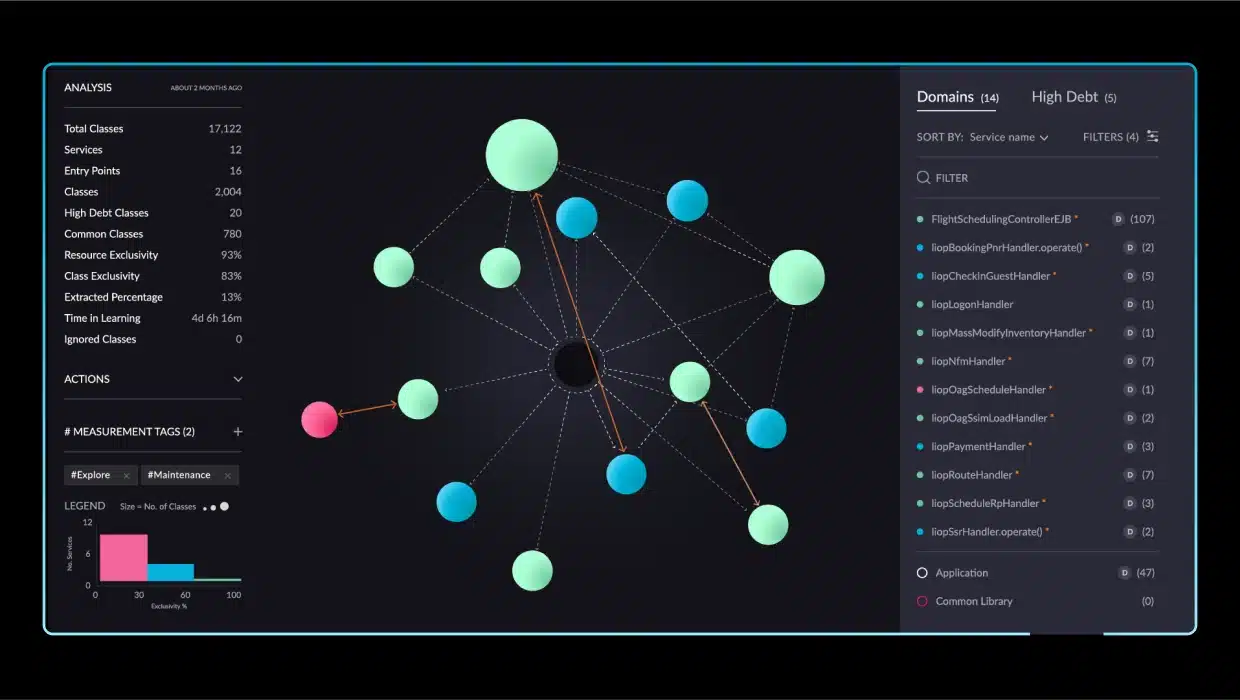
In our previous installment, Jason Bloomberg explored the challenges of delivering innovative AI-based functionality while depending upon legacy architectures. All too often, the design expectations of new and differentiating features are at odds with the massive architectural debt that exists within past systems.
Any enterprise that is not agile enough to respond to customer needs will eventually fail in the marketplace. At the same time, if the organization moves forward with new plans without resolving architectural and technical debt, that’s a surefire recipe for system failures and security breaches.
Customers and partners can try to mitigate some of this modernization risk by building service level agreements (SLAs) into their contracts, but such measures are backward-facing and punitive, rather than preventative and forward-looking. This is why both industry organizations and government bodies are adopting better standards and defining policies for IT governance, risk mitigation, and compliance (or GRC, for short).
Ignore governance at your own risk
Never mind the idea that any one institution is ‘too big to fail’ any more, even if they fill a huge niche in an overconsolidated economy. Institutions and companies can and will fail, and governments won’t always be there to backstop them.
Since the 2008 global financial crisis knocked down many once-stalwart financial and insurance firms, additional regulations were put in place to demand better governance and reduce over-leveraged investments, but it seems like some of the old risk patterns such as mortgage-backed securities are creeping back.
Recent events like the 2023 bank run failure and regulated sale of Silicon Valley Bank (SVB) again put a spotlight on the responsible governance business processes within all financial institutions. Analysts could pin their failure on human overconfidence and bad decisions, because they tied up too much capital in long-term bonds that quickly became illiquid when interest rates started rising sharply in 2022—but there’s a deeper story here.
As the name suggests, SVB grew by catering services to cutting-edge Silicon Valley startups and elite tech firms. Still, they got started themselves back in the 1980s. Therefore, beyond suffering from a lack of diversification, the systems bank executives used to predict interest risk were likely obsolete and poorly architected, and they failed to notice the approaching economic storm until it was upon them.
The changing nature of compliance
We are seeing renewed interest in GRC among IT executives and architects.
Updates from the Federal Financial Institutions Examination Council (or FFIEC) have now turned their focus on architecture, infrastructure, and operations in their recent “Architecture, Infrastructure, and Operations” booklet of the FFIEC Information Technology Examination Handbook. This booklet provides risk management guidance to examiners on processes that promote sound and controlled execution of architecture and operations information at financial institutions.
Further, the latest cyber-readiness orders from the White House are encouraging the creation of new mission teams dedicated to software compliance and software bill of materials (SBOMs). Similar initiatives like DevOps Research and Assessment (DORA) are taking hold in the European Union, and around the world.
Companies need to include architecture and operations in GRC assessments
The first compliance programs weren’t software-based at all, they were services engagements. At the behest of C-level executives concerned with risk management, high-dollar consultants would scour a corporation’s offices and data centers to conduct a manual discovery and auditing process.
The result? Usually a nice thick binder outlining the infrastructure as it exists, describing how the company maintains system availability and security protocols, just in case an investor or regulator comes looking to verify the company’s IT risk profile.
That’s not going to be good enough anymore. New guidelines and regulations are sending a warning to get every organization’s GRC house in order and that includes architecture and operations.
Since the advent of distributed service-based software applications, there have always been compliance checking tools, but they are focused mostly on the ongoing operations of the business, rather than the potential architectural debt caused by change. It’s time for that to change.
Where should we look for GRC improvements?
Most compliance regimes are rather general purpose. This is intentional, as a government or trade organization can’t dictate that organizations use specific architecture, only that they avoid risk. NIST and FFIEC guidelines cover all types of infrastructure.
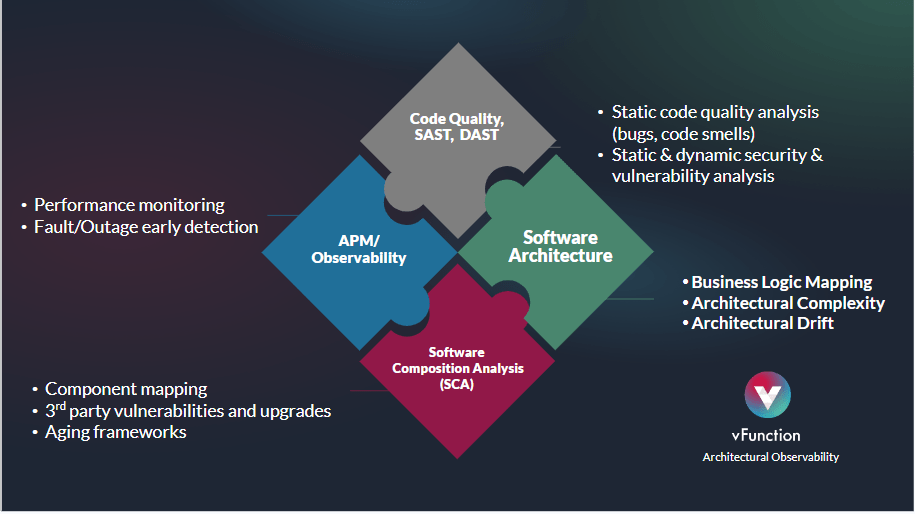
Four unique solution layers have evolved to focus on governance, compliance and risk.
- Code quality. Static and dynamic analysis of code for bugs and vulnerabilities has been around for a long time. Vendors like SonarQube and CAST arose within this category, as well as newer SAST and DAST scanning tools designed for modern platforms.
- Software composition analysis (SCA). By mapping the components of an enterprise architecture, vendors like Snyk, Tanium, Sonatype, Slim AI and other open source tools gather an SBOMb or an as-is topology, in order to help identify vulnerabilities or rogue items within the software supply chain.
- Observability now includes an amazing number of consolidated vendors including New Relic, Splunk, Datadog, Dynatrace and others, with solutions such as APM (application performance monitoring) platforms, as well as advanced processing of real-time events, logs, traces and metrics to provide telemetry into current outages and potential failures.
- Architectural Observability (AO) supports other GRC layers by mapping a software architecture and supporting code into modular, logical domains, in order to highlight where change and system complexity will introduce unexpected risk and costs. vFunction approaches this AO layer from a continuous modernization perspective.
The combined output of GRC efforts should produce effective governance policy, with clearly defined goals and risk thresholds to take much of the work and uncertainty out of compliance.
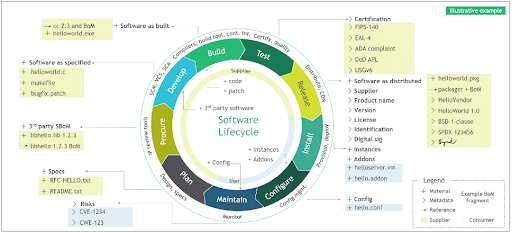
Who is involved in GRC efforts
Especially in highly regulated industries like financial and healthcare, GRC efforts would create two parallel workstreams: one for modernizing the application architecture with DevOps-style feedback loops, and another for continuously proving that the system under change remains compliant through architectural observability.
- Architects need to go well beyond the old Visio diagrams and ‘death star’ observability maps to conduct continuous architectural governance to identify and mitigate risk.
- System integrators and cloud service providers will need to lead the way on GRC initiatives for their contributions, or get out of the way.
- Auditing and certification services from leading consultants and vendors will need to move from one-time projects to continuous architectural observability.
- Software delivery teams will need to ‘shift-left’ with architectural observability, so the impact of drift and changes can be understood earlier in the DevOps lifecycle.
The Intellyx Take
Since there will always be novel cyberattacks and unique system failures caused by software interdependence, it’s time we started continuously validating our software architectures, to understand how change and drift can manifest as IT risk for organizations of all sizes.
Larger companies that fail to govern the architectures of their massive application and data estates will make the headlines if they have a major security breach, or get severely penalized by regulatory bodies. If the problems fester, they may even need to spin off business units or rationalize a merger.
Smaller organizations are even more risk averse, as a lack of trust can quickly cause them to be replaced by customers, and there’s far less cushion against architectural failures.
Adopting responsible governance policies for continuous compliance, coupled with architectural observability practices can allow everyone in the enterprise to breathe easier when the next major audit or new regulation approaches.
Next up? We’ll cover how AO can help application delivery teams break out of release windows and waterfall development to move forward with modern cloud architectures.
Copyright ©2024 Intellyx BV. At the time of writing, vFunction is an Intellyx customer. Intellyx retains final editorial control of this article. No AI was used to write this article. Image source: Adobe Image Express