After spending time on the ground in the U.K. for vFunction’s recent application modernization workshops with AWS and Steamhaus, I was struck by how smoothly things run. The Tube was fast and reliable. The flat, walkable streets—and the refreshing mix of people—were a welcome break from San Francisco’s hills and familiar routines. And the Eurostar? A game-changer. International travel that felt as easy as a BART ride across the Bay.
In that spirit of cultural comparison and exploration, we wanted to take a closer look at how engineering teams in the U.K. are approaching software architecture, especially in contrast to their peers in the U.S. To explore that shift, we pulled U.K.-specific insights from our 2025 Architecture in Software Development Report, which surveyed 629 senior technology leaders and practitioners across the U.S. and U.K. The U.K. edition reflects 314 respondents across industries including software and hardware, financial services, manufacturing, and others, from CTOs and heads of engineering to architects and platform leads.
While both regions are navigating the same wave of AI acceleration, their strategies reveal meaningful differences. As AI reshapes how software is built, shipped, and scaled, well-managed architecture is more important than ever for application resilience and innovation. Without continuous oversight, architectural complexity can quietly erode stability, delay delivery, and heighten risk, a reality many U.K. teams are now confronting. It’s a critical time to focus not just on architectural outcomes, but on the processes and tools that uphold them through rapid change.
What stood out? Three differences between the UK and the US
A revealing picture emerged where U.K. organizations are advancing and where they’re struggling. Here are three key differences between the U.K. and the U.S.
1. Greater operational challenges in the U.K.
Despite the striking efficiency of systems in cities like London—from public transport to international rail—many U.K. organizations are hitting bumps in the road when it comes to their software. Managing software becomes especially difficult when the underlying architecture isn’t stable. Without a sound architectural backbone, teams struggle to deliver consistent value, meet customer expectations, and scale effectively.
Software stability remains elusive for many U.K. companies. A vast majority—95%—report some form of operational difficulty tied to architectural issues. Compared to their U.S. counterparts, U.K. organizations face significantly higher rates of service disruptions, project delays, rising operational costs, and application scalability challenges. They also report more security and compliance issues (54% vs. 46%), which may further compound instability and risk.
While no region is immune, the data suggests U.K. teams are grappling with more entrenched and complex software challenges, often the downstream effects of architectural drift.
2. Higher OpenTelemetry adoption
While U.K. organizations face steeper software challenges, the data also shows they’re taking steps to confront them head-on. One key example: higher adoption of OpenTelemetry, the open standard for collecting telemetry data across distributed systems. OTel has been implemented in full or in part by 64% of U.K. respondents, compared to 54% in the U.S.
That puts U.K. teams in a stronger position to move beyond basic performance monitoring and toward real-time architectural insight, especially when paired with a platform like vFunction. With the ability to visualize service flows, detect architectural drift, and understand how systems evolve over time, these teams are laying the groundwork for greater visibility and control. A growing focus on advanced observability is becoming a critical foundation for both operational recovery and long-term resilience.
3. Architecture integration in the SDLC improves with scale in the U.K.
Despite persistent challenges, larger U.K. organizations report greater architecture integration across the software development lifecycle than smaller firms, an encouraging contrast to the U.S., where smaller companies tend to show stronger alignment than their larger peers.
This suggests that while U.K. enterprises may be grappling with deeper architectural complexity, they’re also taking more deliberate steps to embed architecture throughout development as they scale. In many cases, integration isn’t just a function of growth—it’s a necessary response to it.
While U.K. teams may be experiencing the impact of architectural challenges more acutely, they’re also laying the groundwork for more sustainable, architecture-led software practices.
And there’s more. Get the full report.
Want to know which industries are leading—or where the biggest risks still lie?
The full U.K. report dives deeper into how documentation, SDLC integration, and observability intersect across software, financial services, and manufacturing. It also explores how leadership and practitioners perceive architecture differently, and how AI is reshaping complexity—along with what U.K. teams are doing to stay ahead.
When assessing software, we often consider whether it is “enterprise-ready,” evaluating its scalability, resilience, and reliability. Achieving these criteria requires consideration of best practices and standards, centered around technology and architecture.
Enterprise software architecture is the backbone of digital transformation and business agility, providing proven structural frameworks for building scalable and resilient applications. Rooted in industry experience, these patterns offer standard solutions to common challenges. This guide explores essential enterprise architecture patterns, their pros and cons, and practical advice for selecting the right option. Understanding these patterns is key to creating high-quality software that is fit for enterprise use.
What are enterprise architecture patterns?
Enterprise architecture patterns are standardized, reusable solutions for common structural issues in organizational software development. While smaller-scale design patterns target specific coding problems, enterprise architecture patterns tackle broader, system-wide concerns such as component interaction, data flow, and scalability for enterprise demands.
These conceptual templates provide guidance to developers and architects in structuring applications to meet complex business requirements while maintaining flexibility for future growth. Just as building architects use established designs, software architects use these patterns to make sure their applications can withstand changing business needs. Enterprise architecture patterns typically address:
Why architecture patterns matter in enterprise software
System design and implementation often present various problems, and there are usually multiple solutions to choose from. This abundance of options can be overwhelming. Architecture patterns are important because they provide architects and developers with a strategic advantage by helping them understand various approaches. Following these patterns offers several benefits across different areas. Here’s why knowing and applying enterprise architecture patterns is crucial:
Reduced technical risk: Well-established patterns have been battle-tested across multiple implementations, reducing the likelihood of structural failures in critical business systems. This proven track record gives stakeholders confidence in the system.
Faster development: Patterns provide ready-made solutions to common architectural problems, so development teams can focus on business-specific requirements rather than solving fundamental structural problems from scratch. This can speed up development cycles.
Better communication: Patterns create a shared vocabulary among development teams, so it’s easier to discuss and document system design. When an architect says “microservices” or “event-driven architecture”, the whole team knows what they mean.
Easier maintenance: Following established patterns results in more predictable, structured codebases that new team members can easily understand and modify. This reduces the learning curve and keeps development velocity even as team composition changes.
Future proofing: Well-chosen patterns provide flexibility for growth and change, so systems can adapt to changing business requirements without requiring complete rewrites. This is especially important in today’s fast-paced business world.
Cost efficiency: By preventing architectural mistakes early in the development process, patterns avoid costly rework and refactoring later. According to industry studies, architectural errors found in production can cost up to 100 times more to fix than those found during design.
With the rapid digital transformation in various industries, the significance of architecture patterns in enterprise software increases. So, what are some common enterprise architecture patterns? You may be familiar with many of the ones we will discuss below. Let’s delve in.
Common enterprise architecture patterns
Here are some common types of enterprise software architectures.
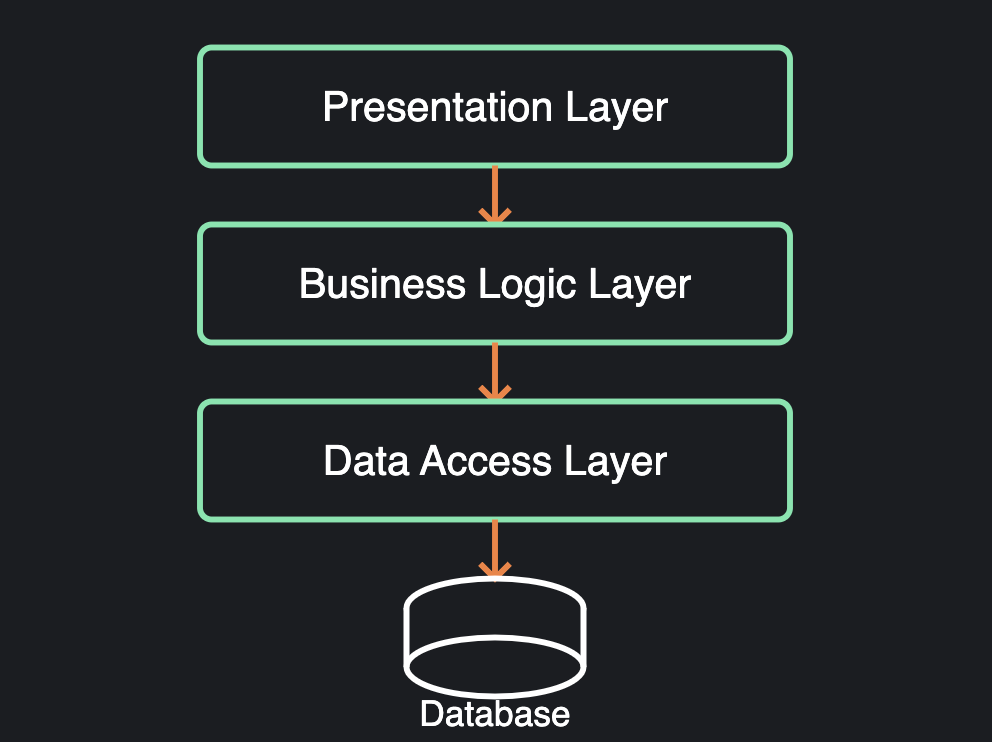
Layered architecture
The layered architecture pattern, also known as n-tier architecture, organizes components into horizontal layers, each performing a specific role in the application. Typically, these include presentation, business logic, and data access layers.
Simple diagram of a layered architecture
The key attributes of this architecture are:
Components only communicate with adjacent layers
Higher layers rely on lower layers, not the other way around
Each layer has a distinct responsibility
This pattern is commonly suited for traditional enterprise applications, particularly those with intricate business rules but straightforward scalability needs. For example, a banking system might have a web interface layer, a business rules layer for transaction processing, and a data access layer for talking to the core banking database.
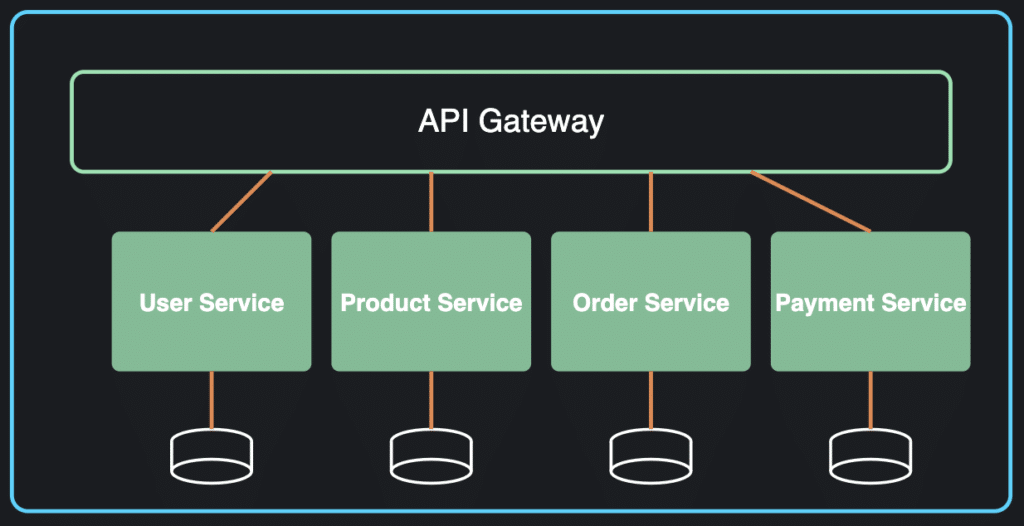
Microservices architecture
In recent years, the popularity of this pattern has surged because of its numerous advantages. Microservices break down applications into small, independent services that can be developed, deployed, and scaled individually. Each service focuses on a specific business capability and talks to other services through well-defined APIs.
Diagram of a simple microservices architecture
The key attributes of this pattern include:
Services are loosely coupled and independently deployable
Each service owns its data storage and business logic
Services communicate via lightweight protocols (often REST or messaging)
Enables polyglot programming and storage
Although it brings many advantages, taking a microservices approach and managing it successfully requires a mature DevOps culture, strong observability tools (monitoring, logging, tracing), and careful data consistency strategies to manage the increased complexity and ensure resilience. The distributed nature of microservices introduces challenges in transaction management, service discovery, and failure handling that must be explicitly addressed.
Microservices architectures are ideal for large applications with many different functionalities that benefit from independent scaling and deployment of components. An e-commerce platform is a good example of using microservices. When divided into microservices, this type of system would have separate microservices to manage functionalities for user profiles, product catalog, order processing, and recommendations. Since each is managed separately, different teams can maintain each microservice if desired.
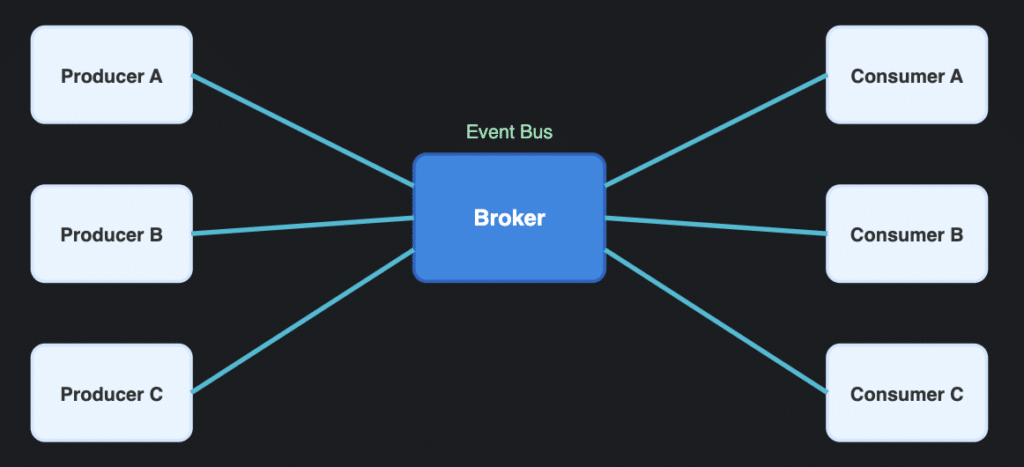
Event-driven architecture
Many modern enterprise applications, especially those dependent on real-time actions, depend on event-driven architectures. Event-driven architecture revolves around the production, detection, and consumption of events. Components communicate by generating and responding to events rather than through direct calls. Much of the time, the underlying services that handle the events leverage the last pattern we chatted about: microservices.
Example diagram of an event-driven architecture
The key attributes of this pattern include:
Loose coupling between event producers and consumers
Asynchronous communication model
Can use event mediators (event brokers) or direct publish-subscribe mechanisms
Naturally accommodates real-time processing
As mentioned, this pattern is really well suited for systems requiring real-time data processing, complex event processing, or reactive behavior. For example, a stock trading platform might use events to notify various system components about price changes, allowing each component to react appropriately without tight coupling.
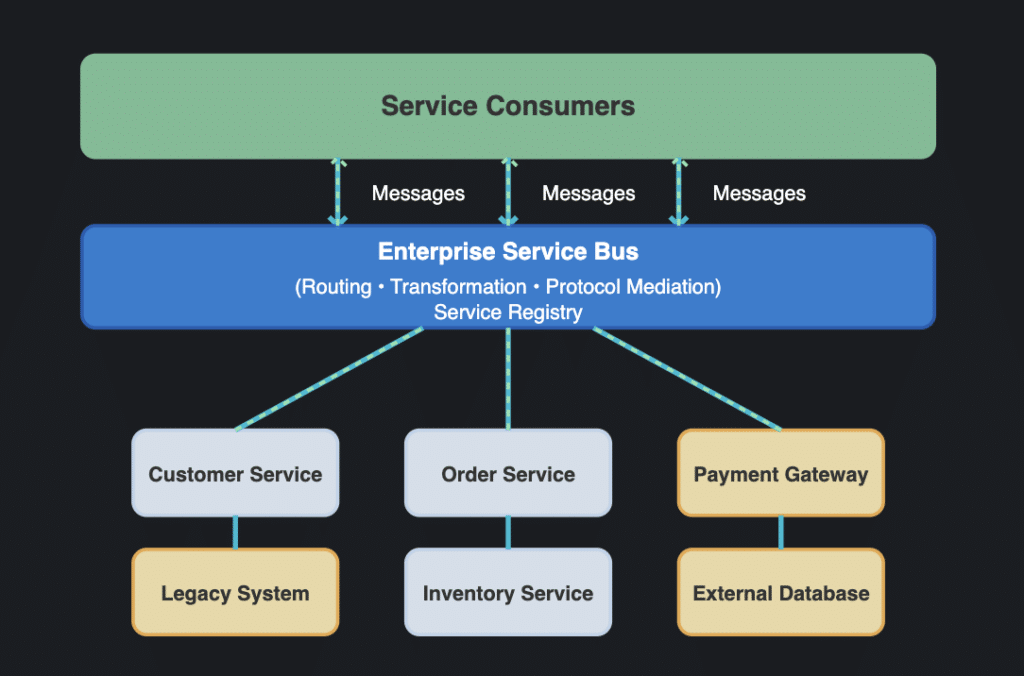
Service-oriented architecture (SOA)
Although a bit dated and not as popular as it once was, service-oriented architectures are still commonly used, especially in the .NET and Java realms. SOA structures applications around business-aligned services that are accessible over a network through standard protocols. It emphasizes service reusability and composition. Like microservices, the services in SOA are not as detailed as those in a typical microservices architecture.
Diagram of a sample SOA architecture
The key attributes of this pattern include:
Services expose well-defined interfaces
Services can be composed to create higher-level functionality
Often includes a service bus for mediation and orchestration
Typically more coarse-grained than microservices
Over the years, SOA has morphed from traditional SOA to a more modern approach. Traditional SOA uses an Enterprise Service Bus (ESB); modern SOA overlaps with microservices but retains the traditional SOA’s principles of service reuse and contract standardization. Modern SOA is lightweight, service-to-service communication, unlike a central bus that is typically used in a traditional architecture.
Regardless of the approach, this pattern can work well for enterprises with multiple applications that can share services and standardized integration. For example, an insurance company might expose claim processing, policy management, and customer information as services that can be reused across multiple applications.
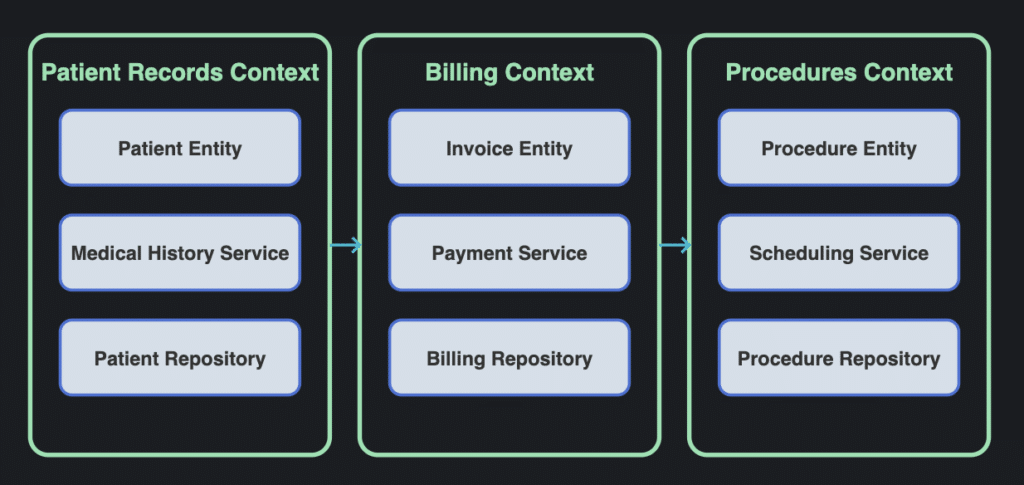
Domain-driven design (DDD)
DDD itself is not an architectural pattern, but it guides architectural decisions by highlighting domain boundaries and the importance of business logic. It frequently influences patterns like microservices or modular monoliths.
A diagram showing how different contexts work with a DDD architecture
The key attributes of DDD that make it applicable in this context include:
Bounded contexts with clear boundaries
Aligns software models with business domain models
Uses ubiquitous language shared by developers and domain experts
Separates core domain logic from supporting functionality
This approach works well for complex business domains where model clarity and business rules are key. For example, a healthcare system might have separate models for patient records, billing, and medical procedures. Using DDD to design and implement such a system would be well-suited.
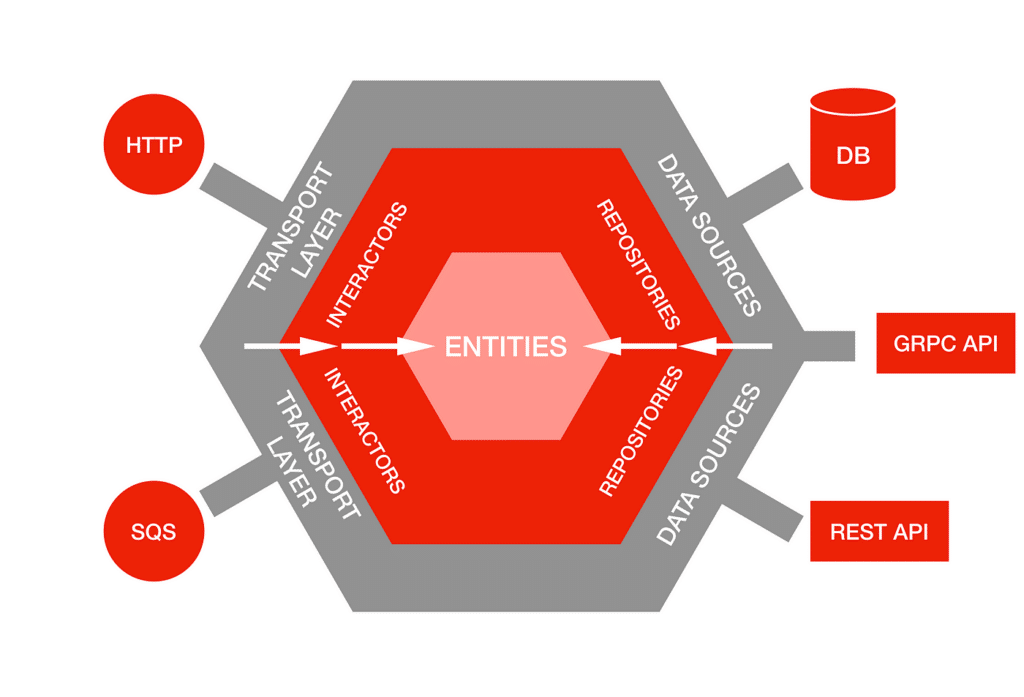
Hexagonal architecture (ports and adapters)
Sometimes, older patterns are bundled together with more modern ones. One such pattern is the hexagonal architecture, which separates the core application logic from external concerns by defining ports (interfaces) and adapters that implement those interfaces for specific technologies. This is often used in conjunction with microservices.
Example of how hexagonal architectures work. Original courtesy of Netflix Tech Blog
The key attributes of the hexagonal architecture pattern include:
Business logic has no direct dependencies on external systems
External systems interact with the core through adapters
Facilitates testability by allowing external dependencies to be mocked
Supports technology evolution without impacting core functionality
Using this pattern is typically helpful for systems that need to integrate with multiple external systems or where technology choices may evolve over time. For example, a payment processing system might define ports for different payment providers. Following this pattern would allow new providers to be added without changing the core payment logic.
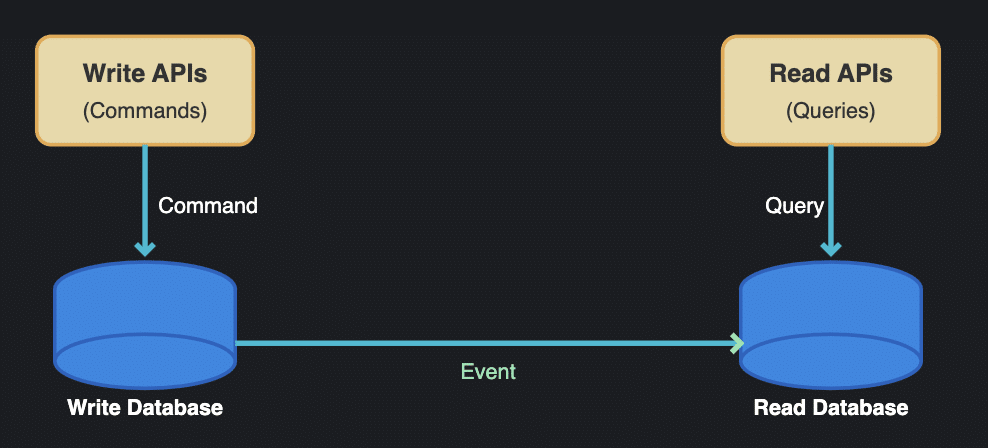
CQRS (Command Query Responsibility Segregation)
CQRS (Command Query Responsibility Segregation) has been widely used since it was introduced by Greg Young in 2009. It separates read and write operations into separate models for independent optimization. It is commonly paired with Event Sourcing in an event-driven architecture.
Simple diagram of how the CQRS pattern works
The key attributes of this pattern include:
Separate models for reading and updating data
Can use different data stores optimized for each purpose
Often paired with event sourcing for audit trails and temporal queries
May involve eventual consistency between read and write models
The pattern itself offers some good flexibility when implemented. CQRS can be simplified by using the same database with different models instead of separate data stores. This approach is more straightforward for systems that don’t need full auditability or extreme performance optimization. It offers a range of implementation options, from logical separation to complete physical separation.
Systems with intricate domain models, high read-to-write ratios, or collaborative domains prone to conflicts are best suited for this pattern. For instance, an analytics platform could benefit from a customized read model for complex queries alongside a basic write model for data input.
Software architecture patterns vs. design patterns
While related, software architecture patterns and design patterns address different levels of abstraction in software development. Understanding the distinction helps development teams apply each of them appropriately.
Architecture patterns
Architecture patterns operate at the highest level of abstraction, defining the overall structure of an application or system. They determine how:
The system is divided into major components
These components interact and communicate
The system addresses qualities like scalability, availability, and security
Architecture patterns affect the entire application and typically require significant effort to change once implemented. They’re usually chosen early in the development process based on business requirements and quality attributes.
Design patterns
Design patterns, popularized by the “Gang of Four,” operate at a more detailed level, addressing common design problems within components. They provide:
Solutions to recurring design challenges in object-oriented programming
Best practices for implementing specific functionality
Guidelines for creating flexible, maintainable code
Unlike architecture patterns, design patterns apply to specific parts of the system and can be implemented or changed without affecting the overall architecture. Examples include Factory, Observer, and Strategy patterns.
The complementary relationship
Architecture and design patterns complement each other when building enterprise systems. Here’s how:
Architecture patterns establish the overall structure
Design patterns help implement the details within that structure
Multiple design patterns can be used within a single architecture pattern
Some patterns (like model-view-controller) can function at both levels, depending on the scope
When developers understand both types of patterns, architecture, and design, and how they interrelate, they can create well-structured systems at both macro and micro levels.
Comparative analysis of enterprise architecture patterns
Digging back into the particulars of the enterprise architecture patterns we covered above, understanding the benefits and challenges of each helps to choose which to apply and when. To do this, selecting the correct architecture pattern requires understanding each pattern’s trade-offs. Let’s compare the major enterprise architecture patterns across several dimensions:
Pattern
Scalability
Flexibility
Complexity
Deployment
Layered
Moderate
Low
Low
Monolithic
Microservices
High
High
High
Independent services
Event-Driven
High
High
High
Varies
SOA
Moderate
Moderate
Moderate
Service-based
Hexagonal
Moderate
High
Moderate
Varies
CQRS
High
Moderate
High
Separate read/write
Performance considerations
Between the different patterns, performance varies greatly.
Layered Architecture: Can introduce performance overhead due to data passing between layers. Vertical scaling is typical.
Microservices: Enables targeted scaling of high-demand services but introduces network latency between services. Distributed transactions can be challenging.
Event-Driven Architecture: Excels at handling high throughput with asynchronous processing but may face eventual consistency challenges.
SOA: The Service bus can become a bottleneck under high load. More coarse-grained than microservices, potentially limiting scaling options.
Hexagonal Architecture: Performance depends on implementation details and adapter efficiency, but generally supports optimization without affecting core logic.
CQRS: Can dramatically improve read performance by optimizing read models, though synchronization between models adds complexity.
Maintenance and evolution
Similar to performance, Long-term maintainability varies by pattern:
Layered Architecture: Easy to understand, but can become rigid over time. Changes often affect multiple layers.
Microservices: Easier to maintain individual services, but requires advanced operational infrastructure. Service boundaries may need to evolve over time.
Event-Driven Architecture: Flexible for adding new consumers, but event schema changes can be hard to propagate.
SOA: Service contracts provide stability but can become outdated. Service versioning is key.
Hexagonal Architecture: Highly adaptable to changing external technologies while keeping core business logic.
CQRS: Separate read and write models allow independent evolution, though synchronization logic requires careful management.
In reality, many enterprise applications use hybrid architectures, combining elements of different patterns to address specific needs. For example, a system might use microservices overall, but CQRS within specific services or event-driven principles are used for integration, while using a layered architecture within components.
How to choose the right architecture pattern for enterprise
Selecting the appropriate architectural pattern is a crucial decision that significantly influences the future of your application. It is essential to thoroughly consider and carefully select the architectural pattern that best suits your use case. Follow the steps below to ensure that all aspects are thoroughly assessed and that the chosen pattern aligns with the application’s requirements.
1. Identify key requirements and constraints
Start by clearly defining what your system needs to do. This includes looking at factors such as:
Functional requirements: The core capabilities the system must provide
Quality attributes: Non-functional requirements like performance, scalability, and security
Business constraints: Budget, timeline, and existing technology investments
Organizational factors: Team size, expertise, and structure
The insights from this assessment usually help to quickly narrow things down. However, it’s important to remember that no architecture can optimize for all of these qualities at the same time.
2. Assess your domain complexity
Next, consider the nature of your business domain, as it will also influence your choice of architecture. Simple domains with well-known, stable requirements might benefit from simple layered architectures, while complex domains with evolving business rules often benefit from Domain-Driven Design, potentially combined with microservices. Data-intensive applications might use CQRS to separate reading and writing. Integration-heavy scenarios usually require service-oriented or event-driven approaches. Having a good understanding of the domain complexity will give further insights into what architecture patterns will and won’t work well for the system at hand.
3. Consider organizational structure
Conway’s Law says systems tend to reflect the communication structures of the organizations that design them. Large teams with specialized skills can work well with microservices, each owned by a cross-functional team. Small teams might struggle with the operational complexity of highly distributed architectures. Geographically distributed teams might benefit from clearly defined service boundaries and interfaces. Organizational structure can definitely make certain patterns easier to implement and to maintain in the long term.
4. Evaluate the technology ecosystem
Unless you are starting a project entirely from scratch, certain technologies will likely already be ingrained within your engineering organization. Therefore, both existing and planned technology investments should play a role in shaping your architectural decisions. For example, legacy system integration requirements might favor SOA or hexagonal architecture, cloud-native development often aligns well with microservices and containerization, and real-time processing needs point toward event-driven architectures. More than anything else on this list, the technology ecosystem you’re playing within can be one of the largest factors in dictating which patterns are feasible.
5. Plan for growth and change
While current requirements are crucial, it is equally important to consider the future needs of the system. Ensure that the selected patterns can support future functionalities. Changing the underlying architecture of an application is a complex process, so it is essential to carefully consider the following before making a final decision :
Scale: Will you need to support 10x or 100x growth in users or transactions?
Agility: How often do you expect major feature additions or changes?
Regulatory landscape: Are compliance requirements going to change significantly?
With these and other potential factors in mind, you can then test your patterns of choice to make sure that they can support the future needs of your business without a massive overhaul.
6. Leverage architectural observability with vFunction
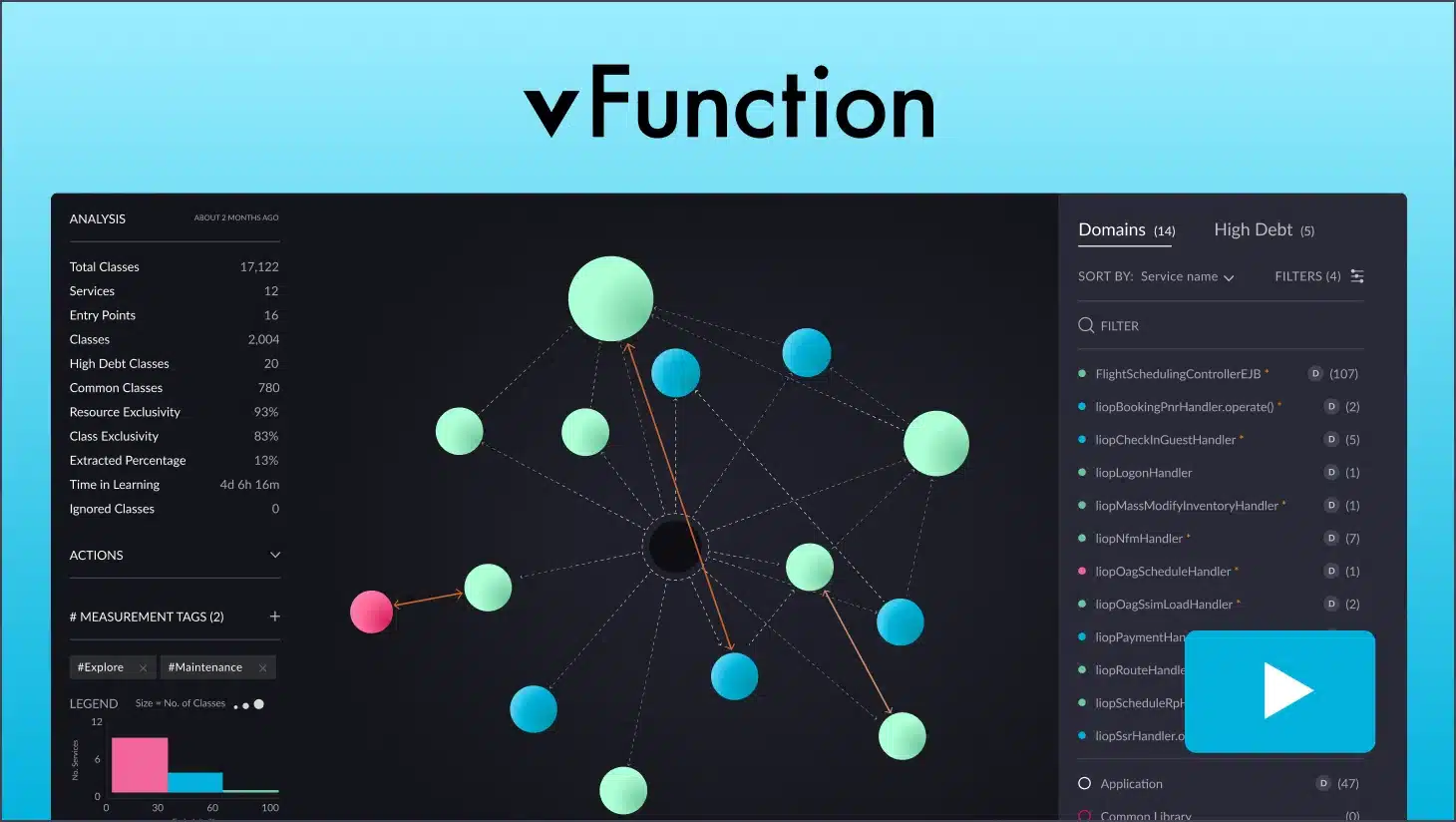
For enterprises with existing applications, the journey from the current architecture to the target state requires an understanding of the current state. This is where architectural observability through vFunction comes in.
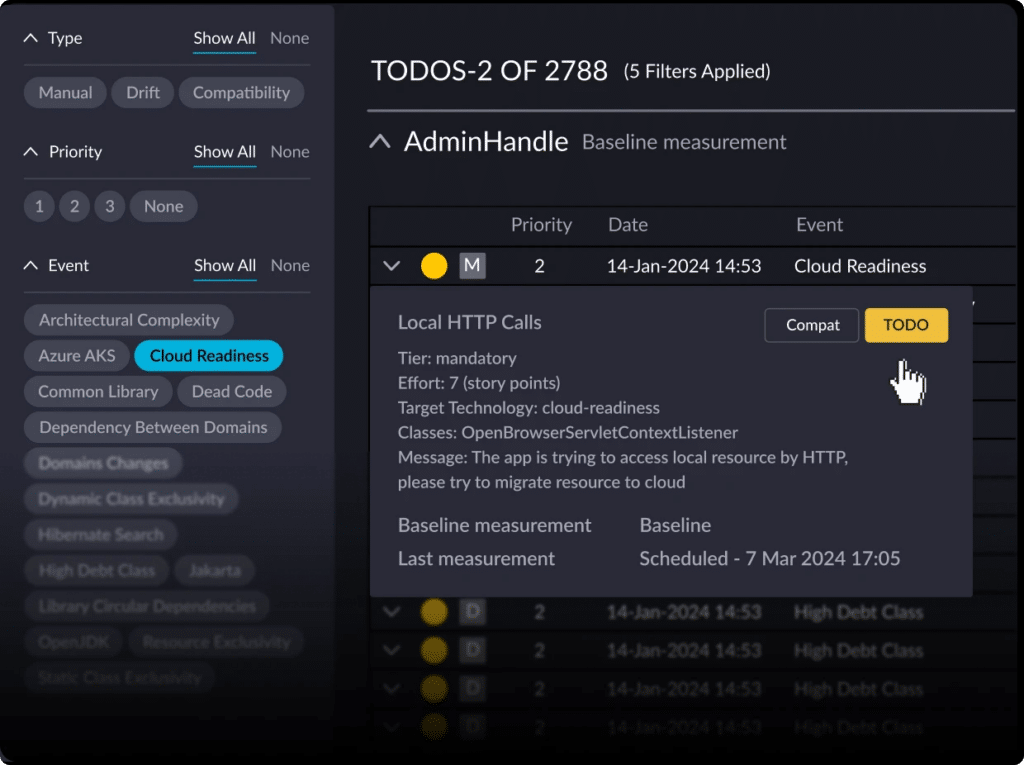
vFunction helps architects and developers understand the patterns used within their applications
vFunction helps organizations modernize existing applications by providing AI-powered analysis and modernization capabilities. The platform helps with:
Architectural discovery: vFunction analyzes application structure and dependencies, creating a comprehensive map of your current architecture that serves as a foundation for modernization planning.
Service identification: The platform identifies service boundaries within monoliths, so architects can determine the best decomposition into microservices or other modern architectural components.
Refactoring automation: vFunction provides specific guidance and automation for extracting and refactoring code to match your target architecture pattern, reducing the risk and effort of modernization.
For example, Turo used vFunction to enable the car-sharing marketplace to speed up its monolith to microservices journey, improve developer velocity, and prepare its platform for 10x scale. By providing architectural observability, vFunction bridges the gap between architectural vision and reality, making modernization projects more predictable and successful.
7. Implement incrementally
Lastly, once you’ve chosen a pattern, consider an incremental implementation. Compared to a big-bang implementation, where everything is deployed immediately, rolling things out incrementally is a better option that is less risky. Of course, this depends on your chosen architecture having the flexibility to support it. You’ll need to:
Start small and apply the pattern to a small scope first to validate assumptions.
Leverage the Strangler pattern to gradually migrate functionality from legacy systems to the new architecture.
Continuously evaluate and regularly check if the chosen architecture is delivering expected benefits.
Following these steps, from deciding on the architecture to implementing it, the chances of success are much higher than going into this type of project without a plan.
Conclusion
Enterprise software architecture patterns provide proven blueprints for building complex systems that can withstand the test of time and changing business needs. By understanding the strengths, weaknesses, and use cases for each pattern, architects can make informed decisions that align technology with business goals.
The most successful enterprise architectures rarely follow a single pattern dogmatically. Instead, they thoughtfully combine elements from different patterns to address specific requirements, creating hybrid approaches tailored to their unique context. This pragmatic approach, guided by principles rather than dogma, tends to yield the best results.
As digital transformation accelerates, the ability to choose and implement the right architecture patterns becomes more critical for business success. Organizations that master this skill will build systems that are not just functional today but adaptable to tomorrow’s challenges.
Whether you’re building new enterprise systems or modernizing legacy applications, investing time in architectural planning pays off in reduced development costs, improved maintainability, and greater business agility. And with vFunction, the journey to modern architectures is more accessible even for organizations with large legacy codebases.
The right architecture won’t just solve today’s problems — it will create a foundation for tomorrow’s innovations. Choose wisely.Ready to modernize your enterprise application architecture? Learn more about how vFunction can help you get there faster with AI-powered analysis and automated modernization. Contact our team today to find out more.
Unlike past systems that relied on asynchronous and batch processing, real-time software architecture is now essential in today’s fast-paced digital world, where instant information processing is the norm. Speed, reliability, and predictability are key in real-time applications, from e-commerce platforms responding to customer actions to financial systems executing transactions in microseconds. This is where real-time software architecture comes in to make these applications and levels of performance possible.
The term “real-time” means systems that must respond within strict timeframes or deadlines. For architects and developers, understanding how to design these systems is crucial for building solutions that meet the demands. This blog delves into core principles, performance metrics, cost management, and real-world case studies, providing essential insights for mastering real-time systems. Let’s begin with the basics of real-time architecture.
What is real-time software architecture?
In real-time software architecture, time is of the essence. It’s not just about producing the right result—it’s about doing so within a strict deadline. Even a correct output can be useless if it arrives too late.
Real-time software architecture is the design of systems where producing the right result at the right time is critical. These systems must respond to events within strict deadlines, delays can make outputs inaccurate, ineffective, or even harmful. Real-time systems fall into three categories:
Hard real-time systems: Missing a deadline is a system failure. Examples include industrial control systems and trading platforms where transaction timing is critical.
Firm real-time systems: Missing a deadline degrades service quality but doesn’t cause system failure. Examples include video conferencing, where occasional frame drops are annoying but don’t end the call.
Soft real-time systems: The result’s usefulness degrades after its deadline, but the system continues to function. Examples include content recommendation engines where slightly delayed personalization is still valuable.
In order to accommodate these different expectations, the target application must be engineered and designed with real-time performance in mind. Regardless of the expected timeframe for results, a well-built, real-time architecture manages resources, task scheduling, communication, and error handling to ensure timing constraints are met for its specific category.
Real-time vs. non-real-time software architecture
It’s also important to understand what does and doesn’t fall under real-time software architecture. Batch processing, which handles data in bulk at scheduled intervals, is a classic example of a non-real-time system. Although real-time architecture is a common route to go, not all use cases and scenarios require such capabilities. Here is a quick breakdown to help you understand the differences in approach and use cases.
Aspect
Real-time software architecture
Non-real-time software architecture
Typical use sases
Fraud detection, real-time personalization, live monitoring, trading apps
Prioritizes maintainability or throughput over timing precision
Technical debt impact
Architectural technical debt creates latency, unpredictability, and missed deadlines—disastrous for real-time systems. Even small inefficiencies, like blocking calls or unbounded queues, can break SLAs or trigger cascading failures.
Debt slows delivery, increases maintenance costs, and may degrade performance, but rarely causes immediate failure. Deadlines are flexible.
Why do you need real-time software architecture?
Not long ago, the question was, “Why do we need real-time results?” but now real-time is the default. Nearly all applications include real-time components alongside historical data analysis. This shift highlights the essential role of real-time software and data architectures in modern applications, driven by key factors that include the following:
Business-critical operations
For many systems, timing impacts business outcomes. Numerous applications and industries rely on genuine real-time systems to deliver outstanding customer experiences and boost revenue. Some examples of this are:
E-commerce platforms: Real-time inventory updates, personalization, and transaction processing directly impact conversion rates and customer satisfaction.
Financial services: Trading platforms, payment processing, and fraud detection systems require millisecond-level responsiveness to work.
Better user experience
As we’ve discussed, the expectation of “instantaneous” service is a challenging one to meet. True instant feedback is achievable only through the integration of real-time capabilities into the underlying services. For instance, users anticipate instantaneous feedback when utilizing:
Web and mobile applications: Responsive interfaces with sub-second load times and instant updates (e.g., social feeds, collaborative editing) are now the norm.
Streaming services: Content delivery with minimal buffering and adaptive quality requires real-time decision making.
Data-driven decision making
In legacy systems, businesses would sometimes wait hours or even days for large batches of data to be processed and deliver insights. Now, relying on this approach would put you well behind competitors. This is why businesses use real-time analytics for instant insights, such as:
Customer engagement platforms: Real-time analysis of user behavior enables dynamic personalization and targeted interventions.
Business intelligence: Dashboards with live data visualization allow immediate response to changing conditions.
Event-driven systems
There has been a massive shift towards event-driven systems and architectures. In these cases, real-time architecture is the core component that makes the whole system tick. Modern distributed systems often rely on real-time event processing:
Microservices: Event-driven communication between services requires timely message delivery and processing.
IoT applications: Processing sensor data streams in real-time enables responsive automation and monitoring.
Whenever timing impacts business value, user satisfaction, or operational effectiveness, real-time software architecture is needed. So, what are the core principles that take a business need into reality when it comes to implementing real-time systems? Let’s delve deeper.
Core principles of real-time software architecture
If someone says that they require “real-time capabilities”, what is the rubric that we, as developers and architects, should adhere to? In this regard, certain key areas enable a real-time application to truly be considered one. Real-time software must adhere to core principles and criteria, from its code performance to the required infrastructure.
1. Timeliness and predictability
The most important piece is that the system must guarantee tasks are completed within specified deadlines. This means predictable algorithms, bounded execution paths, and appropriate event prioritization. For example, a payment processing service must validate, process, and confirm transactions within milliseconds to maintain throughput during peak shopping periods.
2. Resource management
To hit these deadlines, system resources must be allocated efficiently to prevent contention that could lead to missed deadlines. This means focusing on:
Memory management with minimal garbage collection pauses
CPU scheduling that prioritizes time-critical operations
Network bandwidth allocation for critical data flows
3. Concurrency control
Many real-time systems handle continuous massive read and write operations, requiring efficient management of concurrent operations to uphold performance. To do this, applications must:
Use non-blocking algorithms where possible
Leverage efficient synchronization mechanisms with bounded waiting times
Use thread pool optimization for predictable execution
4. Fault tolerance
If a system misses a deadline, it is an issue; a critical real-time system going down is even more catastrophic. Real-time systems need rapid failure detection and recovery mechanisms in place. Typically, this involves:
Circuit breakers to prevent cascading failures
Fallback mechanisms with degraded but acceptable performance
Health monitoring with rapid failure detection
5. Data consistency models
Depending on the type of data and decisions being derived from it, many real-time systems relax strict consistency for performance. In these cases, you’ll typically see:
Eventually consistent models for non-critical data
Conflict resolution strategies for concurrent updates for maintaining data integrity
CQRS (Command Query Responsibility Segregation) patterns to separate read and write operations
6. Event-driven design
Asynchronous, event-driven architectures often form the core of real-time systems. This means that code and architectural components of the system will include:
Message brokers like Kafka or RabbitMQ for reliable, ordered event delivery
Event sourcing patterns for auditable state changes
Stream processing for continuous data analysis
By following these principles, developers can build systems that meet the real-time needs of their use cases. These six principles make up the core requirements when designing and implementing real-time applications and services. Furthermore, understanding the various aspects of performance is crucial for a real-time system. This will be the focus of our next discussion.
Performance metrics in real-time systems
“Fast”, “instant”, and other descriptions for performance don’t truly encompass the different ways that developers and architects need to address performance within real-time systems. In real-time systems, specific performance metrics help measure whether the system meets its timing requirements from various angles. Next, we will examine the key metrics to consider when determining the required system performance and evaluating your implementation.
Metric
Definition
Importance
Example
Response time (latency)
Time from event to system response
Must be within specified deadlines
An e-commerce checkout must complete payment authorization in two seconds to minimize cart abandonment
Throughput
Number of events or transactions per unit time
Measures system capacity while meeting deadlines
A message broker must handle 100,000+ events per second during peak
Jitter
Variance in response times
High jitter means an unpredictable user experience
In video conferencing, consistent frame timing is as important as raw speed
Scalability under load
How metrics change as system load increases
Real-time systems must meet deadlines at peak capacity
A real-time bidding platform must meet millisecond response times during high-traffic events
Recovery time
Time to recover from failure
Long recovery times may violate SLAs
A payment gateway should recover from node failures in seconds to maintain transaction flow
Although response time is usually the first place we start, there are several metrics beyond this to consider. Defining and monitoring these metrics ensures real-time systems meet the required level of timeliness and reliability that users expect. Next, let’s look at the architectural considerations for building and scaling these systems.
Architectural considerations for real-time systems
As architects and developers, we often have a playbook for how we build applications. In a traditional three-tier application, we focus on the presentation tier, or user interface; the application tier, where data is processed; and the data tier, where application data is stored and managed. Real-time requirements still follow these architectural patterns, but they demand specific technologies to support timely execution and responsiveness. Let’s look at the several architectural components and patterns that support real-time performance:
Message brokers and event streaming platforms
Apache Kafka, Amazon Kinesis, and similar platforms are the foundation for many real-time systems. They provide:
High-throughput, low-latency message delivery
Persistent storage of event streams
Partitioning for parallel processing
Exactly-once delivery
For example, a retail company may use Kafka to ingest and process customer clickstream, inventory updates, and order events across its digital platform.
In-memory data grids
Technologies like Redis, Hazelcast, and Apache Ignite enable ultra-fast data access. The benefits of using these technologies include:
Sub-millisecond read/write operations
Data structure support beyond key-value
Distribution and replication
Eventing for change notifications
Stream processing frameworks
Frameworks like Apache Flink, Kafka Streams, and Spark Streaming support real-time data processing. These frameworks provide:
Windowing operations for time-based analytics
Stateful processing of streaming data for complex event detection
Exactly-once processing guarantees
Low-latency aggregations and transformations
Reactive programming models
Beyond infrastructure-level components, reactive approaches to programming through frameworks like Spring WebFlux, RxJava, and Akka provide the application-level implementations for responsive systems. These languages/frameworks provide:
Non-blocking I/O to maximize resource utilization
Backpressure handling to manage overload conditions
Compositional APIs for complex asynchronous workflows
Thread efficiency through event loop architectures
Microservices and API gateway patterns
Real-time systems often leverage microservices architectures that align with best practices. This allows the deployed microservices to deliver:
Service isolation that prevents performance issues from spreading
Circuit breakers to handle degraded dependencies
Request prioritization at API gateways
Latency-aware load balancing
Caching strategies
Strategic caching is generally also required to improve response times for frequently accessed data. This takes into consideration factors such as:
Cache invalidation strategies that balance freshness and performance
Predictive caching based on usage patterns
Write-through vs. write-behind approaches
Database selection and configuration
Lastly, the chosen database or data warehouse technologies must be able to accommodate real-time performance. These databases include:
NoSQL options like Cassandra or MongoDB for consistent write performance
Time-series databases for sensor or metrics data
The ability to create read replicas to scale query capacity
Support for appropriate indexing strategies to help with scalable read operations
Using these architectural components, developers can design and implement real-time systems. Much of the real-time capabilities rely on data infrastructure components. With the increasing popularity of real-time technologies, there are now technologies available to support every part of the real-time data stack. However, the numerous required components can lead to rising costs. Hence, effective cost management is crucial.
Cost management in real-time architectures
Software is already expensive to build, but real-time software, with its added complexity and scalability demands, can quickly become a heavy burden.That being said, there are some strategic approaches that can be used to help tame those costs. Let’s look at the different categories, details, and potential strategies for cost savings for each.
Cost category
Description
Cost considerations
Infrastructure costs
Real-time systems often require more infrastructure
Right-sizing: Balance between peak capacity needs and average utilizationCloud vs. on-premises: Evaluate TCO considering performance requirementsHybrid approaches: Use cloud bursting for peak demand while maintaining baseline capacity
Development complexity
Real-time requirements increase development effort
Specialized skills: Developers with experience in asynchronous programming, performance optimizationTesting infrastructure: Load testing tools and environments that can simulate production conditionsMonitoring solutions: Comprehensive observability platforms with sub-second resolution
Operational considerations
Ongoing costs for maintaining real-time systems
24/7 support: Real-time systems often support critical business functions requiring constant availabilityPerformance tuning: Continuous optimization as usage patterns evolveScaling costs: Ensuring capacity for growth and peak demand
Strategic approaches
Cost-effective implementation strategies
Tiered architecture: Apply real-time only where neededGradual migration: Move components to real-time architecture incrementallySaaS options: Consider managed services for message brokers or stream processing
Balancing these factors helps you implement cost-optimized real-time capabilities. There would generally be trade-offs, such as using a managed instance of Kafka versus hosting your own. In this case, using the managed version may allow the team to get to market quicker and forgo the maintenance on the Kafka clusters, but this may come at a high infrastructure cost. However, you’ll need to balance the total cost of ownership of such a component to see if the savings from engineering effort would offset the increased cost. This is just one example of the mindset that architects and developers should use when looking at how to optimize costs for these systems. Last but not least, let’s take a look at where these real-time systems are being used.
Case studies and real-world applications
Given the prevalence of real-time applications in today’s world, we may not fully recognize the various areas where we encounter these capabilities daily. Real-time software architecture drives numerous business applications in various industries, such as:
E-commerce: Dynamic pricing and inventory
Modern e-commerce platforms use real-time architecture to optimize customer experience and revenue.
Why real-time is required: Product pricing adjusts based on demand, competitor pricing, and inventory levels. Available-to-promise inventory updates across all sales channels.
Technology used: Kafka for event streaming, Redis for in-memory data storage, and microservices for scalable processing.
Real-world example: Amazon’s real-time pricing and inventory management set the standard for the industry, allowing it to maximize revenue while keeping customers happy with accurate availability information.
Financial services: Payment processing
Payment systems process millions of transactions, with varying levels of complexity and regulatory checks, and with tight timing requirements.
Why real-time is required: Authorization, fraud detection, and settlement must be completed in milliseconds to seconds.
Tech used: In-memory computing grids, stream processing for fraud detection, active-active deployment for resilience.
Real-world example: Stripe’s payment infrastructure processes transactions in real-time across multiple payment methods and currencies, with sophisticated fraud detection that doesn’t add noticeable latency.
Media: Content personalization
Streaming platforms deliver personalized experiences through real-time systems, helping to drive user engagement and satisfaction.
Why real-time is required: Content recommendations update based on viewing behavior, A/B testing of UI elements occurs on-the-fly, and video quality adapts to network conditions.
Tech used: Event sourcing for user activity, machine learning pipelines for recommendation generation, CDN integration for content delivery.
Real-world example: Netflix’s recommendation engine processes viewing data in real-time to update content suggestions, reportedly saving them $1 billion annually through increased engagement.
B2B platforms: Supply chain management
Modern supply chains rely on real-time visibility and coordination to ensure operations are running smoothly and revenue is not impacted.
Why real-time is required: Inventory levels, shipment tracking, order status, and demand forecasting all update continuously.
Tech used: IoT data ingestion, event-driven microservices, real-time analytics dashboards.
Real-world example: Walmart’s supply chain system processes over a million customer transactions per hour, with real-time updates flowing to inventory management, forecasting, and replenishment systems.
These examples show how real-time software architecture delivers business value across different domains. As user expectations for responsiveness increase, the principles and patterns of real-time architecture will play an important role in enhancing digital experiences.
Using vFunction to build and improve real-time architectures
Achieving real-time performance often requires transitioning from monolithic applications to event-driven, microservices-based architectures. vFunction accelerates this application modernization process with targeted capabilities:
Eliminate architectural technical debt to improve performance and reliability vFunction uses data science and GenAI to identify hidden dependencies and bottlenecks, then generates precise, architecture-aware prompts to automatically remediate issues that impact latency and responsiveness.
Identify and extract modular services optimized for real-time performance, and automatically generate APIs and framework upgrades to support scalable modernization.
Modernize incrementally by prioritizing the components that matter most for real-time performance—vFunction guides you through gradual, low-risk transformation without the need for full rewrites.
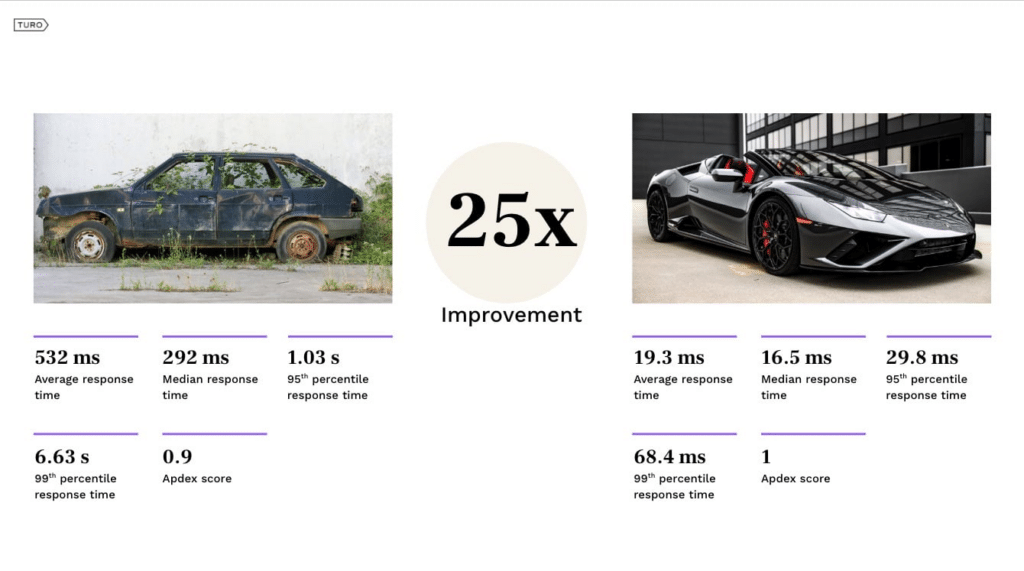
The Trend Micro case study illustrates how vFunction’s AI-driven platform facilitated the seamless transformation of monolithic Java applications into microservices. Similarly, vFunction supported Turo in reducing latency by transforming its monolithic application into microservices. This resulted in faster response times, improved sync times, and enhanced code deployment efficiency for Turo.
By providing data-driven architectural insights, vFunction helps organizations build and maintain the responsive, scalable systems that real-time applications demand.
Conclusion
Real-time software architecture has evolved from a niche need in embedded systems to a mainstream approach for modern applications. As businesses strive to deliver data-driven experiences, the ability to process and respond in real time has become a key competitive advantage.
This blog explored the fundamentals of real-time systems: their classification (hard, firm, soft), guiding principles, and key performance metrics like latency, jitter, throughput, and recovery time.
Modern real-time architectures rely on technologies like event streaming platforms (Kafka), in-memory data stores, reactive programming models, and cloud-native patterns. When combined thoughtfully, these components enable scalable systems that meet strict timing guarantees. But great software isn’t just about the technology, it’s about how it’s architected.
To meet the demands of real-time systems, architects need continuous visibility into how applications are built and behave. vFunction surfaces architectural technical debt, identifies bottlenecks, and guides modernization—while enabling ongoing governance to monitor drift, enforce standards, and maintain performance over time.
Whether you’re migrating to microservices, meeting real-time SLAs, or preparing for growth, vFunction helps you move faster. Get in touch to see how architectural observability can help you build and maintain real-time software architecture that’s responsive, resilient, and ready to scale with your business.
The shift from monoliths to microservices is one of the biggest paradigm shifts in modern software development. This technical evolution has led to a fundamental reimagining of how applications are designed, built, and maintained. This shift offers advantages for organizations using Microsoft’s .NET platform while presenting some unique implementation challenges.
Using a microservices architecture isn’t new. Companies like Netflix, Amazon, and Uber have famously used this approach to scale their applications to millions of users. But what has changed is the availability of the tools and frameworks to implement microservices effectively. .NET Core 1.0 (now just .NET) marked the release of a cross-platform, high-performance version of .NET perfect for building microservices.
In this guide, we will cover the key concepts, components, and implementation strategies of .NET microservices architecture. We’ll look at why organizations are moving to this architectural style, how various .NET frameworks (not to be confused with .NET Framework) support microservices, and practical approaches to designing, building, and running microservices-based systems. Let’s begin by looking at things starting at the ground level, digging further into what microservices are.
What is microservices architecture?
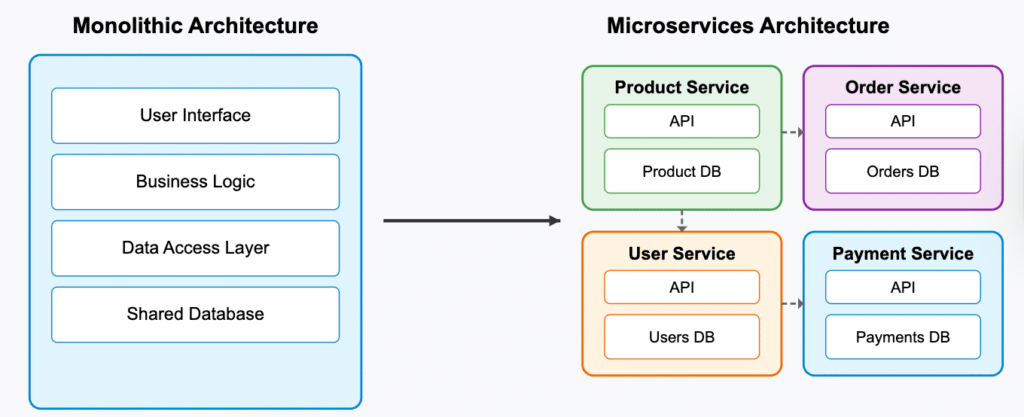
At its core, microservices architecture is an approach to developing applications as a collection of small, independent services. Unlike monolithic applications, where all functionality is bundled into a single codebase, microservices break applications into smaller components that communicate through well-defined APIs.
From monoliths to microservices
Traditional monolithic applications bundle all functionality into a single deployment unit. The entire application shares a single codebase and database, and any change to one part of the application requires rebuilding and redeploying the whole system. While this simplifies initial development, it becomes a problem as applications grow in size and complexity.
Consider a typical e-commerce application built as a monolith. The product catalog, shopping cart, order processing, user management, and payment processing all exist in a single codebase. A small change to the payment processing module requires testing and redeploying the entire application, increasing risk and slowing down the development cycle.
Microservices address these challenges by breaking the application into independent services, each focused on a specific business capability. Each service has its own codebase, potentially its own database, and an independent deployment pipeline. The key benefits of this isolation are that it allows teams to work independently, deploy frequently, and scale services based on specific requirements and usage rather than scaling the entire application.
Now, when it comes to deciding on what to build your microservices with, there are a massive number of languages and frameworks that can be used. However, if you’re here, you likely have already decided to move forward with .NET (and what a great choice that is!).
Choosing the right .NET tech stack
Although .NET existed well before the advent of microservices, the .NET ecosystem offers several advantages that make it perfect for microservices development. Much of the core building blocks of .NET lend themselves well to building scalable microservices easily. Let’s look at some of the highlights around why .NET makes a really great choice for developers and architects looking to build microservices:
Cross-platform
With .NET Core (now just .NET), Microsoft turned a Windows-only framework into a cross-platform technology. This is critical for microservices, which often need to run on different platforms, from Windows servers to Linux containers.
.NET applications now run on Windows, Linux, and macOS, giving organizations flexibility in their deployment environments. This cross-platform capability allows teams to choose the most appropriate and cost-effective hosting environment for each microservice, whether it’s Windows IIS, Linux with Nginx, or containerized environments orchestrated by Kubernetes. Of course, the ability to specifically support Linux gives those working in .NET the ability to use industry-preferred Linux containers that are liked for their small size and cost efficiency.
Performance optimizations
Performance is key for microservices, which often need to handle high throughput with minimal resource consumption. .NET has had significant performance optimizations over the years and is one of the fastest web frameworks available.
The ASP.NET Core framework includes high-performance middleware for building web APIs, essential for service-to-service communication in microservices architectures. The Kestrel web server included with ASP.NET Core is a lightweight, cross-platform web server that can handle thousands of requests per second with low latency.
Additionally, .NET’s garbage collection has been refined to minimize pauses, critical for services that need consistent response times. Just in time (JIT) compilation provides runtime optimizations, while ahead of time (AOT) compilation available in newer .NET versions reduces startup time — a big win for containerized microservices that may be created and destroyed frequently.
Containerization support
Modern microservices deployments frequently use containerization technologies like Docker to ensure consistency, scalability, and portability. .NET offers full support for containerization, including official Docker images tailored to different .NET versions and runtime configurations, making it easier to build, ship, and run .NET microservices in any environment.
The framework’s small footprint makes it perfect for containerized deployments. A minimal ASP.NET Core API can be packaged into a Docker image of less than 100MB, reducing resource usage and startup times. Microsoft provides optimized container images based on Alpine Linux, further reducing the size of containerized .NET applications.
Rich ecosystem
One thing that .NET developers love is the massive ecosystem of libraries and tools at their disposal. When it comes to building microservices, this is no exception.
For example, ASP.NET Core provides a great framework for building RESTful APIs and gRPC services, essential for inter-service communication between microservices. Entity Framework Core offers a flexible object relational mapping solution for data access with support for multiple database providers. These two examples are just two of thousands of popular libraries and tools available directly from Microsoft and other independent companies and developers.
Core principles of a microservices architecture
Successful microservices implementations follow several key principles that guide architectural decisions. These principles are what set microservices apart from other types of large, monolithic services that we saw dominate the past. Let’s take a look at three of the most important principles for developers and architects to follow as they design and build microservices.
Single responsibility principle
Each microservice should focus on a specific business capability, following the single responsibility principle from object-oriented design. This allows services to be developed, tested, and deployed independently.
For example, let’s imagine a hotel booking system. Instead of building a monolithic application that handles everything from room availability to payment processing, a microservices approach would separate these concerns into independent services. A room inventory service would manage room availability, a booking service would handle reservations, a payment service would process transactions, and a notification service would communicate with customers.
This separation allows specialized teams to own specific services and focus on the angles that are of highest concern. This might mean that the team responsible for the payment service would focus on compliance and integrating with different payment vendors, while the team managing the room inventory service would optimize for high-volume read operations.
Domain-driven design
Domain-driven design (DDD), a popular approach to creating microservices, provides a useful framework for identifying service boundaries within a microservices architecture. By modeling bounded contexts, teams can design services that align with business domains rather than technical concerns.
DDD encourages collaboration between domain experts and developers to create a shared understanding of the problem domain. This shared understanding helps identify natural boundaries within the domain, which often translate to microservice boundaries.
For example, in an insurance system, policy management and claims processing are distinct, bounded contexts. Each context has its own vocabulary, rules, and processes. This would mean that splitting these two functionalities into their own domains and subsequent implementations would be a good way to build them out. By aligning microservices with bounded contexts like this, the architecture becomes more intuitive and resilient to change.
Decentralized data management
Unlike monolithic applications that typically share a single database, each microservice in a well-designed system manages its own data. This decentralization of data has several benefits for teams.
First, it allows each service to choose the most appropriate data storage technology. A product catalog service might use a document database like MongoDB for flexible schema, while an order processing service might use a relational database like SQL Server for transaction support. This helps enable independent scaling of data storage as well. It allows a frequently accessed service to scale its database without affecting other services.
Secondly, it enforces service independence by preventing services from directly accessing each other’s databases. Services must use well-defined APIs to request data from other services, reinforcing the boundaries between services. Now, this doesn’t mean that there is necessarily a physically separate database, but there might be logical separations between the tables that one service uses. So multiple services still may use a single physical database, but with governance and structure in place to keep concerns separated.
One of the challenges here is that decentralization introduces potential issues with data consistency and integrity. Transactions that span multiple services that use completely independent databases can’t rely on database transactions. Instead, they must use patterns like Sagas or eventual consistency to maintain data integrity across service boundaries.
With these principles and challenges in mind, how does one design and implement a microservices architecture within .NET? That’s exactly what we will cover next!
Designing a .NET microservices system
Agnostic to the framework or library being used, designing a microservices system involves several key considerations. Building on the principles above, here’s how you would go about designing your microservices:
Service boundaries
Defining service boundaries is the most critical architectural decision in a microservices system. Services that are too large defeat the purpose of microservices, while services that are too granular can introduce unnecessary complexity.
Several approaches can guide the identification of service boundaries:
Domain-driven design: As mentioned earlier, DDD’s bounded contexts provide natural service boundaries. Each bounded context encapsulates a specific aspect of the domain with its own ubiquitous language and business logic.
Business capability analysis: Organizing services around business capabilities ensures that the architecture aligns with organizational structure. Each service corresponds to a business function like order management, inventory control, or customer support.
Data cohesion: Services that operate on the same data should be grouped together. This approach minimizes the need for distributed transactions and reduces the complexity of maintaining data consistency.
In practice, service boundaries often evolve over time. It’s common to start with larger services and gradually refine them as understanding of the domain improves. The key is to design for change, anticipating that service boundaries will evolve as requirements change.
API gateway pattern
As microservices are heavily dependent on APIs of various types, API gateways are generally recommended as a core part of the system’s architecture. An API gateway serves as the single entry point for client applications, routing requests to appropriate microservices.
This pattern provides several benefits:
Simplified client interaction: Clients interact with a single API gateway rather than directly with multiple microservices. This simplification reduces the complexity of client applications and provides a consistent API surface.
Cross-cutting concerns: The gateway can handle cross-cutting concerns like authentication, authorization, rate limiting, and request logging. Implementing these concerns at the gateway level ensures consistent application across all services.
Protocol translation: The gateway can translate between client-friendly protocols (like HTTP/JSON) and internal service protocols (like gRPC or messaging). This translation, also referred to as a request or response transformation, allows internal services to use the most efficient communication mechanisms without affecting client applications.
Response aggregation: The gateway can aggregate responses from multiple services, reducing the number of round-trips client applications require. This aggregation is particularly valuable for mobile clients where network latency and battery usage are concerns.
In the .NET ecosystem, several options exist for implementing API gateways, including the always popular Azure API Management platform or other non-.NET gateways such as Kong, AWS API Gateway, Tyk, or newer entrants like Zuplo.
Communication patterns
Depending on the service, you’ll also need to decide how the microservices will communicate with one another. Microservices can communicate using various patterns, each with its own trade-offs, including:
Synchronous communication: Services communicate directly through HTTP/HTTPS requests, waiting for responses before proceeding. This is simple to implement but can introduce coupling and reduce resilience. If a downstream service is slow or unavailable, the calling service is affected.
Asynchronous communication: Services communicate through messaging systems like RabbitMQ, Azure Service Bus, or Kafka. Messages are published to topics or queues, and interested services subscribe to receive them. This decouples services temporally, allowing them to process messages at their own pace.
Event-driven architecture: Services publish events when significant state changes occur, and interested services react to these events. This enables loose coupling and flexibility, but can make it harder to understand the overall system behavior.
gRPC: This high-performance RPC framework is well-suited for service-to-service communication. It uses Protocol Buffers for efficient serialization and HTTP/2 for transport, resulting in lower latency and smaller payloads compared to traditional REST/JSON approaches.
The choice of communication pattern depends on the specific requirements of each interaction. Many successful microservices systems use a combination of patterns, choosing the most appropriate one for each interaction.
.NET microservices examples
One of the best ways to understand how to apply the principles of microservices to your own use case is to dig into some examples. Let’s look at examples of .NET microservices in real-world scenarios:
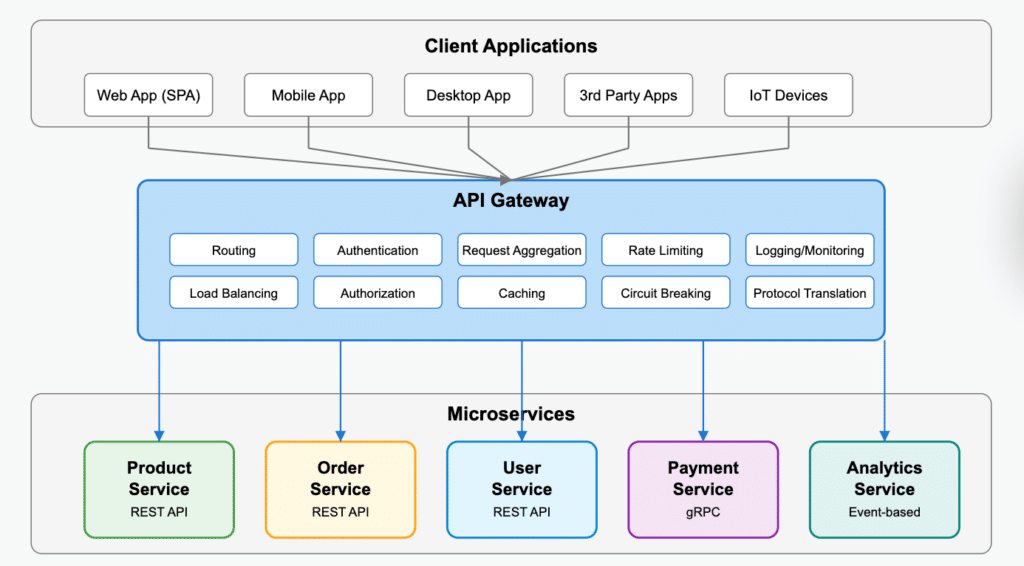
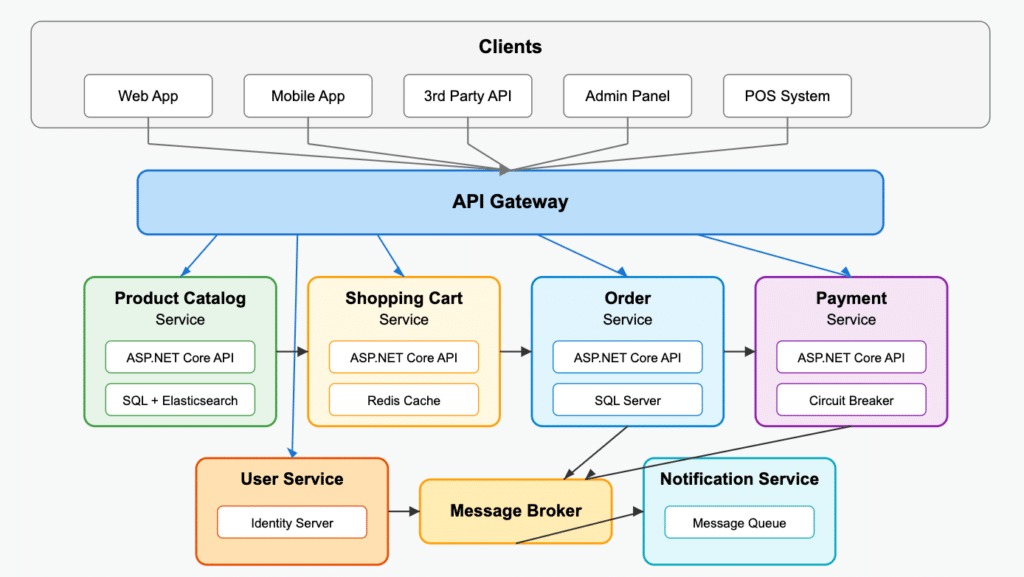
E-commerce platform
A modern e-commerce platform built with .NET microservices might include:
Let’s quickly break down what each service is doing and how it works within the overall application:
Product Catalog service: Manages product information, categories, and search. Implemented as an ASP.NET Core API with Entity Framework Core for data access and Elasticsearch for full-text search.
Order service: Uses the Saga pattern to coordinate transactions across services.
Payment service: Integrates with payment gateways and handles transactions. Uses circuit breakers to handle payment gateway outages.
User service: Manages user profiles, authentication, and authorization. It uses an identity server for OAuth2/OpenID Connect.
Notification service: Sends emails, SMS, and push notifications to users. Subscribes to events from other services and uses message queues to handle notification delivery asynchronously.
These services talk to each other using a mix of synchronous REST APIs for query operations and asynchronous messaging for state changes. An API gateway routes client requests to the correct services and handles authentication.
The services are containerized using Docker and deployed to a Kubernetes cluster, with separate deployments for each service. Azure Application Insights provides distributed tracing and monitoring, with custom dashboards for service health and performance metrics.
Banking system
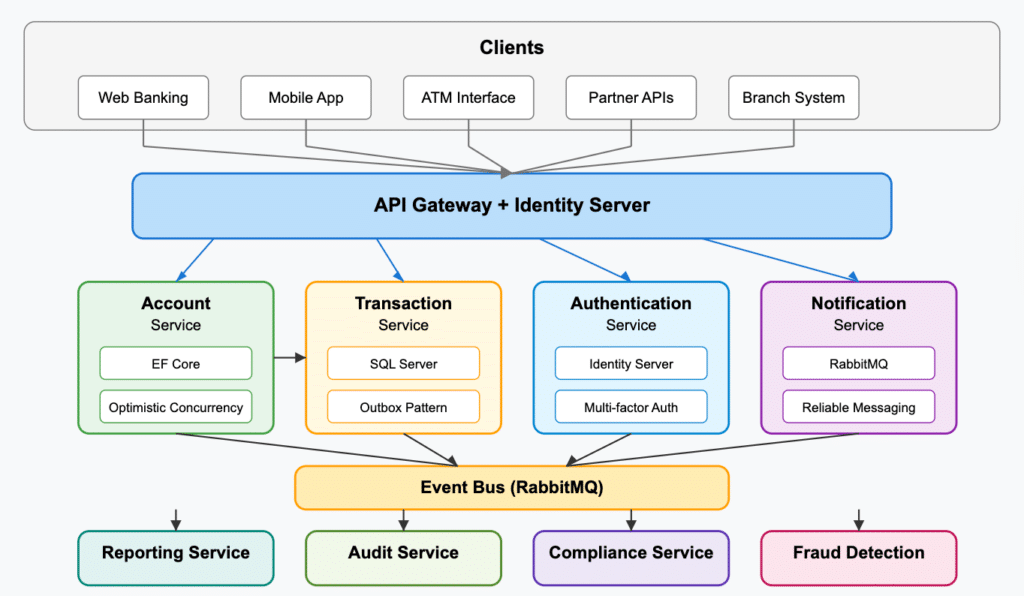
Now, let’s imagine a banking system built with .NET. In this type of application, you’d expect to see something along the lines of this:
Here, we have a few key services that serve web, mobile, and branch banking, as well as a few other clients. The services themselves include an:
Account service: Manages customer accounts and balances. Uses SQL Server with Entity Framework Core for data access and optimistic concurrency to handle concurrent transactions.
Transaction service: Processes deposits, withdrawals, and transfers. Uses the outbox pattern to ensure reliable message publishing during transactions.
Authentication service: Handles user authentication and authorization with multi-factor authentication. Uses Identity Server for security token issuance.
Notification service: Sends transaction notifications and account alerts. Uses queuing to handle notification delivery even during service outages.
Reporting service: Generates financial reports and analytics. Uses a separate read model for reporting queries, the CQRS pattern.
Transactional consistency is key. The system uses database transactions within services and compensating transactions across services to ensure data integrity. Event sourcing captures all state changes as a series of events for regulatory compliance.
These two examples show a simple but complete view of what microservices architecture looks like when they are designed and built with best practices in mind. Once built, the microservices need to be deployed. Luckily, with the rise of microservices, complementary technologies have also risen up to accommodate the speed and complexity that deploying microservices brings.
Deployment and orchestration
Deployment and orchestration are key to managing microservices at scale. Containerization is probably the single most critical technology that has enabled microservices to be possible at scale. The two main technologies used for this are Docker containers and Kubernetes for orchestration.
Docker
Docker provides a lightweight and consistent way to package and deploy microservices. Each service is packaged as a Docker image containing the application and its dependencies. This containerization ensures consistent behavior across environments from development to production.
For .NET microservices, multi-stage Docker builds create efficient images by separating the build environment from the runtime environment. The build stage compiles the application using the .NET SDK, while the runtime stage includes only the compiled application and the .NET runtime. This results in smaller, more secure images that only contain what’s needed to run the application. It also improves build caching, reducing build times for incremental changes.
Kubernetes
While Docker provides containerization, Kubernetes handles orchestration. This includes managing the deployment, scaling, and operation of containers across a cluster of hosts. Kubernetes has several features that are particularly useful for microservices:
Declarative deployments: Kubernetes deployments describe the desired state of services (using a YAML or JSON file), including the number of replicas, resource requirements, and update strategies. Kubernetes will automatically reconcile the actual state with the desired state.
Service discovery: Kubernetes services provide stable network endpoints for microservices, abstracting away the details of which pods are running the service. This abstraction allows services to communicate with each other without knowing their physical locations.
Horizontal scaling: Kubernetes can scale services based on metrics like CPU utilization or request rate. This automatic scaling ensures efficient resource usage while maintaining performance under varying loads.
Rolling updates: Kubernetes supports rolling updates, gradually replacing old versions of services with new ones. This gradual replacement minimizes downtime and allows for safe, incremental updates.
Health checks: Kubernetes uses liveness and readiness probes to monitor service health. Liveness probes detect crashed services, while readiness probes determine when services are ready to accept traffic. For .NET microservices, the ASP.NET Core Health Checks middleware integrates seamlessly with Kubernetes health probes.
With these two technologies, many of the microservices that power applications we use every day are built and deployed. They help to make the complexity of deploying microservices manageable and feasible at scale. Even with the relative stability and ease they can bring, there is still the need to monitor and observe how the services are performing and if they are in a healthy state. Monitoring and observability are extremely critical for deployed microservices.
Monitoring and observability
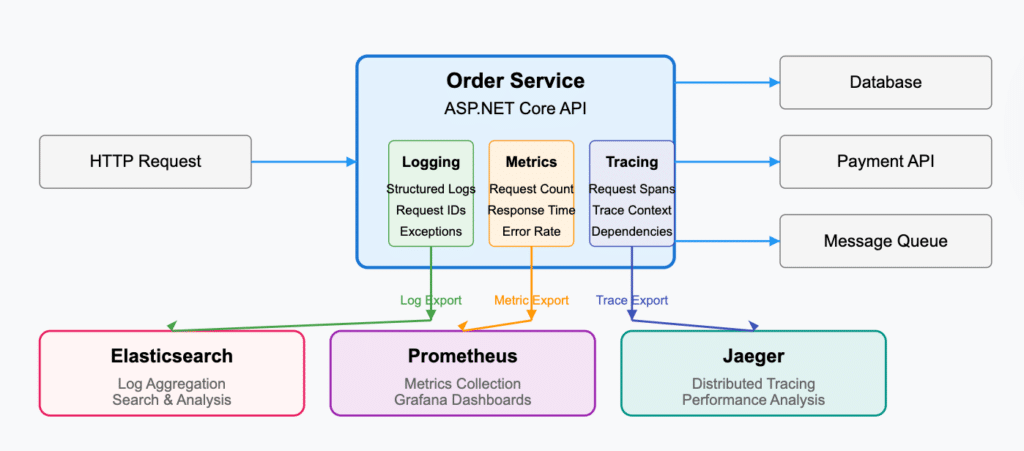
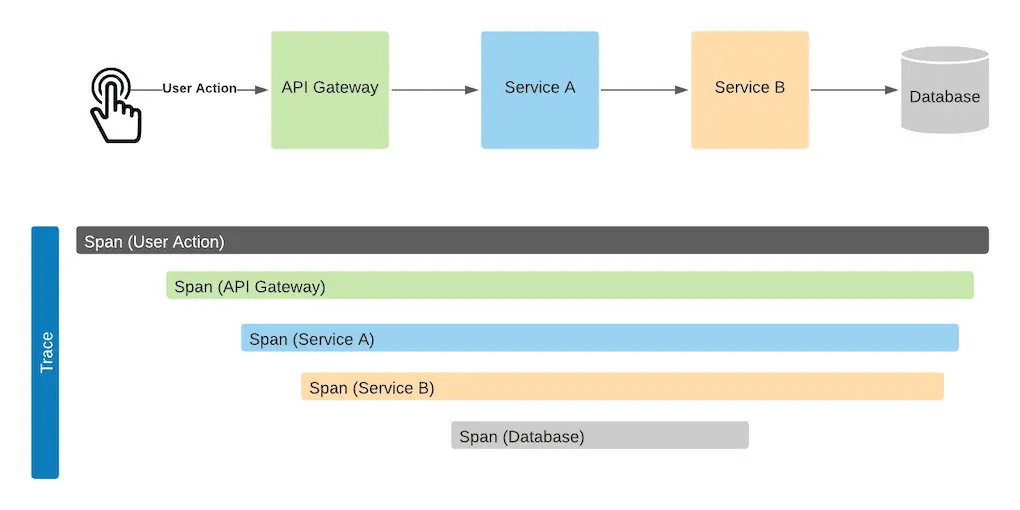
Monitoring and observability are key to running healthy microservices systems. The distributed nature of microservices introduces complexity in tracking requests, understanding system behavior, and diagnosing issues. Traditional monitoring and alerting don’t quite meet the needs of the microservices world, so many specialized tools and approaches have been added to the arsenal to assist developers and support teams. The pillars of observability must be applied to every microservice to fully understand the context of the system. For example, an Order service covered by observability may look like this:
Distributed tracing
In a microservices architecture, a single user request often spans multiple services. Distributed tracing tracks these requests as they flow through the system, providing visibility into performance bottlenecks and failure points.
OpenTelemetry, a Cloud Native Computing Foundation (CNCF) project, provides a standardized approach to distributed tracing in .NET applications. By instrumenting services with OpenTelemetry, developers can collect traces that follow requests across service boundaries.
Adding these capabilities is actually quite simple when it comes to services written in .NET. The preferred method is auto-instrumentation, which, with little or no code changes, can collect OpenTelemetry data throughout an application. The other method, which tends to be more customizable but also more complex, is to implement tracing directly in the code. For example, the following code shows how to configure OpenTelemetry in an ASP.NET Core service:
If you need something a bit more tailored to a specific service, here’s how a typical controller (one for a fictitious OrderController) might include manual instrumentation for more detailed tracing:
[ApiController]
[Route("api/[controller]")]
public class OrdersController : ControllerBase
{
private readonly IOrderService _orderService;
private readonly ILogger<OrdersController> _logger;
private readonly ActivitySource _activitySource;
public OrdersController(
IOrderService orderService,
ILogger<OrdersController> logger)
{
_orderService = orderService;
_logger = logger;
_activitySource = new ActivitySource("OrdersAPI");
}
[HttpGet("{id}")]
public async Task<ActionResult<OrderDto>> GetOrder(Guid id)
{
// Create a new activity (span) for this operation
using var activity = _activitySource.StartActivity("GetOrder");
activity?.SetTag("orderId", id);
try
{
var order = await _orderService.GetOrderAsync(id);
if (order == null)
{
activity?.SetTag("error", true);
activity?.SetTag("errorType", "OrderNotFound");
return NotFound();
}
activity?.SetTag("orderStatus", order.Status);
return Ok(order);
}
catch (Exception ex)
{
// Track exception in the span
activity?.SetTag("error", true);
activity?.SetTag("exception", ex.ToString());
_logger.LogError(ex, "Error retrieving order {OrderId}", id);
throw;
}
}
}
In the above, more detailed code, you can see that each step within the controller is being captured within the span. Without going into too much detail, here is a quick visualization to help understand how OpenTelemetry would capture different actions through a system:
Spans help you understand how requests flow through a system by capturing critical performance and context information. Credit:Hackage.haskell.org
Traces collected by OpenTelemetry can be visualized and analyzed using tools like Jaeger or Zipkin. These tools provide insights into service dependencies, request latency, and error rates, helping developers understand how requests flow through the system.
Centralized logging
Centralized logging aggregates logs from all services into a single searchable repository. This centralization is key to troubleshooting issues that span multiple services.
In .NET applications, there are many different libraries that provide structured logging with support for various “sinks” that can send logs to centralized systems. The following code shows an example using Serilog to write logs to the console and Elasticsearch:
Once logs are centralized, tools like Kibana provide powerful search and visualization capabilities. Developers can query logs across services, create dashboards for monitoring specific metrics, and set up alerts for anomalous conditions.
Health checks
Health checks provide real-time information about service status, essential for automated monitoring and orchestration systems. ASP.NET Core includes built-in health check middleware that integrates with various monitoring systems.
Health checks can verify internal service state, database connectivity, and dependencies on other services. The following code is a figurative example that configures health checks for an order service:
When added to the source code, these health checks can be monitored by orchestration platforms like Kubernetes, which can automatically restart services that fail health checks. They can also be consumed by monitoring systems like Prometheus or Azure Monitor to see service health over time.
How does vFunction help build and scale .NET microservices?
When it comes to designing and implementing microservices, there are a lot of factors to take into consideration. Much of the success of microservices depends heavily on how they are architected. Luckily, with vFunction, there is an easy way to make sure that you are following best practices and designing microservices to be scalable and resilient.
In regard to microservices, vFunction stands out in three key areas. First, it helps teams transition from monolithic codebases to more modular, microservices-based architectures. Second, for those building or managing microservices, vFunction provides deep architectural observability—revealing the current structure of your system through analysis and live documentation—flagging any drift from your intended design. Third, vFunction enables architectural governance, allowing teams to define and enforce architectural rules that prevent sprawl, maintain consistency, and keep services aligned with organizational standards. Let’s dig into the specifics.
Converting your monolithic applications to microservices
However, adopting microservices involves effort. It requires careful consideration of design, architecture, technology, and communication. Tackling complex technical challenges manually is risky and generally advised against.
vFunction understands the constraints of costly, time-consuming, and risky manual app modernization. To counter this, vFunction’s architectural observability platform automates cloud-native modernization.
Once your team decomposes a monolith with vFunction, it’s easy to automate extraction to a modern platform.
By combining automation, AI, and data science, vFunction helps teams break down complex .NET monoliths into manageable microservices—making application modernization smarter and significantly less risky. It’s designed to support real-world modernization efforts in a way that’s both practical and effective.
Its governance features set architectural guardrails, keeping microservices aligned with your goals. This enables faster development, improved reliability, and a streamlined approach to scaling microservices with confidence.
vFunction supports governance for distributed architectures, such as microservices, to help teams move fast while staying within the desired architecture framework.
To see how top companies use vFunction to manage their microservices-based applications, visit our governance page. You’ll learn how easy it is to transform your legacy apps or complex microservices into streamlined, high-performing applications and keep them that way.
Conclusion
.NET microservices are a powerful way to build scalable, maintainable, and resilient applications. With .NET’s cross-platform capabilities, performance optimisations, and rich ecosystem, development teams can deliver business value quickly and reliably.
The journey to microservices isn’t without challenges. It requires careful design, robust DevOps, and a deep understanding of distributed systems. However, with the right approach and tools, .NET microservices can change how you build and deliver software.As you start your microservices journey, remember that successful implementations often start small. Start with a well-defined bounded context, establish solid DevOps, and incrementally expand your microservices architecture as you gain experience and confidence. If you need help with getting started and staying on the right path, many different tools exist to help developers and architects. One of the best tools for organizations making the move to microservices is vFunction’s architectural observability platform, which is tailored to helping organizations efficiently build, migrate, and maintain microservices at scale. Want to learn more about how vFunction can help with developing .NET microservices? Contact our team of experts today.
Traditional application performance monitoring (APM) tools survey CPU, memory, p99 latency… and leave you to connect the dots. vFunction’s anomaly TODOs (i.e., tasks based on specific anomalous architecture events) are part of our broader product release. They flip the lens on typical APM monitoring by beginning with application behavior (flows, paths, errors and usage). The result? Early, architect-level alerts instead of dashboard noise.
These TODOs that detect anomalies introduce a new layer of architectural observability for distributed applications by detecting meaningful deviations in behavior like spikes in flow usage, misrouted paths, error surges and performance drops. Unlike traditional APMs that fixate on system-level metrics, vFunction starts with what matters most: application behavior. User experience, architectural health and early warning signals are all rooted in how flows behave not in raw CPU or memory numbers. By focusing first on behavioral anomalies and then correlating them with more signals like latency, vFunction delivers targeted, architecture-aware insights that surface real problems faster.
User experience, architectural health and early warning signals are all rooted in how flows behave not in raw CPU or memory numbers.
Every detected anomaly is surfaced as a TODO, an actionable, traceable and context-rich alert that helps architects and developers maintain quality and velocity. These TODOs integrate directly with tools like Jira and Azure DevOps, automatically opening tickets so anomalies are tracked, prioritized and resolved within your existing workflows.
Why use anomaly TODOs?
Early detection of architectural drift
Catch issues while they’re still harmless or slow down delivery. If a once-isolated service suddenly leans on another microservice, this could indicate emerging coupling or a missed interface contract which are signs of architectural drift.
Actionable signals
Each anomaly is represented as a TODO, making it easy to investigate, track, assign and resolve directly from vFunction or your existing workflows by integrating with tools like Jira and Azure DevOps.
Four architecture anomalies
Let’s review four architecture anomalies now detected by vFunction TODOs.
1. Usage anomaly — Behavioral changes in flow distribution
What it detects A statistically significant spike or dip in calls to a specific flow (Z-score ≥ 3 on a baseline). These shifts are identified by analyzing historical flow activity and flagging deviations from established usage patterns.
Why it matters Usage anomalies can surface silent UI changes, new feature rollouts, deprecated logic still being triggered or unexpected shifts in user behavior. Things that otherwise might get missed.
Why use it
Validate feature adoption.
Detect traffic misrouting or dead code.
Confirm or investigate A/B test impact.
2. Path anomaly — Flow routing irregularities
What it detects
Significant deviations in internal flow behavior, such as calls being routed to unexpected endpoints or shifts in backend execution paths. These changes often signal deeper architectural or operational issues.
Why it matters
Path anomalies may point to architectural drift, routing bugs, unintended failover behavior, or misuse of caching layers issues that can quietly degrade system performance or reliability over time.
Why use it
Identify unexpected path dominance or fallback logic.
Catch misrouting caused by misconfigurations.
Reveal hidden service coupling or brittle integrations.
3. Error rate anomaly — Error spikes in flows
What it detects
A sudden surge in failed calls within a specific flow, flagged by analyzing error rate deviations from historical baselines.
Why it matters
These anomalies can reveal regressions, deployment issues, misconfigurations or outages even before users report them.
Why use it
Catch critical issues early
Pinpoint regressions linked to recent changes
Accelerate root cause analysis
4. Performance anomaly — Latency and resource utilization spikes
What it detects
Unexpected spikes in flow response times or system resource usage like CPU and memory beyond the normal baseline operating variability.
Why it matters
These anomalies signal performance bottlenecks, inefficient code paths, overloaded infrastructure, or lagging third-party dependencies—issues that can quietly erode user experience and system stability.
Why use it
Detect performance regressions in production
Monitor the impact of code or infrastructure changes
Proactively surface scalability limits before they hit users
Conclusion
vFunction’s TODOs for architecture anomalies act as a real-time early warning system for usage shifts, regressions and architectural drift. Rooted in behavior, not just raw metrics, they surface as actionable, context-rich tasks. That means faster diagnosis, confident decisions and resolution before issues spiral into technical debt.
Ready to stay ahead of application issues caused by anomalies? Contact us to see how vFunction’s new anomaly detection TODOs help you spot issues early, take decisive action, and keep your applications resilient and scalable.
Technical debt, a term often misunderstood and feared by developers and stakeholders, arises when development teams take shortcuts to meet rapid innovation demands and deadlines. These short-term fixes, while beneficial initially, accrue over time, slowing down future development and making it more costly and complex, akin to financial debt’s accumulating interest.
In this post, we will dive into the details of technical debt: what it is, where it comes from, how to identify it, and most importantly, how to reduce and manage it. Let’s start with a detailed examination of technical debt and its various forms.
What is technical debt?
Technical debt is the future cost of using the quick and dirty approach to software development instead of a more pragmatic, sustainable, and well-thought-out approach. Ward Cunningham first coined this concept, which highlights the trade-off between speedy delivery and code quality. When we take shortcuts to meet requirements, we incur a debt that will need to be “paid back” later. Paying back this debt usually entails more work in the long run, just like financial debt accrues interest. The repayment often manifests as refactoring, bug fixes, more maintenance, and slower innovation. That being said, experts on the subject tend to have varying opinions on what technical debt is and its causes/motivations.
When interpreting technical debt, Martin Fowler, aka Uncle Bob, a pundit in the topic of software development, calls it “cruft.” His view focuses on internal quality deficiencies that make changing and extending a system harder. The extra effort to add new features is the interest on this debt. On the other hand, Steve McConnell, an internationally acclaimed expert in software development practices, categorizes technical debt into two types: intentional and unintentional.
Intentional Technical Debt is a conscious and strategic decision to optimize for the present, often documented and scheduled for refactoring. An example of this is using a simpler framework with known limitations to meet a tight deadline, with the understanding that it will be revisited later. Unintentional Technical Debt results from poor design, lack of knowledge, or not following the development standards, often without a plan to fix it.
Now, it’s extremely important to distinguish technical debt from just writing bad code. As Martin Fowler puts it, a “mess is not a technical debt.” Technical debt decisions usually stem from genuine project limitations and can be short-term assets, unlike a mess, which arises from laziness or a significant knowledge gap, increasing complexity without offering benefits or justifications for its causes.
Forms of technical debt
Although we often think of technical debt as being rooted in an application’s code, it can actually manifest in many different forms. It includes:
Build debt: issues making the build process harder
Design debt: flaws in the user interface or user experience
Documentation debt: missing or outdated documentation
Infrastructure debt: problems with the underlying systems
People debt: lack of necessary skills in the team
Emerging as a new kind of technical backlog is AI debt, which, as Eric Johnson of PagerDuty highlights, involves complexities beyond code, spanning the whole data and model governance life cycle. Amir Rapson from vFunction points out that AI development can exacerbate technical debt through microservices sprawl, architectural drift, and hidden dependencies, severely affecting performance and scalability. Understanding and managing different forms of technical debt is crucial for prevention and maintaining system integrity.
Why technical debt accumulates
Technical debt exists in almost every application, accumulating due to many factors throughout the software development lifecycle (SDLC).
Deadline pressure
One of the most common underlying reasons is deadline pressure. Tight project schedules or urgent demands can force developers to take shortcuts and implement less-than-ideal solutions to meet the deadline. This often results in code that is not as clean, efficient, or thoroughly tested as it should be, letting certain edge-case scenarios slip through unhandled.
Lack of experience and knowledge
Lack of experience or insufficient developer knowledge can be a big contributor to technical debt. Inexperienced developers might write code that is not efficient, maintainable, or aligned with best practices. Similarly, a lack of understanding of design principles can lead to architectural flaws that are costly to fix later.
Changing scope and unclear requirements
Changing scope and unclear project requirements are other major sources of technical debt. If project requirements shift mid-development, even well-designed code might become obsolete or incompatible and need to be fixed with quick fixes and workarounds. Ambiguous or incomplete requirements can lead to suboptimal solutions and rework.
Temporary solutions
Often, development teams implement temporary solutions or quick fixes to address immediate issues, intending to revisit them later. However, these “temporary” fixes usually stay in the codebase and accrue interest in the form of increased complexity and potential bugs. A fellow developer accurately stated, “Later means never,” a sentiment that resonates deeply for its truth.
Code quality and standards
Neglecting code quality and standards leads to hard-to-read and maintain code, increasing errors and hindering future development.
Code reviews can be a great way to fight back against this, but we will cover that later!
Outdated technologies and inadequate testing
Using outdated technologies and deferring upgrades can create a lot of technical debt. Obsolete or deprecated technologies are harder to maintain and integrate with new solutions and often pose security vulnerabilities. Similarly, inadequate testing practices like incomplete test suites, truncated testing, or skipping testing for convenience can lead to undetected bugs and vulnerabilities that will cause future problems and, once again, require rework.
Intentional vs. unintentional
Finally, it’s essential to remember the difference between intentional and unintentional technical debt. While intentional debt is a conscious trade-off, unintentional debt is often due to oversight or lack of awareness. I would say that most of the time, technical debt is unintentional. However, intentional technical debt does have its place in specific situations. In these cases, it’s good to document it and get agreement from all parties that it’s okay for now, but needs to be improved later and not lost track of.
Although other causes can contribute to technical debt, the ones above cover the bulk of the causes for it. Since much of the accumulated technical debt is unintentional, knowing how to identify it is extremely critical.
Identifying technical debt
To fix an issue, you first need to identify it. In essence, uncovering technical debt is the first and most essential step toward managing and reducing it. While detecting technical debt can vary in difficulty, there are several clear indicators and methods teams can use to surface and track it effectively. Leveraging these tools and signals enables development teams to uncover weak points in their codebase and processes, so they can start addressing them or, at the very least, monitor them.
Signs and indicators
As development progresses, certain red flags can signal the presence of technical debt. If you’re beginning to feel like your project is slowing down or becoming harder to maintain, here are a few signs worth investigating:
Slower development cycles and increased bugs: A growing web of complexity makes adding new features more time-consuming and error-prone.
Inadequate documentation: Incomplete documentation often reflects rushed or ad-hoc development and will increase future maintenance costs.
Use of outdated technologies: Relying on deprecated frameworks or libraries introduces compatibility, maintenance, and security challenges.
Delays in time-to-market: Teams spend more time working around fragile or tangled code, which slows down delivery.
Code smells: Long methods, duplicated code, or high complexity are all indicators of poor design that can accumulate debt.
Excessive unplanned or defect-related work: High volumes of reactive work often point to underlying systemic issues in the codebase.
Methods and tools
Beyond qualitative signs, several methods and tools can help you actively identify and quantify technical debt:
Code reviews: Peer reviews catch issues early and help enforce quality standards before problems become embedded in the system.
Developer input: Your dev team often knows exactly where the pain points lie. Encourage open dialogue about areas needing cleanup or improvement.
Stakeholder feedback: Reports of poor performance or delays in feature delivery can signal tech debt. Include BAT (Business Acceptance Testing) cycles to capture this feedback.
Static analysis tools: Tools like SonarQube, CodeClimate, and ESLint highlight code smells, duplications, bugs, and security flaws.
Defect and bug tracking: Monitor metrics such as bug frequency, time-to-fix, and defect density to uncover problem areas.
Code churn analysis: Constant changes to the same areas of code suggest architectural instability or unclear ownership.
Dependency audits: Identify and update outdated or vulnerable libraries that could be holding the system back.
Technical debt backlog: Track technical debt using tools like Jira or GitHub Issues and integrate it into planning cycles like any other task.
By combining observational signs with hard data and feedback loops, teams gain a more complete picture of where technical debt lives—and how to start managing it effectively.
Strategies to reduce technical debt
Reducing technical debt is critical; prevention is key, but for existing debt, development teams must employ strategies to lessen its impact on the project.
Refactoring and testing
Refactoring, a common technique among developers, involves restructuring existing code without altering its external behavior. If you’re planning to refactor code or configuration, implementing automated testing is critical. Writing unit, integration, and end-to-end tests ensures the codebase works as expected and provides a safety net to developers when refactoring code.
Technology upgrades and documentation
Maintaining modernity in projects and enhancing documentation are key strategies for managing technical debt. Regular updates to libraries and frameworks reduce risks related to outdated dependencies, while staying informed about technology trends prevents security and compatibility issues. Leveraging the latest features also boosts performance.
Improved documentation is equally crucial. It provides clear insights into system functionalities and architectural decisions, helping both existing and new team members quickly understand and effectively work with the codebase. This clarity reduces errors, facilitates maintenance, and helps identify areas needing refactoring, thereby minimizing new technical debt. Together, keeping technologies up-to-date and ensuring holistic documentation not only enhances developer efficiency but also secures the project’s longevity and adaptability in a rapidly changing tech landscape.
Modularization and collaboration
The shift towards breaking monoliths into microservices highlights the benefits of modularization for scalable, maintainable systems. Modular architectures ease technical debt management by reducing tight coupling and simplifying complexity. This approach improves code organization, making strategies to mitigate technical debt more effective. Emphasizing code reviews and pair programming enhances code quality and preemptively addresses issues. Moreover, fostering collaborative practices encourages best practices, setting high standards within teams.
Backlog management and training
Systematically managing technical debt involves creating a backlog and ranking tasks by their impact and urgency. While business teams might view this differently, developers recognize the importance of treating technical debt on par with new features or bug fixes to tackle it proactively. Encouraging a “pay it forward” approach among developers, where they aim to improve the code with each change, effectively reduces technical debt over time. Additionally, investing in training and mentoring to address skill gaps and keeping the team updated on the latest technologies contributes to cleaner, more efficient code, preventing future debt.
Adopt AI into your workflows
Emerging technologies such as AI-powered testing and coding agents show promise in reducing technical debt, even as they continue to evolve. AI-powered testing tools can assist by automating many repetitive testing tasks and detecting issues early. AI coding agents can actually understand an entire code base and system (thanks to the ever-increasing size of context windows available on these platforms) and do a pretty solid job of refactoring with best practices in mind. Developers should exercise caution here as the technology is still in its infancy. This is especially true when letting AI agents run rampant throughout a codebase without human checks in place to ensure quality is still high. Outside of agentic coding, platforms like vFunction are also powered by AI and specifically built to help users identify areas where technical debt occurs, especially at the architecture level. We will cover more on the specifics of how it can help a bit later in the blog.
Implementing these practices provides a solid foundation for systematically managing technical debt. While project size and debt levels affect how quickly improvements may be seen, a major challenge for tech teams remains balancing the demand for new features with the need to reduce technical debt for smoother, more stable future development.
Balancing technical debt & feature development
Effectively managing technical debt involves striking the right balance between mitigating existing debt and rolling out new features essential for an application. It’s a challenging dilemma that many developers find themselves wrestling with. As technical debt mounts, the efficiency in delivering new features takes a hit. So, what’s the solution? Here are several strategies to elevate technical debt reduction to the same level of importance as feature development.
Prioritization and communication
Managing technical debt effectively involves:
Integrating maintainability: Treat codebase health as essential for faster, efficient development.
Employing metrics: Use data and tools to identify and measure technical debt.
Communicating with data: Present technical debt impacts to stakeholders in a data-driven manner for support.
Ensuring understanding: Align the team on the consequences of neglecting technical debt for feature delivery and bug resolution.
Integration and planning
For effective management of technical debt, consider these strategies:
Unified backlog: Merge new features and technical debt tasks into a single backlog for holistic prioritization. Make debt reduction a consistent part of the workflow, not an occasional task.
Regular discussion: Include technical debt as a recurring topic in stakeholder meetings and sprint planning.
Dedicated allocation: Reserve a fixed portion of each development cycle (10-20% or more, based on severity) for addressing technical debt.
Prioritization frameworks: Understand the impact of new features versus the long-term health of the product to aid decision-making. Utilize methods like MoSCoW to prioritize between technical debt and feature requests efficiently.
Stabilization sprints: Incorporate sprints focused solely on technical debt and bug fixes to ensure system stability.
Long-term best practices to prevent technical debt
Preventing technical debt is far more efficient than resolving it down the line. Proactively embed sustainable practices in your workflow that highlight quality, maintainability, and teamwork right from the beginning.
Code quality and reviews
A strong foundation of clean, modular, and well-structured code is essential. Following coding standards and enforcing regular code reviews means best practices are followed and domain knowledge is distributed across the team. Refactoring as part of your regular sprint cycle prevents small inefficiencies from snowballing into big problems.
Testing, documentation, and dependencies
Automated testing (unit, integration, end-to-end) gives you the confidence to refactor and deploy with reduced risk. Updating dependencies regularly helps to avoid security vulnerabilities, bugs, and compatibility issues down the line. Simplify code wherever possible; complex solutions may feel clever at the time, but tend to generate more debt. Clear documentation (architectural decisions, APIs, diagrams) helps to prevent knowledge loss and accelerates onboarding and debugging.
Tools, plan ahead, and culture
Integrate static analysis tools into your CI/CD pipeline to flag issues early and enforce consistency. Plan ahead and design for scalability from the start to avoid piling on technical debt and costly rework later. Just as important, create a culture where technical debt is openly discussed and developers feel responsible for the long-term health of the codebase. Document design decisions and agree on standards upfront to avoid chaos later.
CI/CD and cross-team collaboration
Continuous integration and delivery practices help to catch regressions quickly and keep quality high. Promote cross-team communication to break down silos and make sure everyone (developers, operations, QA and everyone in between) is aligned on goals and pain points. Invest in ongoing training and make time for learning to keep your team up to date with the latest patterns, tools, and techniques used within the application and codebase. Infrastructure-as-code, monitoring, and observability should also be used to help to uncover hidden areas of debt, especially in fast-scaling environments.
Integrating these practices into your workflow establishes a feedback loop that prevents technical debt from creeping in, enhancing the resilience, efficiency, and innovation of your engineering team. The right tools play a crucial role in this strategy. This is where bringing in vFunction can benefit your team in multiple ways.
How vFunction can help reduce technical debt
Managing and addressing technical debt can be daunting, but it’s essential for maintaining the long-term health and sustainability of your software systems. That’s where vFunction comes in.
vFunction helps customers measure, prioritize, and remediate existing technical debt, especially the sources of architectural technical debt, such as dependencies, dead code, and aging frameworks.
vFunction’s platform is designed to help you tackle technical debt challenges in complex, monolithic applications and in modern, distributed applications. Our AI-powered solution analyzes your codebase and identifies areas of technical debt. This allows teams to communicate technical debt issues effectively and provide actionable insights to guide modernization efforts.
Here are some key ways vFunction can help you:
Assess technical debt: vFunction comprehensively assesses your technical debt, highlighting areas of high risk and complexity.
Prioritize refactoring efforts: vFunction helps you identify the most critical areas to refactor first, ensuring that your modernization efforts have the greatest impact.
Automate refactoring: vFunction automates many of the tedious and error-prone tasks involved in refactoring, saving you time and resources.
Reduce risk: vFunction’s approach minimizes the risk of introducing new bugs or regressions while modernizing legacy systems.
Accelerate modernization: vFunction enables you to modernize your legacy applications faster and more efficiently, unlocking the benefits of cloud-native architectures.
With vFunction, you can proactively manage technical debt, improve software quality, and accelerate innovation.
Conclusion
Technical debt is unavoidable in modern software development, but it doesn’t have to be a barrier to progress. With the right strategies in place, teams can manage technical debt and use it as a stepping stone toward cleaner, more scalable systems. From identifying root causes and implementing reduction techniques to adopting long-term preventative practices, the key lies in maintaining a balance between building for today and preparing for tomorrow.If your team is struggling with growing complexity or slowing velocity due to technical debt, especially at the architectural level, connect with the experts at vFunction. Our AI-powered platform can help you assess your current state, prioritize what matters most, and modernize confidently.
Organizations moving to the cloud must first undertake a cloud readiness assessment, a vital step in ensuring a smooth transition. This evaluation identifies potential migration challenges such as compatibility, security risks, and data complexities while aiming to optimize resources and improve workflows.
Statistics indicate the urgency of such assessments, with 70% of workloads expected to be running in a cloud computing environment by 2028 (Gartner).
This blog will highlight key aspects of cloud readiness assessments, providing a checklist and migration tools. Whether you are considering a cloud migration project or are in the middle of it, proper readiness is essential for harnessing the cloud’s full potential and achieving a successful migration.
What is a cloud readiness assessment?
A cloud readiness assessment is essentially a diagnostic deep-dive into an organization’s IT ecosystem, crucial for planning a successful migration to the cloud. It meticulously evaluates an organization’s cloud adoption suitability, spotlighting potential obstacles, streamlining resources, and carving out a bespoke migration strategy. This process not only illuminates your organization’s preparedness for the cloud but also crafts a clear path forward, smoothing out bumps and optimizing benefits along the way.
This assessment looks into various aspects of your organization, including:
Infrastructure: Assessing your current hardware, network, and data center capabilities to see if they’re ready for cloud migration.
Applications: Evaluating your applications’ compatibility with cloud environments and identifying migration challenges and dependencies.
Security: Analyzing your security posture and identifying vulnerabilities that need to be addressed before moving to the cloud.
Data: Assessing your data storage, management, and migration requirements to ensure data integrity and compliance.
People: Evaluating your team’s skills and knowledge to see if they can manage and support cloud environments.
Processes: Analyzing your existing IT processes and workflows to see what needs to be adapted or optimized for the cloud.
Now that we know the basic ingredients of an assessment, how does it all come together in a cohesive plan?
How does a cloud readiness assessment work?
A cloud readiness assessment is unique to your organization and project. Assessing your organization’s readiness for cloud adoption is not a one-size-fits-all process. The assessment must be tailored to each organization’s specific needs and goals. However, the general approach involves the following steps:
Define objectives and scope
Identify the applications, data, and infrastructure that will be migrated and the desired outcomes of the migration.
Gather data
Next, collect relevant data about your current IT environment, including infrastructure specifications, application dependencies, security policies, and data storage requirements. This data can be gathered through interviews, surveys, documentation reviews, and automated tools. The more data points and angles you can cover here, the better foundation you’ll have for accurately assessing where your organization and team are at.
Analyze and evaluate
Analyze the collected data to evaluate your organization’s cloud readiness across various dimensions. This analysis will examine infrastructure, applications, security, data, people, and processes, giving you an excellent idea about potential challenges, risks, and opportunities. Although it’s almost guaranteed that some unknowns will surface while executing cloud migration initiatives, the goal is to identify anything significant regarding costs or timeline.
Develop recommendations
Based on the analysis, develop recommendations for addressing gaps, optimizing resources, and mitigating risks. Leverage the deep expertise of anyone you are working with, including consultants. Use their practical knowledge and your specific data to formulate recommendations that align closely with your cloud migration goals and are customized to your organization’s unique needs and aspirations.
Create a roadmap
The final step before executing cloud migration is to develop a detailed roadmap. It outlines steps, timelines, and resource planning, drawing from earlier findings and recommendations for a clear adoption strategy. Crucially, stakeholders across departments should be involved for a well-rounded strategy aligning with broad business goals, ensuring the roadmap is comprehensive and tailored.
Four steps of a cloud readiness assessment
To distill the cloud readiness assessment process, it’s practical to categorize activities into four key strategic phases, recognizing that each organization’s path to the cloud is unique. These phases provide a structured approach to the assessment.
Assessment & planning
This foundational phase sets the stage for a successful assessment. Don’t rush this part!
Define objectives: Be clear about your “why” for cloud migration. Are you looking for cost optimization, improved scalability, enhanced agility, or a combination of benefits? Document these objectives with specific, measurable goals.
Scope: Precisely define the applications, data, and infrastructure components that fall within the assessment. A phased approach might be beneficial, starting with a pilot migration of non-critical workloads.
Success criteria: Define measurable metrics to measure the success of your cloud migration. This could be reduced infrastructure costs, improved application performance (e.g., response times), or decreased security incidents.
Taking inventory of your current state
This step requires a thorough investigation of your current IT environment.
Infrastructure: Inventory your hardware, network devices, and data center setup. Assess server utilization, network bandwidth, and storage capacity. Identify old hardware or software that will hinder cloud migration.
Application portfolio: Categorize your applications based on their cloud readiness. Analyze application architecture, dependencies, and licensing models. Prioritize applications for migration based on their criticality and complexity.
Security: Perform a security audit, including vulnerability assessments and penetration testing. Review security policies, access controls, and data encryption practices. Ensure compliance with industry regulations.
Data: Analyze your data storage, management, and migration requirements. Classify data based on sensitivity and regulatory compliance needs. Evaluate data migration tools and strategies.
Creating the vision for your future state
Now that you have a good understanding of your current state, you can envision your ideal cloud environment.
Cloud provider: Evaluate different cloud providers (AWS, Azure, GCP) based on your requirements. Consider service offerings, pricing models, security features, and geographic locations.
Architecture: Design your cloud architecture, including network topology, virtual machine sizing, storage solutions, and security configurations. Explore cloud services that can enhance your applications.
Migration plan: Develop a detailed migration plan outlining the sequence of application and data migrations, timelines, resource allocation, and rollback strategies.
Gap analysis & recommendations
This step bridges the gap between your current reality and your cloud aspirations.
Gaps: Compare your current state assessment with your future state design to identify any discrepancies or shortfalls. These gaps could be in infrastructure, applications, security, data management, or even skills and processes.
Recommendations: Develop specific, actionable recommendations to address the identified gaps. This might be upgrading hardware, refactoring applications, implementing new security controls, or adopting DevOps practices.
Roadmap: Develop a detailed roadmap with prioritized action items, timelines, resource allocation, and risk mitigation strategies. This will guide your cloud migration journey.
Benefits of a cloud readiness assessment
Conducting a cloud readiness assessment is crucial for a seamless cloud migration. This proactive step ensures informed decision-making, resource optimization, and risk reduction. Rather than a hasty cloud shift, this strategic approach yields multiple advantages.:
Reducing risks and avoiding costly mistakes
A cloud readiness assessment helps you identify potential issues upfront, such as application compatibility problems, security vulnerabilities, or data migration complexities. By addressing these issues early on, you can minimize disruption to your business and avoid costly rework or delay. A well-planned migration guided by an assessment ensures a seamless transition with minimal downtime and impact on revenue.
Optimizing resources and improving efficiency
Accurately understanding your resource requirements is critical to cost optimization in the cloud. A cloud readiness assessment helps you right-size your resources, avoiding over-provisioning or under-provisioning. It also gives you insight into cloud-native services and automation capabilities that may be available to improve efficiency and reduce operational overhead once you’ve migrated over.
Enhancing agility and flexibility
Cloud computing offers unparalleled agility and flexibility to adapt to key business drivers. A cloud readiness assessment helps you leverage these benefits by speeding up application deployment and services. It also enables you to scale up or down for greater flexibility and responsiveness.
Improving security and compliance
Security is top of mind in any IT environment and the cloud is no exception. A cloud readiness assessment helps you strengthen your security by identifying and addressing vulnerabilities before migrating to the cloud. It also ensures compliance with industry regulations and data privacy requirements by ensuring that proper security controls are in place once you’ve migrated.
Cloud readiness assessment checklist
A cloud readiness assessment is tailored to each business, but common elements exist. Use the checklist below as a framework to guide your assessment, covering all critical areas. This will help you thoroughly understand the current state of your infrastructure and applications. Focus on these key areas:
Area
Checklist item
Description
Infrastructure
Inventory
Document all hardware (servers, network devices, storage), software, and data center components.
Capacity
Assess server utilization, network bandwidth, and storage capacity.
Age and condition
Evaluate the age and condition of your hardware and software. Identify any outdated or end-of-life systems.
Compatibility
Determine the compatibility of your infrastructure with your chosen cloud environment (e.g., virtualization support, network configuration).
Virtualization
Assess your current virtualization strategy and its compatibility with the cloud.
Applications
Inventory
Catalog all applications, their versions, and their dependencies.
Architecture
Analyze application architecture and its suitability for cloud deployment (e.g., monolithic vs. microservices).
Licensing
Review software licenses to ensure they permit cloud deployment and understand any licensing changes in the cloud.
Dependencies
Identify and document application dependencies (libraries, databases, etc.) and potential conflicts.
Cloud services
Explore cloud services (e.g., serverless functions, managed databases) that can enhance your applications.
Security
Policies and procedures
Review existing security policies, procedures, and standards. Update them to align with cloud security best practices.
Vulnerability assessment
Conduct vulnerability assessments and penetration testing to identify security weaknesses.
Access control
Evaluate access control mechanisms and user authentication methods. Implement strong identity and access management (IAM) in the cloud.
Data encryption
Assess data encryption practices and key management processes. Ensure data is encrypted at rest and in transit.
Compliance
Ensure compliance with relevant industry regulations (e.g., GDPR, HIPAA) and data privacy laws.
Data
Inventory
Catalog all data assets, their formats, and their storage locations.
Classification
Classify data based on sensitivity, criticality, and regulatory compliance requirements.
Storage
Evaluate data storage requirements and potential cloud storage solutions (e.g., object storage, block storage).
Migration
Assess data migration tools, strategies (e.g., online vs. offline), and potential challenges.
Governance
Establish data governance policies and procedures for the cloud environment.
People
Skills gap analysis
Identify skills gaps within your IT team related to cloud technologies and cloud management.
Training and development
Develop training and development plans to address skills gaps and prepare your team for cloud operations.
Roles and responsibilities
Define roles and responsibilities for managing and supporting cloud environments.
Organizational structure
Assess the need for organizational structure changes to support cloud adoption and operations.
Processes
IT service management
Evaluate existing IT service management (ITSM) processes and adapt them for the cloud.
DevOps
Assess your DevOps maturity and identify areas for improvement to streamline development and deployment in the cloud.
Automation
Explore automation opportunities to streamline IT operations, provisioning, and management in the cloud.
Monitoring and management
Evaluate cloud monitoring and management tools and strategies to ensure visibility and control over your cloud environment.
This checklist delivers a thorough framework for evaluating your organization’s cloud readiness, laying the foundation for a strategic migration roadmap. Remember, this process doesn’t have to be entirely manual—there are numerous tools and consultants available to facilitate various aspects of the assessment, making it more comprehensive and efficient.
Best cloud readiness assessment tools
Choosing the right tools can significantly simplify your cloud readiness assessment and provide valuable insights into your IT environment without the manual work. While many tools are available, here are the top three that can help out teams that are looking to gauge their cloud readiness.
vFunction
vFunction, with its AI-driven architectural observability capabilities, streamlines application modernization and cloud migration. Though not exclusively a cloud readiness tool, its features significantly aid the assessment process by providing a detailed analysis of application portfolios, software dependencies, complexities, and migration risks, enabling a robust evaluation of cloud readiness. It helps you:
Assess application complexity: Understand the complexity of your applications and the challenges of cloud migration.
Visualize dependencies: Generate interactive visualizations to understand the relationships between application components.
Decompose monolithic applications: Break down monolithic applications into smaller, more manageable microservices for easier cloud deployment.
Prioritize cloud readiness tasks after analyzing your applications
vFunction’s focus on application modernization makes it an excellent tool for organizations that want to understand and refactor their applications as part of their cloud migration strategy. It enhances the assessment and modernization process with its ability to automatically visualize applications and produce and prioritize detailed task lists related to cloud readiness, as well as optimizing for other business goals, such as resiliency, scalability, and engineering velocity. The platform allows you to configure automated alerts tailored to these objectives. Users can streamline their workflow by sorting and filtering tasks across various dimensions, including domain, status, and priority. Additionally, vFunction facilitates seamless integration with project management tools by enabling the export of these tasks to platforms like Jira and Azure DevOps for efficient tracking and execution. When you’re ready to move to the cloud, close partnerships with AWS and Microsoft Azure help streamline cloud migration and deliver cost-effective offerings.
vFunction enhances the assessment and modernization process by automatically visualizing applications and producing and prioritizing detailed task lists related to cloud readiness,
CloudCheckr
CloudCheckr is a cloud management platform that offers a suite of tools for cost optimization, security, and compliance. For those who are looking to move to AWS in particular, its cloud readiness advisor, focused on AWS’s Well-Architected Pillars, can help you:
Assess cloud readiness: Evaluate your environment against industry best practices and security standards.
Find cost savings: Discover ways to optimize cloud spend and reduce waste.
Improve security posture: Identify and remediate security vulnerabilities and compliance violations.
Automate governance: Automate governance policies to ensure consistent security and compliance across your cloud environment.
CloudCheckr’s focus on cost optimization and security makes it a great tool for organizations that want to maximize their cloud investments.
Cloudamize
Cloudamize is a cloud migration planning and automation platform that utilizes an industry-leading analytics algorithm to produce the right-sized recommendations for cloud infrastructure. The insights provided by this platform can help you:
Discover and analyze: Automatically discover and analyze your IT environment to understand your cloud migration needs.
Plan and design: Design your target cloud architecture and plan your migration strategy.
Estimate costs: Calculate the cost of running your applications in the cloud.
Automate migration: Automate the migration of your applications and data to the cloud.
Cloudamize’s focus on migration planning and automation makes it a good fit for organizations that want to speed up cloud adoption.
Conclusion
Moving to the cloud offers many benefits but requires careful planning and execution. A cloud readiness assessment is the first step in creating your cloud strategy, providing valuable insights into your organization’s cloud readiness. By identifying the challenges, optimizing resources, and developing a comprehensive strategy, you can minimize the risks and maximize the benefits of cloud adoption.
Ready to unlock the power of the cloud and modernize your applications?Try vFunction for free and unlock AI-driven insights for efficient application modernization. Simplify architecture, mitigate risks, and strategize for cloud migration. Contact us to consult with our cloud readiness experts to accelerate your cloud transition.
I’ll be the first to admit—I am not a light packer. Ask anyone who’s traveled with me, and they’ll tell you I have zero chance of squeezing everything into a carry-on. Checked luggage? Always. Overweight fees? Probably. But at least I’m not dragging around a 20-year-old monolithic application on my way to the cloud.
Unfortunately, that’s exactly what a lot of enterprises are still doing. They know they need to modernize, but they keep clinging to their outdated architectures like I cling to the idea that I might need that extra pair of shoes on a three-day trip.
The difference? AWS and independent software vendors (ISVs) like vFunction are working together to lighten the load.
The harsh truth: Some applications won’t yield the expected cloud benefits from lifting and shifting
The architectures of some applications are so outdated or riddled with dependencies that moving them as-is to AWS won’t yield any benefits and in fact may increase cost. That’s where modernization is a necessity.
That’s why AWS has programs like ISV Workload Migration to help enterprises reduce the financial barriers to assess, analyze, and modernize their applications’ architecture so they can migrate successfully to the cloud and achieve scalability, speed, and cost savings. This program is a global initiative by AWS that provides enterprises with funded access to advanced ISV modernization and migration technologies. Recently, vFunction announced its inclusion in this exclusive offering of assessment, migration, and cloud operations tools.
Through these programs and with partners like vFunction, enterprises can:
Analyze application architectures pre-migration to determine what’s cloud-suitable
Make targeted architectural changes to enable migration to AWS
Ensure applications don’t just move to the cloud, but run efficiently on AWS
Because let’s face it: Lift-and-shift is not a modernization strategy. Sure, it gets your apps to the cloud, but many enterprises quickly realize that just shifting the problem to a new environment doesn’t magically solve it.
Post lift-and-shift? vFunction helps you go cloud-native
For those that have already lifted and shifted and are asking, “Now what?” vFunction—a pioneer in architectural observability—helps organizations take the next step: Modernizing, migrating, and governing applications in the cloud to achieve a true cloud-native architecture.
vFunction helps companies:
Refactor applications to use modern AWS services like Lambda, Fargate, and EKS
Break apart monoliths to improve scalability and agility
Ensure apps can actually take advantage of AWS’s elasticity, cost optimization, and performance
So whether your applications can’t move to the cloud yet—or they did move but still feel like they’re stuck in the past—vFunction + AWS programs provide a clear path forward.
Building an app mod factory: Small, smart, iterative changes
Modernization doesn’t have to be a big-bang, all-or-nothing approach. In fact, it shouldn’t be. Big-bang modernization projects are slow, risky, and expensive. Instead, we help enterprises build an application modernization factory—an iterative, low-risk approach where we make quick, targeted architectural changes to make apps cloud-ready and cloud-efficient over time.
Here’s how:
Step 1: Architectural observability – Understand what’s actually happening inside your applications (before you break something). Step 2: Guided refactoring – Use AI-driven automation to detect and fix architectural flaws that block migration or cloud-native adoption. Step 3: Cloud-suitable transformation – Make the necessary changes to deploy efficiently on AWS, whether it’s moving to containers, serverless, or other modern architectures. Step 4: Rinse and repeat – Iterate and modernize more apps without the pain of massive, multi-year, waterfall projects.
vFunction helps you quickly understand your existing application and uses AI to identify and organize cloud readiness tasks.
This isn’t about some drawn-out, high-risk transformation. It’s about making practical, impactful changes—quickly and continuously—to ensure applications can run effectively in AWS.
What this means for enterprises
It means no more excuses. AWS has invested in the tools, partners, and frameworks to make modernization and migration achievable. ISVs like vFunction are automating the hardest parts, to transform applications magnitudes faster. Enterprises now have a clear path to cloud success without endless delays, high risks, or wasted spend.
With AWS ISV funded tools, AWS is ensuring every customer moves to the cloud the right way, without dragging their tech debt along for the ride.
So if you’re an enterprise still clutching your legacy apps like I clutch my overpacked suitcase, now’s the time to take advantage of the expertise, tools, and programs available to finally modernize.
And if you’re an AWS rep or SI partner trying to get your customers unstuck—let’s chat. We’re ready to make cloud adoption as painless as possible.
Businesses facing rapid innovation must continually modernize applications to stay competitive. Legacy systems, restricted by outdated technologies, can impede agility and efficiency. Like renovating an old house to meet modern standards while retaining its charm, application modernization updates the technology and architecture of apps without losing essential functionality. This can range from cloud migration to transforming monoliths into microservices.
In this blog, we explore application modernization through seven case studies from various industries, demonstrating how companies have addressed legacy issues, integrated modern technologies, and realized cost savings and enhanced efficiency. Let’s delve deeper into what application modernization involves.
What is application modernization?
Application modernization is the process of updating and transforming legacy software applications to meet current business needs by leveraging the latest technologies. To keep with our house renovation metaphor, it’s not just about slapping on a fresh coat of paint; it involves a fundamental shift in how applications are designed, developed, and deployed. Previously focused on cost savings or aging platforms, modernization has evolved into a proactive strategy. Companies now upgrade their applications to integrate cutting-edge AI technologies, adapting to trends like generative AI and advanced intelligent agents for enhanced performance and competitiveness. No matter what the reason for modernization, here’s a breakdown of what it can involve:
Technology updates: Migrating applications to newer platforms, programming languages, and frameworks. This could mean moving from on-premises infrastructure to the cloud, adopting the latest architecture, or incorporating modern technologies like containers and serverless computing.
Software decomposition: Systematically dismantling complex legacy systems into simpler, independent components, thereby reducing technical debt and eliminating outdated dependencies to facilitate easier maintenance and future scalability.
Code refactoring: Restructuring and optimizing existing code to improve performance, maintainability, and security. This might involve breaking down monolithic applications into smaller independent modules or services.
Cloud migration: Moving applications to cloud environments to leverage scalability, elasticity, and cost efficiency. This could mean re-platforming, re-hosting, or even re-architecting applications to make them work well in the cloud.
UI/UX enhancement: Modernizing the user interface and user experience (UI/UX) to improve usability, accessibility, and overall user satisfaction.
Integration with modern systems: Integrating legacy applications with modern systems and APIs to enable new or expanded functionality, data exchange, and interoperability.
Security enhancements: Implementing modern security measures to protect applications from cyber threats and ensure data privacy.
Modernization projects vary, customizing strategies and techniques to specific applications, business needs, and technology goals, but aim to transform legacy systems into modern, agile, and scalable platforms for growth and innovation.
Why do you need application modernization?
Legacy applications can seriously hinder growth and innovation. In a 2024 survey, RedHat found that companies planned to modernize 51% of their applications within the next year. This means that the urgency to modernize is critical. For widespread adoption, application modernization must be viewed not just as a technical update, but as a strategic necessity to stay competitive and avoid falling behind rivals. Here’s why you need to consider application modernization as a key initiative for any technology-backed business:
Agility and scalability: Modernized applications are built on flexible architectures that can adapt to changing business needs. They can scale up or down quickly to handle fluctuating workloads so businesses can respond dynamically to the demands of the system/application.
Performance and efficiency: Outdated technologies and architectures can cause performance bottlenecks and inefficiencies. Modernization optimizes applications for speed and efficiency, reduces latency, and improves user experience.
Cost savings: Legacy systems generally require expensive maintenance and support. Modernization can reduce these costs by leveraging cloud-native services, automation, and more efficient technologies.
Security: Modernized applications incorporate the latest security measures to protect against cyber threats and ensure data privacy. By using more modern infrastructure, frameworks, and programming languages, applications are more likely to be secure.
Innovation: Modern technologies and architectures enable businesses to innovate faster and deliver new features and services to market quickly. This can give businesses a competitive edge and drive business growth, as it increases the chance of being first to market.
Customer experience: Modernized applications offer better user experience, intuitive interfaces, faster response times, and enhanced functionality. Users expect a modern look and feel and quick and consistent performance, which are major drivers of customer satisfaction and loyalty.
Developer experience: Aside from merely focusing on the external customer experience, modernizing to newer technologies can also help developers working on the application. By modernizing the app, developers usually benefit from the capabilities that new frameworks and technologies bring to their workflows. This can also help attract new talent to the organization since many developers prefer to work with the latest and greatest tech versus legacy codebases.
Future-proofing: By adopting modern technologies and architectures, businesses can future-proof their applications and ensure they remain relevant and competitive in the long term. The longer modernization is delayed, the taller the mountain is to climb to remain relevant and competitive.
In short, application modernization is not just about upgrading your application or service to the latest technology; it’s about transforming your applications to drive new business growth and innovation and keep up with the ever-increasing standard for customer satisfaction.
Seven application modernization case studies
Now, if you’ve been around the software development space for a while, chances are that you have either participated in a transformation or modernization project or know of companies that have undergone such efforts. Below, let’s look at some large organizations that you’ll likely be familiar with, as well as some that are less known. The common thread between them is that they’ve all undergone massive digital transformation and modernization efforts that helped them move their applications to the next level.
Amazon: From monolith to microservices
Amazon, one of the most dominant e-commerce and cloud computing companies today, didn’t always have the scalable architecture it’s known for now. In its early days, Amazon operated as a monolithic application, where all its services—search, checkout, inventory, and recommendations—were tightly coupled in a single codebase. While this approach worked initially, it became a major bottleneck as Amazon’s growth skyrocketed. AWS CTO Werner Vogels famously recalls his “worst day ever” at a reInvent keynote, due to this architecture. Deployments took hours, minor changes in one part of the system risked breaking others, and scaling meant replicating the entire monolith, leading to inefficient resource usage.
AWS CTO, Werner Vogels, recalling his “worst day ever” on the reInvent keynote stage.
Recognizing that the status quo wasn’t sustainable, Amazon underwent a radical transformation of its monolithic ‘bookstore’ application into smaller services. But before that, they had to address these key challenges:
Water-tight planning: Splitting the monolithic architecture into functional microservices required detailed planning to ensure seamless communication and data consistency.
Operational overhead: Managing numerous services introduced complexities in monitoring, debugging, and deploying, necessitating the development of new tools and methodologies.
Security concerns: The distributed nature of microservices increased potential security vulnerabilities, requiring robust protocols to secure service communications and prevent unauthorized access.
To address these challenges, they:
Decomposed their monolith into thousands of independent microservices, enabling teams to develop and deploy changes in isolation.
Gave each microservice its own dedicated database, moving away from a centralized relational database to a distributed, purpose-built approach.
Implemented API gateways and service discovery, orchestrating communication between microservices without overwhelming network traffic.
Shifted to an eventual consistency model, allowing services to function independently even if other parts of the system experienced delays.
Adopted a DevOps culture, enabling continuous deployment and infrastructure automation, keeping security top of mind.
The transition to microservices transformed Amazon’s ability to innovate rapidly. Teams could deploy new features hundreds of times per day without risking downtime. Scaling became granular and efficient, allowing Amazon to support peak traffic during events like Prime Day without over-provisioning infrastructure. This modernization was pivotal in Amazon’s ability to maintain its position as a global e-commerce leader.
Netflix: Migration to the cloud
In 2008, Netflix suffered a catastrophic database corruption in its primary data center that brought DVD shipments to a halt for three days. This incident exposed a glaring problem—Netflix’s on-premises infrastructure wasn’t resilient enough for its rapid growth. At the same time, the company was shifting its business model toward streaming video, a move that would demand exponentially greater computational and storage capacity.
Scalability: Rapid user growth required Netflix to build an infrastructure capable of handling large and unpredictable workloads.
Reliability: Ensuring consistent service uptime was critical, amidst the complexities inherent in a distributed cloud-based system.
Cloud-native re-architecture: Migrating to AWS necessitated a comprehensive rebuild of their systems to fully exploit cloud capabilities.
Their modernization efforts included:
Migrating all core services to AWS, eliminating capacity constraints, and enabling dynamic scaling.
Rewriting their monolithic application into hundreds of microservices, allowing different teams to own and iterate on services independently.
Leveraging chaos engineering, proactively injecting failures in production to ensure system resilience.
Building multi-region redundancy so that traffic could be rerouted seamlessly if one AWS region experienced an outage.
Implementing real-time analytics and AI-driven content delivery, ensuring smooth playback quality based on user bandwidth.
This transformation allowed Netflix to scale from a few million DVD subscribers to over 300 million streaming users worldwide. Their cloud-native approach enabled 99.99% uptime, seamless feature rollouts, and high-definition streaming at scale. In many ways, Netflix didn’t just modernize their platform—they set new standards for cloud-based streaming services.
Walmart: Omnichannel retail transformation
As one of the largest brick-and-mortar retailers in the world, Walmart had long dominated physical retail. However, the rise of e-commerce and mobile shopping forced Walmart to rethink its approach to technology. Walmart’s legacy e-commerce platform was a monolithic system that struggled with high traffic spikes, particularly during Black Friday sales.
Determined to modernize its tech stack and improve scalability, Walmart undertook a monolith-to-cloud microservices journey. Their transformation journey started by solving these key challenges:
Integration complexity: Integrating new microservices with existing legacy systems without disrupting the ongoing operations posed a significant challenge, given the scale at which Walmart operates.
Data consistency: Ensuring data consistency across distributed systems was crucial, especially in retail where real-time inventory management and customer data are pivotal.
Cultural and organizational shifts: Moving to a microservices architecture required a shift in organizational culture and processes, adapting to more agile and DevOps-centric practices, which was a massive undertaking for a corporation of Walmart’s size.
Some of the critical efforts in the transformation processes included:
Adopting a microservices-based approach, breaking down its tightly coupled e-commerce platform.
Rebuilding critical services in Node.js, reducing response times, and improving efficiency.
Migrating infrastructure to the cloud, ensuring elasticity during traffic surges.
Implementing real-time analytics, allowing dynamic inventory updates and personalized recommendations.
Designing a mobile-first shopping experience, ensuring seamless integration across online and in-store purchases.
The impact was immediate. Walmart could handle 500 million page views on Black Friday without performance degradation. Their modernization efforts turned them into a major e-commerce player, competing more effectively with Amazon while delivering a seamless omnichannel experience.
Adobe: Transition to cloud-based services
Adobe operated under a traditional software licensing model for years, selling boxed versions of Photoshop, Illustrator, and other creative tools. However, the rise of cloud computing and subscription-based software services put pressure on Adobe to modernize its business model.
Architectural dependencies: Adobe had to break down their monolithic application into micro-frontends, facing challenges related to component exposure, dependency sharing, and handling dynamic runtime sharing complexities.
Integration complexity: They had to solve routing, state management, and component communication efficiently across independently developed and deployed micro-frontends.
Performance concerns: The micro-frontend architecture involved loading resources from various sources that could potentially increase page load times and impact the overall user experience.
Their modernization strategy involved:
Developing Adobe Ethos, a cloud-native platform that standardized deployment pipelines.
Containerizing applications, allowing Creative Cloud services to scale independently.
Implementing continuous delivery, enabling real-time software updates rather than large, infrequent releases.
Building a self-service internal platform as a service (PaaS), improving efficiency across global development teams.
This transition reinvented Adobe as a cloud-first company, leading to predictable recurring revenue, improved customer retention, and rapid innovation.
Khan Academy: Scaling and maintaining a growing platform
Khan Academy, the non-profit educational platform, began as a monolithic Python 2 application. As the platform grew to millions of students, this aging architecture became a major roadblock.
With increasing technical debt, Khan Academy launched “Project Goliath,” a full-scale re-architecture effort. Their modernization included a successful monolith-to-services rewrite. However, they were strategic in their modernization efforts by staying away from manual efforts keeping in mind the following:
Scalability and efficiency: Automated modernization techniques allowed Khan Academy to efficiently manage their extensive codebase and services, which would be impractical and highly time-consuming with manual efforts. Their goal was to improve scalability and the ability to handle the growing demands on their platform, something manual processes would not have supported effectively.
Risk management: Through automation, Khan Academy was able to better manage risks associated with the transformation process. Manual modernization techniques would have posed higher risks of errors and inconsistencies, which can be detrimental in a learning environment that millions rely on. The automated approach provided a more controlled and error-proof environment, particularly important for the educational integrity and reliability of the platform.
Timeliness: The project to migrate from a monolithic to services-oriented architecture was ambitiously timed. Khan Academy aimed to complete significant portions of this project within a constrained timeframe. Manual modernization efforts, due to their slow and labor-intensive nature, would not have met these strategic timelines, potentially delaying crucial updates and improvements essential for user experience and platform growth
Their improvements included:
Rewriting core services in Go, dramatically improving performance.
Using GraphQL APIs, making data fetching more efficient.
Gradually migrating services using the Strangler Fig pattern, minimizing downtime.
Adopting cloud-based infrastructure, improving reliability and scalability.
By modernizing its platform, Khan Academy reduced infrastructure costs, improved page load times, and ensured that it could continue to support millions of students worldwide, even during traffic spikes.
Turo: Accelerating modernization with vFunction
Let’s explore two case studies where vFunction was pivotal in driving change. First up is Turo, the popular peer-to-peer car-sharing marketplace, which faced the challenges of a monolithic architecture. As Turo’s platform developed, the monolith became a bottleneck, limiting scalability and slowing development, ultimately hindering their ability to meet market demands. To tackle these challenges, the CTO challenged his team to build for 10X scale. Turo turned to vFunction for deeper insights into their application’s complexity. With vFunction’s help, Turo initiated a strategic modernization journey, transitioning from a monolith to microservices. Here’s an overview of the implementation and the key benefits they gained:
Utilized vFunction to visualize complex dependencies within their monolithic application.
Accelerated the refactoring process, specifically breaking apart the monolith into newly minted microservices.
Improved developer velocity, enabling faster delivery of new features.
With vFunction, Turo used architectural observability to move toward a more scalable and agile architecture. This is one example of how the right tool can expedite the application modernization journey and help make it successful.
Turo realized huge efficiencies as it began to implement microservices and plan for 10X scale.
Trend Micro: Enhancing security and agility
In another vFunction case study, Trend Micro, a global cybersecurity leader, recognized the need to modernize its legacy applications to enhance security and agility to help protect against increasing cyber threats. To remain at the forefront of cybersecurity, they needed to adopt modern architectures that would enable faster innovation and stronger security postures. But Trend Micro faced several challenges:
Monolithic architecture challenges: Trend Micro’s Workload Security product suite comprised 2 million lines of code and 10,000 highly-interdependent Java classes, which made it difficult to achieve developer productivity, increased deployment velocity and speed, as well as other cloud benefits. Their legacy systems were deeply intertwined, which complicated any efforts towards modernization.
Negative impact on engineer morale: The engineering teams working on the Workload Security monolith were using outdated technologies and practices. This caused frustration, as the large and indivisible nature of the shared codebase hindered the engineers’ ability to make impactful changes or address system issues efficiently. The lackluster division of the codebase and lack of clear domain separation among teams reduced the ability to handle system errors or failures quickly.
Inadequate “lift and shift” for value delivery: While initial attempts to re-host parts of the workload security to AWS improved compute efficiency, deeper refactoring was required for proper scaling and full utilization of the cloud’s features. Without this, services had to be over-provisioned and kept always-on, which was not optimal.
Scaling and feature delivery: Due to the monolithic structure, there was a lack of ability to scale, slowing the speed of deployment and decreasing product agility. This limitation led to difficulties in implementing new features and fulfilling feature requests, negatively affecting customer satisfaction and the potential for contract renewals.
To mitigate these challenges , they used vFunction to modernize their applications. During this modernization effort, they:
Decomposed monolithic applications into manageable microservices using vFunction.
Improved time-to-market for new security features.
Strengthened their overall security posture.
By modernizing with vFunction, Trend Micro ensured they could continue to provide cutting-edge security solutions to their customers, protecting them from emerging threats.
How can vFunction help with application modernization?
Understanding your existing application’s current state is critical in determining whether it needs modernization and the best path to do so. This is where vFunction becomes a powerful tool to simplify and inform software developers and architects about their existing architecture and the possibilities for improving it.
Results fromvFunction research on why app modernization projects succeed and fail.
1. Automated analysis and architectural observability: It initiates an in-depth automated exploration of the application’s code, structure, and dependencies, saving significant manual effort. This establishes a clear baseline of the application’s architecture. As changes occur – whether they’re additions or adjustments – vFunction provides architectural observability with real-time insights, allowing for an ongoing evaluation of architectural evolution.
2. Identifying microservice boundaries: For those looking to transition from monolithic to microservices architecture, vFunction excels in identifying logical separation points based on existing functionalities and dependencies, guiding the optimal division into microservices.
3. Extraction and modularization: vFunction facilitates the conversion of identified components into standalone microservices, ensuring each maintains its specific data and business logic. This leads to a modular architecture, simplifying the overall structure and by leveraging Code Copy it fosters an accelerated path towards the targeted architectural goals.
Through automated, AI-driven static and dynamic code analysis, vFunction understands an application’s architecture and its dependencies so teams can begin the application modernization process.
Key advantages of using vFunction
Accelerated modernization: vFunction accelerates the pace of architectural enhancements and streamlines the path from monolithic structures to microservices architecture. This boost in engineering velocity leads to quicker launches for your products and modernizes your applications more rapidly.
Enhanced scalability: Architects gain clarity on architectural dynamics with vFunction, making it simpler to scale applications. It provides a detailed view of the application’s structure, promoting components’ modularity and efficiency, which facilitates better scalability.
Robust application resiliency: With vFunction’s thorough analysis and strategic recommendations, the resilience of your application’s architecture is reinforced. Understanding the interaction between different components allows for informed decisions to boost stability and uptime.
Summary
It will not be an exaggeration to say that modernization is not just desirable; it’s essential for thriving in today’s fast-paced technological landscape. Legacy systems that fail to adopt new advancements, including AI, compromise a business’s agility, scalability, and efficiency.
The case studies above show the power of modernization across different industries. Although each company is different, the benefits delivered are seen across the board: modernization delivers cost savings, scalability, and competitiveness. But if done without tools like vFunction to accelerate the process it can be a long, painful, resource-sucking endeavor.
vFunction is a vital tool for modernization projects and ongoing, continuous modernization, as evident in the last two case studies discussed earlier in this blog. Its AI-powered capabilities give you the power and automation to analyze, decompose, and refactor applications to modernize more efficiently. vFunction helps users to speed up the modernization journey and reduce risks along the way.With vFunction, businesses can transform their legacy applications into agile, scalable systems that are ready to meet both current and future demands. Curious about how vFunction can help you modernize your apps? Dive into our approach to application modernization or reach out to chat with our team of experts today.
Software developers and architects play crucial roles in the software development lifecycle, each bringing unique skills to the table. While their responsibilities may overlap, understanding the key differences (and similarities) between them is essential. This article explores these roles in detail, helping you identify their distinct functions within an organization and in software design and development. Perfect for those choosing a career path, defining roles in a team, or simply seeking to understand these pivotal positions – this article has all that you need to understand these roles well. Let’s dive into what sets them apart and where they converge.
What is a software architect?
Complex software requires design much like buildings or houses require it before construction. During the evolution of the software, any significant modifications to the functionality, technology stack, component structure, or integration of existing software require careful consideration before implementation, just like significant changes to a building may require submitting plans and getting permits. Who looks after these critical functions? Generally, this is the domain of a software architect, sometimes also referred to as an application architect. A software architect is a high-level senior software professional who oversees the overall design of a software system. They are responsible for making strategic decisions that impact the system’s long-term viability, scalability, and performance.
Key responsibilities of a software architect include:
Design the system architecture: Create the blueprint for the software system, defining its components, and outlining how they interact.
Technology selection: Choose the right programming languages, development tools, cloud and on-prem services, libraries and frameworks for optimal development and operation of the application.
Address non-functional requirements (NFRs): Unlike functional requirements, which focus on what the system does, architects look at how the system performs, scales, secures, and operates under different conditions.
Collaborate with many stakeholders: Work closely with clients, product owners, and development teams to understand requirements and translate them into technical solutions.
Ensure system quality: Set standards for code quality, performance, and security.
Make technology decisions: Select appropriate technologies and frameworks to meet project goals.
Mentor team members: Provide guidance and expertise to junior developers.
To excel as a software architect, you need a solid grasp of software design principles, patterns, and best practices. It’s not just about years in the field but the depth of your knowledge. Even developers or those in non-architect roles who’ve rapidly advanced their skills could be well-suited for this position. Key to thriving in this role are exceptional problem-solving skills, an acute awareness of the broader impacts of design decisions, effective communication, and a comprehensive understanding of various programming languages and technologies.
It’s also important to note that “software architect” is a broad term, encompassing a range of specialized roles depending on the organizational structure. Here’s a breakdown of some common titles that often fall under the umbrella of “software architect.”
Type of Architect
Role
Software architect
Designs the overall structure of software systems, focusing on technical aspects like programming languages, frameworks, and data structures.
Application architect
Designs the architecture of specific applications, considering factors like scalability, performance, and security.
Enterprise architect
Designs the overall architecture of an organization’s IT systems, aligning technology with business goals.
Principal architect
A senior-level architect who provides technical leadership and guidance to development teams.
Portfolio architect
Focuses on the alignment of IT investments with business strategy, ensuring that tec
In many organizations, the exact roles and responsibilities of architects can differ, and the titles they use may vary. However, understanding the different types of architects can help to understand the roles they play in an organization and the skills and expertise required to take on such a role. In the scope of this blog, we will focus on the software or application architect role.
What is a software engineer?
So, if the architect designs the software, who builds it? While some architects can be hands-on and may assist with coding, generally, a team of software engineers or developers is responsible for implementing the software itself. At a high level, a software engineer is a technical expert who implements the software designed by the architect. They are responsible for writing, testing, and debugging code to bring software applications to life.
Key responsibilities of a software engineer include:
Write code: Develop software applications using various programming languages and frameworks.
Define functional requirements (FRs): Define the software’s specific features, behaviors, and capabilities, including the system’s expected inputs, outputs, and processes at a detailed level, shaping core functionality vs. NFRs (see above). For example, a software architect may specify that the system must handle up to 1,000 concurrent orders and design the supporting infrastructure, while the engineer defines the tests and implements the solution to meet this requirement.
Test code: Ensure the quality and functionality of the software through rigorous testing.
Debug code: Identify and fix errors in the code.
Collaborate with team members: Work with other developers, designers, and project managers to deliver projects on time.
Stay updated with technology trends: Continuously learn and adapt to new technologies and methodologies.
It is essential to note that the terms “software engineer” and “developer” are often used interchangeably in the tech industry, but there can be distinctions in their roles, mindset, and how they approach software development. A software engineer typically applies engineering principles to the entire software development life cycle. This means they are involved in not just writing code, but in the planning, design, development, testing, deployment, and maintenance of software systems. A developer is primarily focused on writing code to create software applications. While they do engage in planning and design, especially at the component level, their focus tends to be more on translating requirements into functional software. Think of software engineering as the broader discipline that encompasses the end-to-end process of creating software systems, while development focuses on the day-to-day activities of writing and testing code.
To excel as a software engineer, strong programming capabilities, robust problem-solving skills, and meticulous attention to detail are essential. Familiarity with software development methodologies, including Agile and Scrum, is beneficial, as these frameworks are commonly employed by teams to collaboratively plan and execute software projects.
The path of a software engineer typically progresses from junior to intermediate, and ultimately to senior levels. At the senior tier, some organizations offer advanced titles such as Principal, Staff, or Distinguished Software Engineer. The distinction among these levels primarily lies in the engineer’s accumulated experience and expertise. However, it’s worth noting that in certain organizations, the emphasis is placed more on the engineer’s skill set rather than the duration of their tenure, when determining their level within the company.
Software architect vs. software engineer: Key differences
While both software architects and software engineers are essential to software development, their responsibilities and focus areas differ. Building on our role overview, here’s a detailed comparison. While responsibilities vary by organization, they can generally be grouped into these categories:
Feature
Software Architect
Software Engineer
Primary role
Designs the overall software systems
Implements software designs and writes code
Focus
High-level design principles, system architecture, NFRs, and strategic planning
Low-level implementation details, coding standards, FRs, and debugging
Scope
The entire software system, including its components, interactions, dependencies
Specific modules or features within the system
Time horizon
Long-term, strategic thinking, often involved in the initial stages of a project
Short-term, tactical execution, focused on delivering specific tasks and features
Communication
Frequent interaction with stakeholders, including clients, product owners, and project managers
Primarily with team members, including other developers, testers, and designers
Technical depth
Broad knowledge of various technologies, frameworks, and industry trends
Deep expertise in specific programming languages, tools, and methodologies
Problem solving
Focuses on solving complex, high-level design problems
Focuses on solving specific coding and implementation challenges
The blurred line: When software architect and software engineer roles overlap
Working in a position that seems to morph the two roles together? You’re not alone. Many architects and engineers find themselves in this situation. In many organizations senior engineers act as pseudo-architects, making key design and planning decisions.
Renowned architect, speaker and author of “The Software Architect Elevator”, Gregor Hohpe, captured this reality at a conference, “My view on this is really, it’s not anything on your business card. I’ve met great architects whose title is an architect. I met people who have the word on the business card where I would say, in my view, they’re not such great architects. It happens. It’s really a way of thinking, a lifestyle almost.”
In organizations that don’t have an official architect role, someone still needs to do the work of an architect, and that person is usually a senior developer or tech lead on the team. This is pretty common, especially with smaller startups or tech businesses with smaller development teams. However, larger, more established organizations that deal with large, complex software systems and strict compliance requirements, such as financial services and banking, healthcare and life sciences, and automation and manufacturing, tend to have a more formal architect/engineer separation of roles.
Understanding the differences and overlap between these two roles clarifies their functions and responsibilities within the SDLC. This insight helps in deciding which role and skillset are necessary for completing tasks or enhancing capabilities within your organization.
When to choose a software architect?
Have a large or complex project you’re taking on and need to have in-depth analysis and design done? Looking to do an on-prem to cloud migration? A large digital transformation initiative? These jobs are good opportunities to leverage the skills of a software architect.
A software architect is typically a great fit when a project requires:
Complex system design: When the system involves multiple interconnected components and intricate workflows, a software architect can design a robust and scalable architecture.
Long-term planning: For projects with a long lifespan, a software architect can ensure the system can evolve and adapt to future needs.
Performance optimization: When performance is critical, a software architect can identify bottlenecks and optimize the system’s design.
Technical leadership: To guide the development team and make strategic decisions about technology choices and best practices as well as translate architectural decisions into business value, bridging gaps between stakeholders.
Risk mitigation: By anticipating potential challenges and designing for resilience, a software architect can help minimize risks.
In essence, a software architect is essential when a project requires a solid foundation, strategic thinking, and technical leadership. It’s not to say that an experienced software engineer couldn’t take on these tasks, but software architects specialize in the nuances of strategic planning and looking to the future and how current decisions will affect the future state of the software.
When to choose a software engineer?
If you’re implementing software, you’ll need a software engineer on your team. The engineer is the critical piece that takes the designs and planning of the architect and turns it into a tangible and working piece of software. Although an architect can likely code, many software engineers specialize in the languages and technologies that have been selected to build the project. A software project can likely still come to fruition without an architect since developers may possess the essentials to push through designing a system (even if less efficient than an architect may do it); however, without software engineers, it would be almost impossible to see the systems come to life.
A software engineer is critical when a project requires:
Implementing code: To translate designs into functional code.
Debugging and testing code: To identify and fix issues in the code and ensure its quality.
Maintenance and support: To maintain existing systems and provide ongoing support.
Rapid development: To quickly deliver features and functionality.
Specific technical skills: For tasks that require expertise in particular programming languages, frameworks, or tools.
In essence, a software engineer is essential for the hands-on implementation and maintenance of software systems. Without the work of the engineer, most software projects would simply dissipate after the design stage.
The software development industry is currently at risk of minimizing the need for human developers and software engineers due to advancements in AI. AI coding assistants are streamlining workflows by automating routine tasks, suggesting code enhancements, and identifying potential bugs, which boosts efficiency but also leads to smaller engineering teams. Encouraged by these capabilities, Meta announced a plan to replace mid-level engineers with AI to cut costs and optimize processes.
However, this shift brings risks. AI lacks the human capacity for intuitive problem-solving and creative thinking, crucial for addressing complex, unstructured challenges often encountered in development. Over-reliance on AI may stifle innovation and undermine team dynamics critical for collaborative environments. Security vulnerabilities and ethical concerns may also be overlooked without the nuanced judgment and oversight provided by human engineers. While AI speeds up code generation, it doesn’t inherently ensure that the generated code aligns with the system’s architecture, dependencies, or long-term maintainability — introducing potential integration challenges, performance issues, and technical debt. Hence, while AI can significantly aid development, it cannot wholly replace the unique contributions of human intelligence in software engineering.
Software architect vs. software engineer: Which is better?
Deciding between a software architect and an engineer depends on the task at hand and the individual’s skills. While architects often handle design and strategy, engineers focus on building the software. The “best” role is determined by the specific needs of the project, which may sometimes require skills from both roles.
In a scenario where an organization has both roles available, the ideal scenario often involves a collaborative effort between the two of them. While a software architect provides the strategic vision, a software engineer brings it to life through implementation. As mentioned previously, in many organizations, these roles may overlap, with individuals taking on responsibilities of both.
However, not all organizations have dedicated software architects. In smaller teams or startups, developers may take on architectural responsibilities, making design decisions and planning the system’s structure. Even in larger organizations, there may be situations where a senior developer or team lead assumes the role of a de facto architect.
When it comes to determining which role you actually require for your project, you’ll need to take into account a few different factors, including:
Project complexity: For complex software systems, a dedicated Software Architect can provide valuable guidance and oversight.
Team size and experience: Smaller teams may not require a dedicated architect, while larger teams may benefit from the expertise of a specialized role.
Organizational structure: The organizational culture and processes can influence the need for a dedicated architect.
Budget constraints: Hiring a dedicated software architect may not be feasible for all organizations since the wages tend to be higher than that of a traditional software engineer.
When it comes to determining which role you actually require for your project, you’ll need to take into account a few different factors, including:
Project complexity: For complex software systems, a dedicated Software Architect can provide valuable guidance and oversight.
Team size and experience: Smaller teams may not require a dedicated architect, while larger teams may benefit from the expertise of a specialized role.
Organizational structure: The organizational culture and processes can influence the need for a dedicated architect.
Budget constraints: Hiring a dedicated software architect may not be feasible for all organizations since the wages tend to be higher than that of a traditional software engineer.
Career growth and salary comparison
Typically, a successful software architect has a strong foundation in software engineering and often has several years of experience in software development. A solid understanding of software design principles, system architecture, and problem-solving skills is essential. As a software engineer’s career matures and their skills grow, many software engineers transition into software architect roles. With experience, this becomes easier to do since it gives time to demonstrate leadership qualities, build the skills for strategic thinking, and a deep understanding of the software development process.
Software engineers typically have a strong foundation in computer science or a related field. They possess strong programming skills, problem-solving abilities, and a passion for technology. While many software engineers continue to specialize in specific technologies or domains, others may aspire to leadership roles, including development team/technical team lead or within the architecture domain.
At a high level, here’s how the roles and career paths break down:
Role
Career paths
Software architect
Technical leadership, management, consulting
Software engineer
Technical specialization, team leadership, senior engineerin
Salary comparison
Another very important factor in this decision is the salary that comes with the role. Generally, architects are seen as a more senior role; however, senior developer roles such as those at the staff or principal software engineer level are just as coveted. Below is a high-level breakdown of average wages in the US for both roles. Being near a tech hub like San Francisco, or working for a FAANG company like Amazon typically commands higher salaries compared to less urban areas or smaller companies. Here’s how it all breaks down:
Equity and stock options can also play a large role in overall compensation. At some organizations, salary is only a small component of the potential upside of taking a role. Emerging markets, such as cloud and AI, can also demand extremely high salaries well beyond the average mentioned here. For example, the median total compensation (base salary, equity, and other benefits) for engineers at OpenAI is reported to be around $900,000 annually. The architects working there seem to make less. This discrepancy likely stems from the fact that AI engineers are directly involved in cutting-edge model development and research, which is a highly specialized and in-demand skill set. Architects, on the other hand, typically focus on system design and integration, which, while crucial, may not attract the same compensation premiums in the AI space. This is just one example of why you should take the importance and salary that comes with a role with a grain of salt.
Conclusion
In conclusion, both software architects and software engineers play crucial roles in the software development process. While architects focus on the high-level design and strategic planning of systems, engineers are responsible for the implementation and maintenance of code.
By understanding the key differences between these roles and the specific needs of your project and organization, you can make informed decisions about the composition of your development team. A balanced approach, combining the strategic vision of architects with the technical expertise of engineers, is essential for successful software development.
vFunction empowers architects and engineers by providing deep architectural insights, visualizing complex dependencies, and enabling continuous governance. Architects can proactively identify design flaws and enforce best practices, while engineers gain the clarity needed to build and refactor efficiently. By bridging the gap between high-level strategy and hands-on implementation, vFunction helps teams create resilient and scalable software that evolves with business needs—without the growing pains of unchecked complexity.
Related
What is software architecture? Checkout our guide.