, in which producers and consumers independently verify compatibility, catches breaking changes without requiring full integration test suites.
Eliminate shared libraries where possible. If shared code is necessary, keep it thin and stable. In many cases, it makes more sense to let each service implement common functionality independently, even if that means some duplication. Loosely coupled modules that duplicate a utility function are far easier to manage than tightly coupled services that share one.
Approach incrementally. Don’t try to untangle everything at once. Identify the highest-value targets, usually the services that change most frequently or the dependencies causing the most deployment friction, and start there.
How vFunction helps with distributed monoliths
Untangling a distributed monolith requires deep visibility into how your application actually behaves in production. That’s harder than it sounds. In large, complex codebases, coupling isn’t visible in the source code alone. It shows up in runtime behavior: unexpected service calls, shared resources, and circular flows.
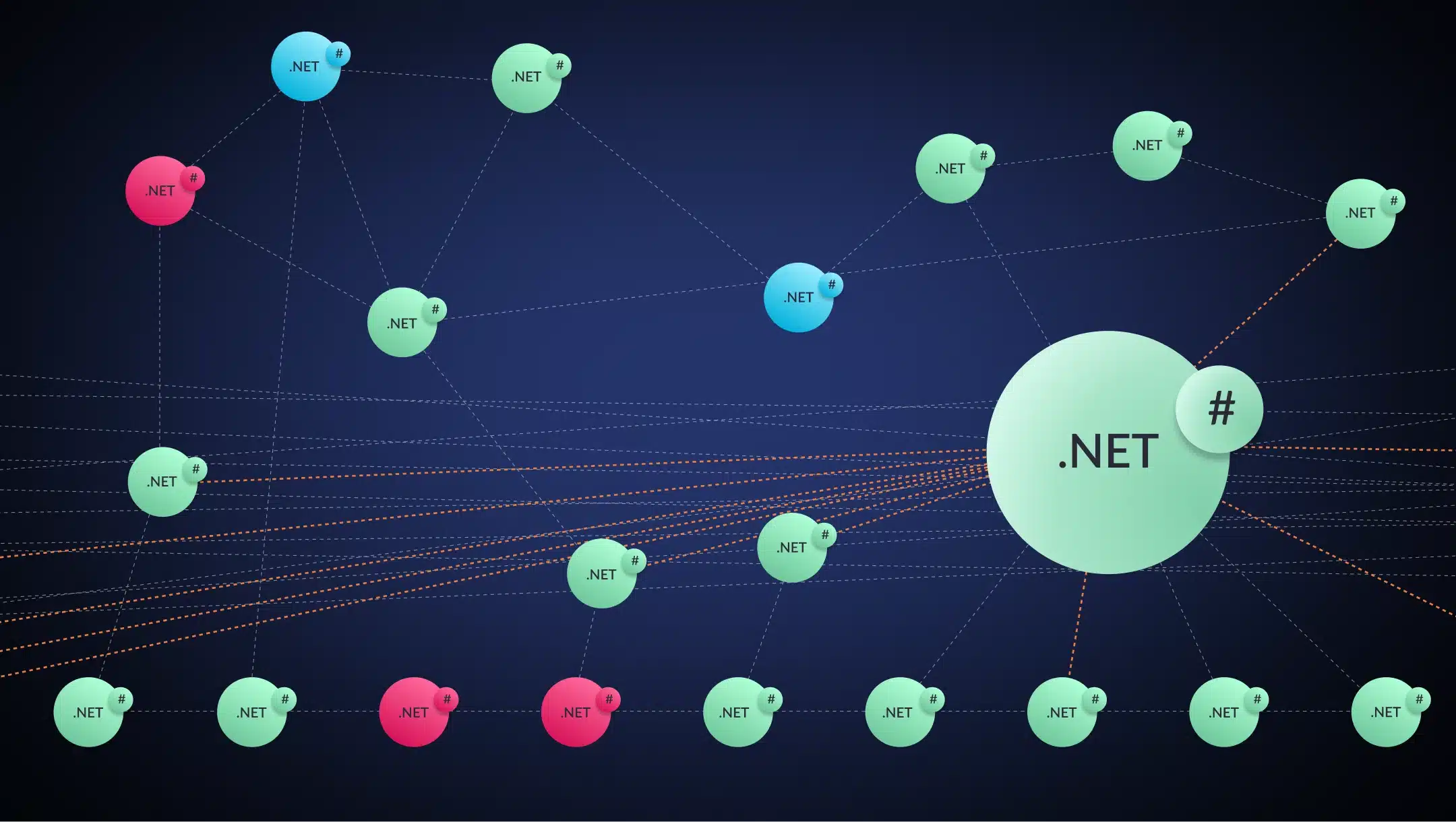
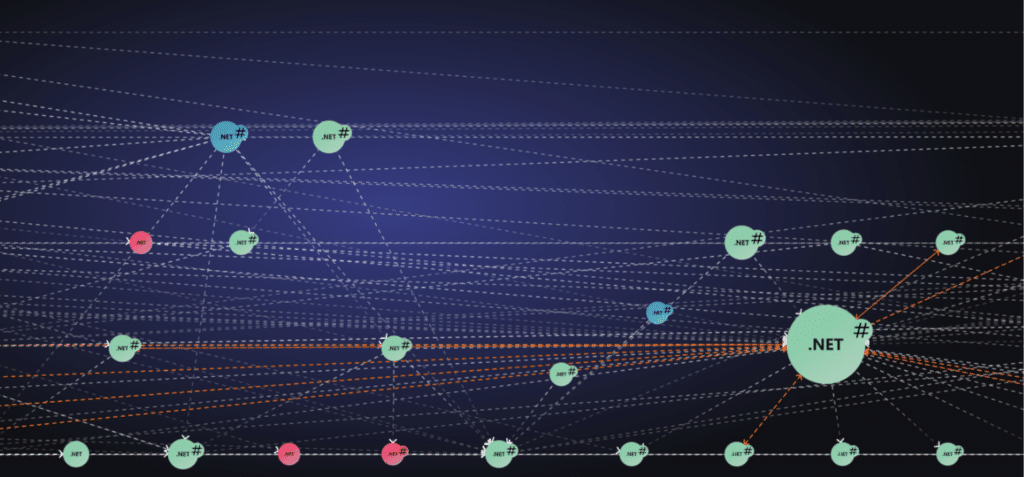
Below is a screenshot from vFunction capturing the services and calls of a distributed monolith. Each sphere represents a service. Each dotted arrow represents a runtime call between services (i.e., service calls).
The visualization surfaces a few important signals:
- Color = resource exclusivity.
Red indicates low exclusivity: resources are heavily shared across services
Blue indicates moderate exclusivity
Green indicates high exclusivity: resources are mostly owned and used by a single service.
In other words, how much of a service’s resources are used exclusively by the service versus shared across others. The more a service shares its resources, the harder it becomes to separate cleanly.
Resources are operating system-managed entities that the application uses to interact with its environment, such as database connections and tables, communication channels, and messaging services. - Size = flow volume.
Larger spheres represent services with more runtime flows passing through them. - Dashed lines with arrows between the services (spheres) = cross-service calls. In the screenshot below, we see a dense, crisscrossing mesh of arrows showing how tightly these services depend on one another.
As seen in the example, there are many calls between services and between red and blue services, which is indicative of a distributed monolith.
The orange dotted arrows indicate circular flows across services, meaning flows that include calls from one service to another and back (potentially via other services).
Here is a simple circular flow from the above example:
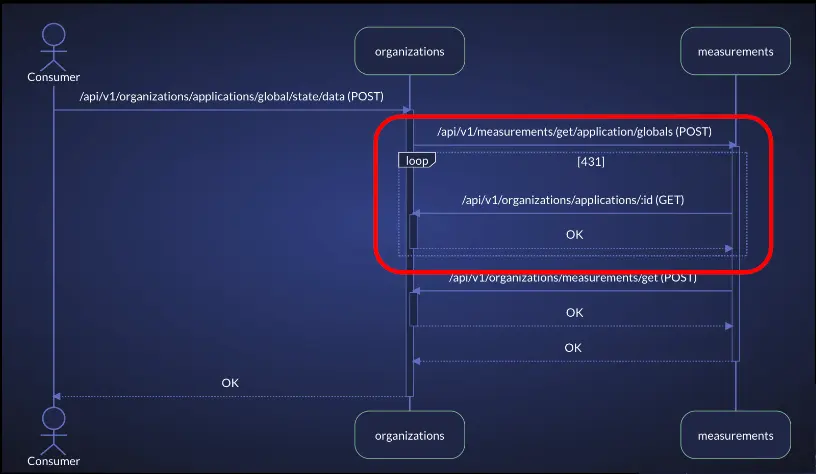
In addition to circular flows, vFunction detects and visualizes many types of issues, such as:
- Flows that traverse a large number of services before completing can create:
- High latency
- Increased failure points
- Difficulty tracing root causes
- Services that handle far more runtime activity than others. These become central coordination points, with a high volume of flows passing through them, another sign that the system isn’t truly decomposed.
- Violation of architectural layers and runtime dependencies rules – services that call other services that they are not supposed to depend on.
Additionally, vFunction generates a set of “TODOs” to improve the architecture, based on the architectural issues it detects or that the user specifies, on top of the analysis data. The user can also generate architectural prompts for AI code assistants to refactor the code and resolve the issue described by the TODO item.
vFunction reveals the real architectural dependencies, coupling points, and domain boundaries within your system, replacing assumptions and outdated diagrams with data grounded in runtime behavior. It also provides a set of TODOs for refactoring and improving the system’s architecture.
Here’s how vFunction helps teams identify and resolve distributed monolith patterns:
1. Automated architectural analysis: vFunction analyzes the behavior of the system with data science to visualize services, flows, runtime failures, resource usage, and more. This surfaces the actual coupling between services, including dependencies you won’t find in source code. For teams dealing with a distributed monolith, understanding what you’re actually working with rather than what you assume the architecture looks like is a critical first step.
2. Providing actionable TODOs to address the architectural issues of the distributed monolith: vFunction analyzes the results of the measurements and provides a prioritized set of TODOs to address the issues, including generating prompts for AI assistants, such as Github Copilot, Amazon Q, and Claude Code, to refactor and address the issues.
3. Enforcing architectural rules: Users can specify and enforce their own architectural rules on the system, and vFunction will automatically identify violations of these rules and create corresponding TODO items.
4. Continuous modernization: Fixing a distributed monolith isn’t a one-time project. As the system evolves, new coupling can creep back in. vFunction’s continuous modernization capabilities monitor the system and alert teams when changes introduce new dependencies or cause drift from the target-state architecture, preventing the distributed monolith from re-emerging.
Conclusion
The distributed monolith is what happens when the operational complexity of microservices meets the coupling of a monolith. It’s a common outcome of application modernization efforts that focus on infrastructure and deployment without addressing the underlying dependencies holding the system together.
The good news: it’s fixable. With continuous architectural modernization and an incremental approach to decoupling, teams can get to the flexible, independently deployable architecture they set out to build.
The key is understanding your system as it actually behaves, not how the diagrams say it should. See how your architecture actually behaves at runtime. Explore how the vFunction platform helps teams identify and resolve distributed monolith patterns.