


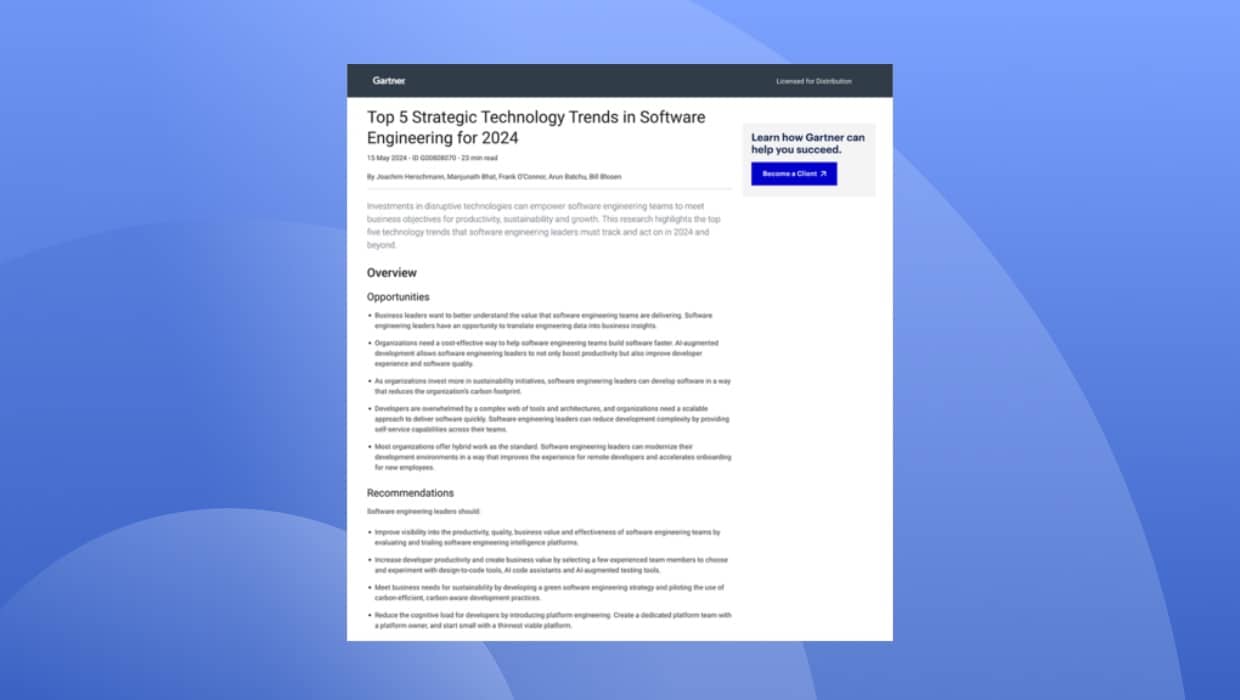

What is the Strangler Fig Pattern?
The term was coined in 2004 by Martin Fowler, Chief Scientist of Thoughtworks. He observed that strangler fig seeds germinate in the upper branches of a tree and their roots surround the tree as they gradually work their way down to the ground. As the strangler fig’s root system expands over many years, it eventually strangles its host tree. In essence, the strangler fig replaces the original tree.
Fowler saw this as a metaphor for how large software systems could be refactored by gradually implementing a new system that surrounds and slowly, perhaps over several years, strangles and ultimately replaces the original.
The Strangler Fig Pattern thus creates a new structure of microservices surrounding a monolithic legacy application. Each microservice implements a single function that either replaces a function in the original app or creates a new one.
As new microservices are added over time, they eventually take over all the functions of the original app, figuratively strangling it so that it is slowly replaced by the microservices architecture built around it.
How the Strangler Fig Pattern Works
Let’s take a closer look at how the Strangler Fig Pattern does its magic.
It starts with the introduction of an interface layer called a façade. All requests to the application go through the façade. At first, the façade is simply a direct pass-through to the legacy app. But as each new microservice is added, the façade redirects any call that invokes the associated function from the original app to the equivalent microservice.
Microservices are tested by running them in parallel with the original code to ensure that both respond identically to the same inputs. Once a microservice’s functionality is verified, the façade will always serve requests for that function to the microservice and never to the original app.
That function in the original code is then effectively replaced. As additional microservices are added and verified, the façade will eventually be serving all requests to the microservices and none to the original codebase. At that point, the original monolithic app is finally able to be decommissioned.
Related: What is a Monolithic Application? Everything you need to know
Why the Strangler Fig Pattern is Beneficial for Modernization
Because monoliths have hidden functionalities and dependencies interlaced throughout the codebase, it’s difficult for developers to untangle the morass to understand what the code is doing. Documentation is often inadequate if not entirely lacking, and with the original developers potentially gone, nobody on the engineering team has a comprehensive understanding of what the app does and how.
All these factors make implementing changes to monolithic apps very risky. As we’ve seen, alterations to any part of the code can have unforeseeable consequences. In addition, because undocumented functions or business processes may be hidden in the code, developers who are refactoring the app can easily overlook important functions and fail to include them in the new microservices implementation.
Any attempt to replace a monolithic app in one fell swoop is almost guaranteed to introduce bugs that will cause significant downtime once you switch over to the new codebase.
With the Strangler Fig Pattern, the transition from the original app to the new one is done step by step, one piece of functionality at a time. At each step, developers implement a single microservice and fully test it before incorporating it into the app. That in itself substantially reduces the potential that a change might break the app since the risk of a small change is much less than the risk of a large one.
Other benefits of employing the Strangler Fig Pattern include:
- You get immediate operational gains as each new microservice takes over, including greater adaptability, agility, and performance.
- Because you can run each microservice in parallel with the original code for QA purposes, downtime is drastically reduced.
- Rolling back a change that isn’t working correctly is far simpler. Each new microservice deployment can be quickly and cleanly reversed.
- You don’t have to maintain two separate codebases (the original and the new).
- Since the app is never taken offline, you can implement the modernization project at a pace that’s comfortable for your team (and budget).
Four Best Practices to Prepare for the Strangler Fig Pattern
Before you can leverage the Strangler Fig Pattern, there is some work to do. Prior to having a decoupled microservice in hand and ready to deploy, architects starting with a monolith should do a few things…
Examples include identifying service domains, consolidating duplicate services, and determining which functionality actually makes sense to decompose into an individual microservice. Let’s look at some of these best practices in action.
Best Practice #1 – Automate the Identification of Services and Domains
Surveys have shown that the days of manually analyzing a monolith using sticky notes on whiteboards take too long, cost too much and rarely end in success. Which architect or developer in your team has the time and ability to stop what they’re doing to review millions of lines of code and tens of thousands of classes by hand? Large monolithic applications need an automated, data-driven way to identify potential service boundaries.
What You Can Do
Let’s select a readily available, real-world application as the platform in which we’ll explore these best practices. As a tutorial example for Java developers, Oracle offers a medical records (MedRec) application — also known as the Avitek Medical Records application,which is a traditional monolith using WebLogic and Java EE. Using vFunction, we will initiate a “learning” phase using dynamic analysis, static analysis and machine learning based on the call tree and system flows to identify ideal service domains.
In Image 1, we see a services graph in which services are shown as spheres of different sizes and colors, as well as lines (edges) connecting them. Each sphere represents a service that vFunction has automatically identified as related to a specific domain. These services are named and detailed on the right side of the screen.
The size of the sphere represents the number of classes contained within the service. The colors represent the level of class “exclusivity” within each service, referring to the percentage of classes that exist only within that service, as opposed to classes shared across multiple services.
Red represents low exclusivity, blue medium exclusivity and green high exclusivity. Higher class exclusivity indicates better boundaries between services, fewer interdependencies and less code duplication. Taken together, these traits indicate that it will be less complex to refactor highly-exclusive services into microservices.
The solid lines here represent common resources that are shared across the services (Image 2). Common resources include things like beans, synchronization objects, read-only DB transactions and tables, read-write DB transactions and tables, websockets, files and embedded files. The dashed lines represent method calls between the services (Image 3).
The black sphere in the middle represents classes still in the monolith, which contains classes and resources that are not specific to any particular domain, and thus have not been selected as candidates for extraction.
By using automation and AI to analyze and expose new service boundaries previously contained in the black box of the monolith, you are now able to begin manipulating services inside of a suggested reference architecture that has cleared the way to make better decisions based on data-driven analysis.
Best Practice #2: Consolidate Functionality and Avoid Duplication
When everything was in the monolith, your visibility was somewhat limited. If you’re able to expose the suggested service boundaries, you can begin to make decisions and test design concepts — for example, identifying overlapping functionality in multiple services.
What You Can Do
When does it make sense to consolidate disparate services with similar functionality into a single microservice? The most basic example is that, as an architect, you may see an opportunity to combine two services that appear to overlap — and we can identify these services based on the class names and level of class exclusivity.
In the services graph (Image 4), we see two similar chat services outlined with a white ring: PatientChatWebSocket and PhysicianChatWebSocket. We can see that the physician chat service (red) has 0% dynamic exclusivity, and that the patient chat service (blue) has slightly higher exclusivity at 33%.
Neither of these services is using any shared resources, which indicates that we can merge these into a single service without entangling anything by our actions.
By merging two similar services, you are able to consolidate duplicate functionality as well as increase the exclusivity of classes in the newly merged service (Image 5). As we’re using vFunction Platform in this example, everything needed to logically bind these services is taken care of — classes, entry points and resources are intelligently updated.
Merging services is as simple as dragging and dropping one service onto the other, and after vFunction Platform recalculates the analysis of this action, we see that the sphere is now green, with a dynamic exclusivity of 75% (Image 6). This indicates that the newly-merged service is less interconnected at the class level and gives us the opportunity to extract this service with less complexity.
Best Practice #3: Create Accurate and Meaningful Names for Services
We all know that naming things is hard. When dealing with monolithic services, we can really only use the class names to figure out what is going on. With this information alone, it’s difficult to accurately identify which classes and functionality may belong to a particular domain.
What You Can Do
In our example, vFunction has automatically derived service domain names from the class names on the right side of screen in Image 7. As an architect, you need to be able to rename services according to your preferences and requirements.
Let’s now go back to the two chat services we merged in the last section. Whereas previously we had a service for both the patient and physician chat, we now have a single service that represents both profiles, so the name PatientChatWebSocket is no longer accurate, and may cause misunderstandings for other developers working on this service in the future. We can decide to select a better name, such as ChatService (Image 7).
In Image 8, we can see another service named JaxRSRecordFacadeBroker (+2). The (+2) part here indicates that we have entry points belonging to multiple classes. You may find this name unnecessarily descriptive, so you can change it simply to RecordBroker.
By renaming services in a more accurate and meaningful way, you can ensure that your engineering team can quickly identify and work with future microservices in a straightforward way.
Best Practice #4: Identify Functionality That Shouldn’t Be a Separate Microservice
What qualities suggest that functionality previously contained in a monolith deserves to be a microservice? Not everything should become a microservice, so when would you want to remove a service as a candidate for separation and extraction?
Well, you may decide that some services don’t actually belong in a separate domain, for example a filter class that simply filters messages. Because this isn’t exclusive to any particular service, you can decide to move it to a common library or another service in the future.
What You Can Do
When removing functionality as a candidate for future extraction as a microservice, you are deciding not to treat this class as an individual entry point for receiving traffic. Let’s look at the AuthenticatingAdministrationController service (Image 9), which is a simple controller class.
In Image 9, we can see that the selected class has low exclusivity by the red color, and also that it is a very small service, containing only one dynamic class, one static class and no resources. You can decide that this should not be a separate service by itself and remove it by dragging and dropping it onto the black sphere in the middle (Image 10).
By relocating this class back to the monolith, we have decided that this particular functionality does not meet the requirements to become an individual microservice.
Related: Simplify Refactoring Monoliths to Microservices with AWS and vFunction
Implement the Strangler Fig Pattern with vFunction and AWS Refactor Spaces
vFunction is an AWS Partner, where we have integrated with AWS Migration Hub Refactor Spaces to utilize the Strangler Fig Pattern, build microservices and deploy them into AWS environments.
The refactoring process begins with developers using vFunction to generate an automated, AI-based analysis that quantifies the complexity of monolithic legacy apps. The platform uses dynamic analysis and visualization tools to view each app running in real-time and to record its behavior and the code paths it follows.
From there, Refactor Spaces establishes, maintains, and manages the infrastructure needed to support the incremental transformation of a legacy app from a monolith to microservices. It automatically creates a multi-account environment and orchestrates AWS services across accounts to facilitate the refactoring process.
In image 11, we can see the Strangler Fig Pattern in action with an example Order Management System application. Traffic is being split between the existing monolith and the new microservice hosted in the AWS cloud.
Refactor Spaces implements the Strangler Fig Pattern for the target application, creating separate accounts for the original app and the façade. vFunction creates its own account for use in decomposing the monolithic app into microservices. Refactor Spaces allows developers to easily route and manage communications traffic throughout the environment, which is key for implementing the Strangler Fig Pattern with multiple microservices.