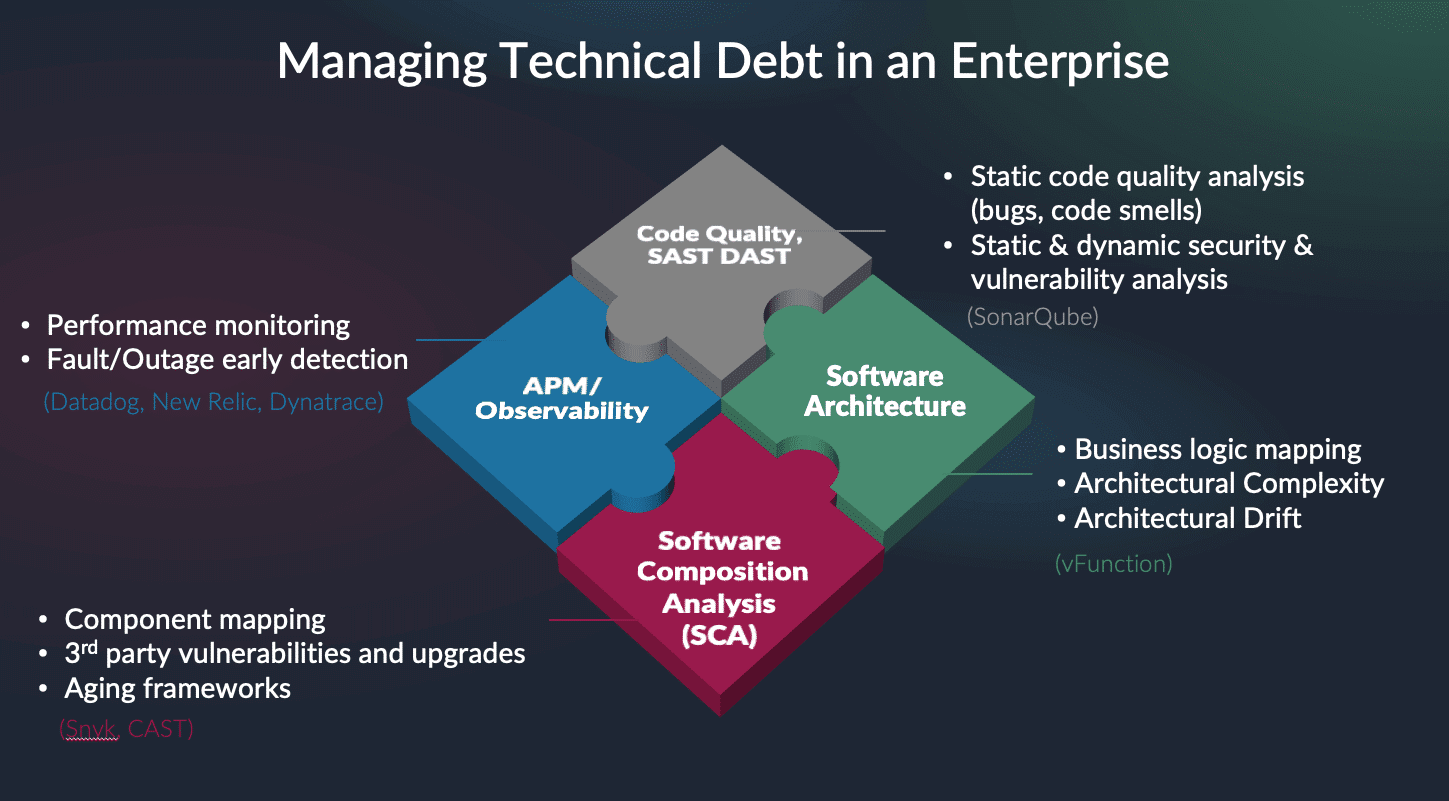
Following best practices for continuous modernization minimizes technical debt. Monitoring tools such as logs and traces highlight accumulating application debt. Once identified, the weaknesses are added to the list of iterative changes in the development pipeline. Little by little, companies pay down their debt.
Unfortunately, not all debt appears as bugs or coding inefficiencies. Sometimes, it represents deviations from the original architecture. This architectural debt happens when infrastructure and design decisions are made as the software evolves.
No one wants to weaken the architecture, but development teams are often faced with adding functionality under time constraints. They may be asked to change features in older frameworks. Each decision moves the software a little further away from its original design. This architectural drift, if left unmanaged, can result in catastrophic failures.
Related: Technical Debt Risk: A Look into SWA, the FAA, and Twitter Outages
By shifting left, continuous application modernization can bring a level of architectural observability to the process. With this added observability, engineers can identify design aspects that no longer serve their purpose. They can recognize redundant classes and intra-service dependencies that other tools may not. Without architectural observability, organizations will struggle to modernize applications at the speed needed to remain competitive.
How Architectural Drift Slows Continuous Modernization
A recent survey found that 87% of decision-makers said application modernization is essential to gain and maintain a competitive edge. That said, they must accelerate the process to remain ahead of their competitors. This push for speed can contribute to architectural drift.
It’s the reality of software development. Few projects have the time and resources to deliver the perfect application. Developers and designers are constantly looking at trade-offs as they try to balance delivery times with best practices, resulting in architectural technical debt.
Declining Productivity
When left to grow unchecked, architectural drift hampers productivity. Developers are unable to incorporate updates quickly. They spend more time trying to make the changes work with a lopsided infrastructure. Before they know it, their application architecture looks like Jack’s house in The Nightmare Before Christmas. The entire structure is just moments away from collapse.
Teams struggle to resolve issues quickly. When the production application differs from the original design, developers take longer to identify and correct problems. Less time is available for writing new code, and their competitive edge shrinks in size.
Increasing Risk
A recent exposé on Twitter outages underscored the risk associated with architectural drift. Long before Elon Musk took control, Twitter had reliability issues. Frequent site failures led to the infamous “fail whale” label that mocked the site’s error screen.
Since 2000, Twitter has consistently added engineers to strengthen the site’s infrastructure. When ownership changed in 2022, layoffs began, threatening the site’s stability. In February 2023, four widespread outages were reported, which is almost half of the nine reported in all of 2022.
Massive layoffs meant a loss of undocumented knowledge. The remaining staff learned the infrastructure through a very public trial and error. Not only does increasing architectural technical debt make it harder to achieve productivity goals, but it also adds to the risk of a catastrophic failure.
Escalating Costs
Architectural drift slows modernization efforts as applications become burdened with growing technical debt. Eventually, the mismatch of architecture and operating environment requires a reassessment of the application, which can result in expensive restructuring.
Testing can take longer as developers struggle to understand the architectural deviations, adding to delivery costs. The process of onboarding engineers slows as they try to unravel architectural intent to become productive. All these factors add to development costs.
Growing technical debt can waste as much as 25% to 45% of a development budget as more resources are needed to maintain and update applications. That doesn’t include the opportunity costs that result from the inability to capitalize on new technologies.
Minimizing the impact of architectural drift requires architectural observability, the ability to analyze an application statically and dynamically to understand its architecture, observe drift, and find and fix architectural technical debt. Software architects need tools to help them see what is happening statically and dynamically. With the right tools, they can baseline the architecture, collect data to detect drift, identify significant events, and correct architectural anomalies before they degrade an application’s business value.
How Architectural Observability Accelerates Continuous Application Modernization
Tradition has architects defining the infrastructure and setting the standards for application development, but they are rarely consulted as the project progresses—opening the door to a design that is loosely tied to the actual application. Today’s continuous modernization approach does little to change that perspective.
Many self-organizing teams see little need for a design engineer. Why worry about maintaining an architectural design that only faintly resembles what operates in the wild? Incorporating architectural concerns only complicates the process with minimal value.
While that assessment may have merit in organizations that lack architectural observability, it no longer reflects the visibility and context that architectural observability tools can provide. With the proper tools, engineers can see how the code operates, define standards, and identify anomalies that allow companies to make informed decisions about how to reduce architectural technical debt.
Architectural observability can accelerate continuous modernization processes by establishing a baseline, deploying AI-empowered tools, and creating internal platforms for increased productivity and business value.
Identify Architectural Drift Faster with a Baseline
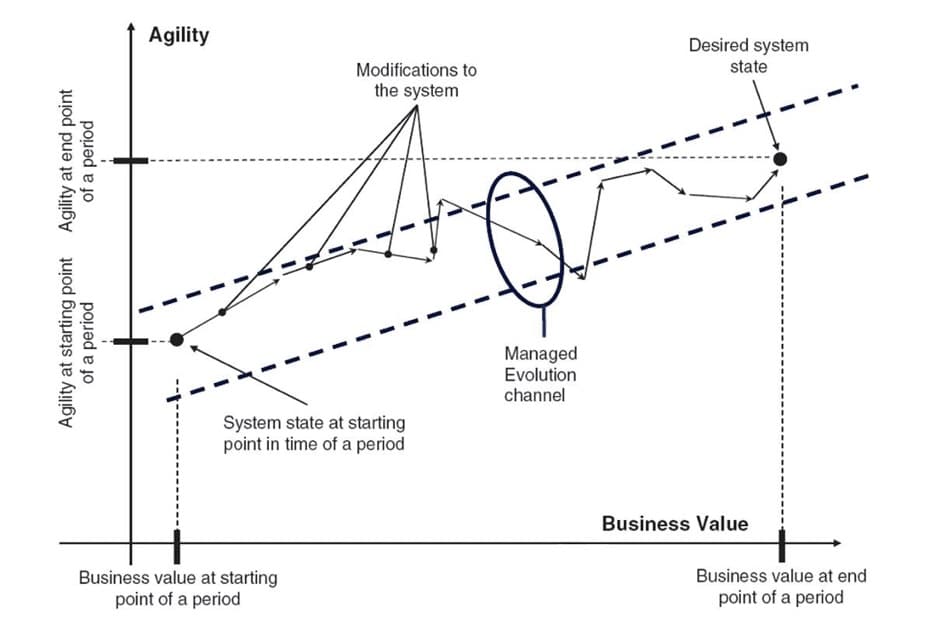
Evaluating architectural drift means knowing how an application has deviated from its original design. That process requires a baseline that shows sources of architectural technical debt such as complexity, modularity, and scalability. Depending on system complexity, establishing a baseline may require multiple iterations. The goal is to create a comprehensive representation of an application.
Without an accurate baseline, architects cannot assess the impact of deviations over time. They are forced to evaluate behaviors from a subset of data that reduces the validity of their decisions. However, a baseline in a continuous application modernization process is not static. As fixes are fed into the pipeline, baselines can change.
The cyclical nature of agile methodology and continuous improvement means analyzing the application and its architecture to avoid adding complexity and increasing technical debt. A comprehensive analysis requires data on static and dynamic behaviors.
From application analysis, architects gain observability that allows them to monitor architectural drift and identify problems. Early detection helps minimize drift as the application and its architecture remain in sync. This enables architects to manage their systems effectively. Not only do they understand the application’s current state, but they can also assess future trajectories.
Architects must ensure they are using tools that support dynamic baselines. From an established baseline, engineers can observe behaviors and analyze changes to reduce architectural drift and avoid application disruptions.
Use AI-Based Tools to Improve Productivity
Gartner sees AI-assisted software engineering taking on a more significant role in the software lifecycle. Their analysts envision relegating mundane development tasks to AI. They see AI performing the following:
- Creating systems that operate autonomously
- Developing model-building tools
- Managing the end-to-end governance of applications
- Enabling automation, orchestration, and scaling of products
- Generating classes of test data
Incorporating these capabilities into architectural observability tools allows software engineers to spend less time writing code. AI-augmented tools can accelerate and facilitate modernization and reduce technical debt.
Deploying AI-infused architectural observability tools removes time-consuming tasks from an architect’s workload. They allow developers to address architectural technical debt incrementally with fewer disruptions. The tools can evaluate changes in architecture and alert staff when thresholds have been reached, freeing developers to work on tasks with higher business value.
Create Internal Platforms for Accelerated Delivery
Setting up environments for development, testing, or support can be time-consuming. If solutions are vendor-agnostic, they may require multiple environments. Platform engineering tasks a dedicated team, building and operating self-service internal development platforms. These platforms are designed to optimize productivity and accelerate delivery.
For example, an architectural observability platform would provide internal teams with a set of tools and processes to statically and dynamically evaluate the behavior of an application’s architecture. The platform would ensure consistency in data acquisition and results. With ownership established, changes to the platform configuration would be restricted, ensuring the integrity of the environment.
In today’s development and release environments, changes happen quickly. No longer do months go by without an update. That creates a challenge for developers. How can they ensure they are working with the latest release? A dedicated team would be responsible for using architectural observability to ensure software architecture is current. Less time preparing an environment means more time available for other tasks.
Deploy an Architectural Observability Platform for an AI-Infused Platform
Architectural drift can sabotage a company’s efforts to modernize its applications. While IT departments may track application technical debt, they often dismiss the impact of architectural technical debt. They believe self-organized teams can address design issues. However, recent very public meltdowns at Southwest and the FAA have demonstrated what happens when architectural drift is ignored. Productivity declines, costs escalate, and potential risk increases.
Adding modern architectural observability tools allows development teams to assess architectural drift in parallel with technical debt. Parallel assessments ensure that architectural anomalies can be incorporated into the continuous application modernization queue for timely correction. Explore how vFunction’s architectural observability platform can accelerate your continuous modernization process by starting a free trial or requesting a demo.