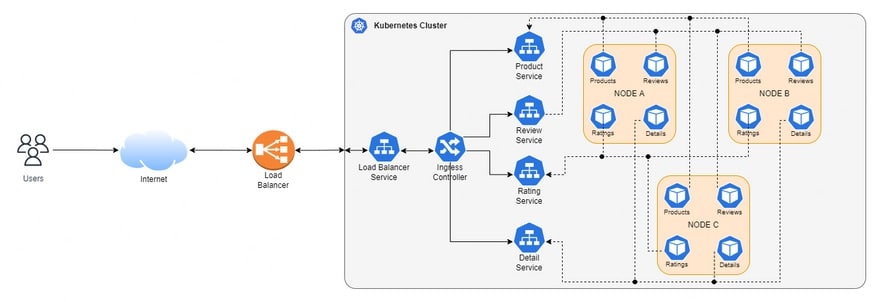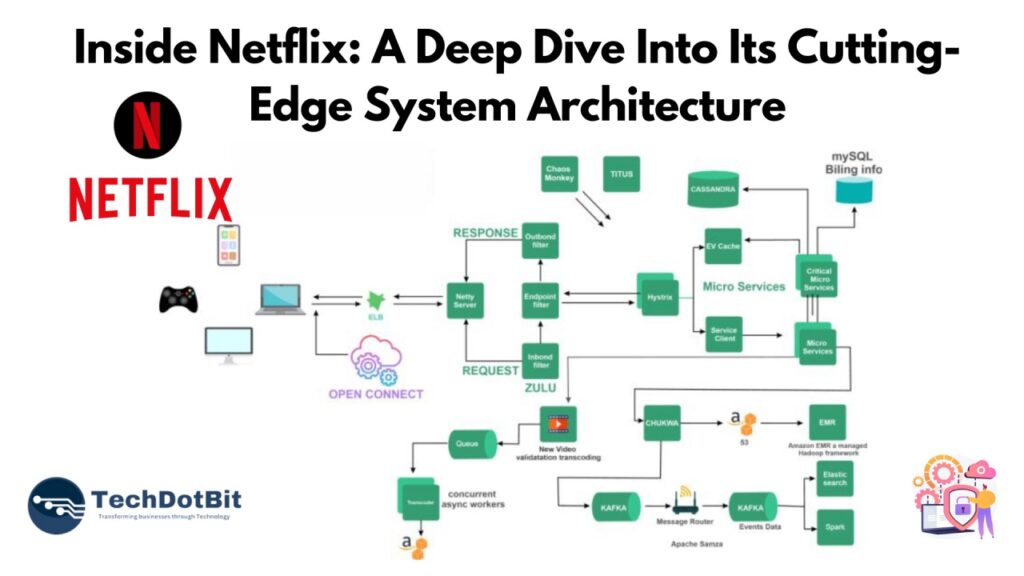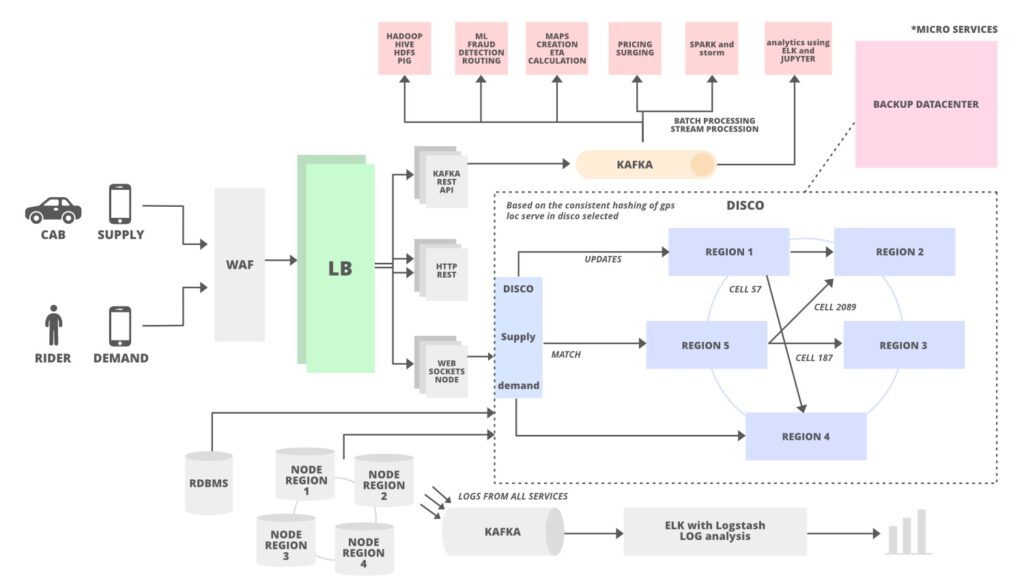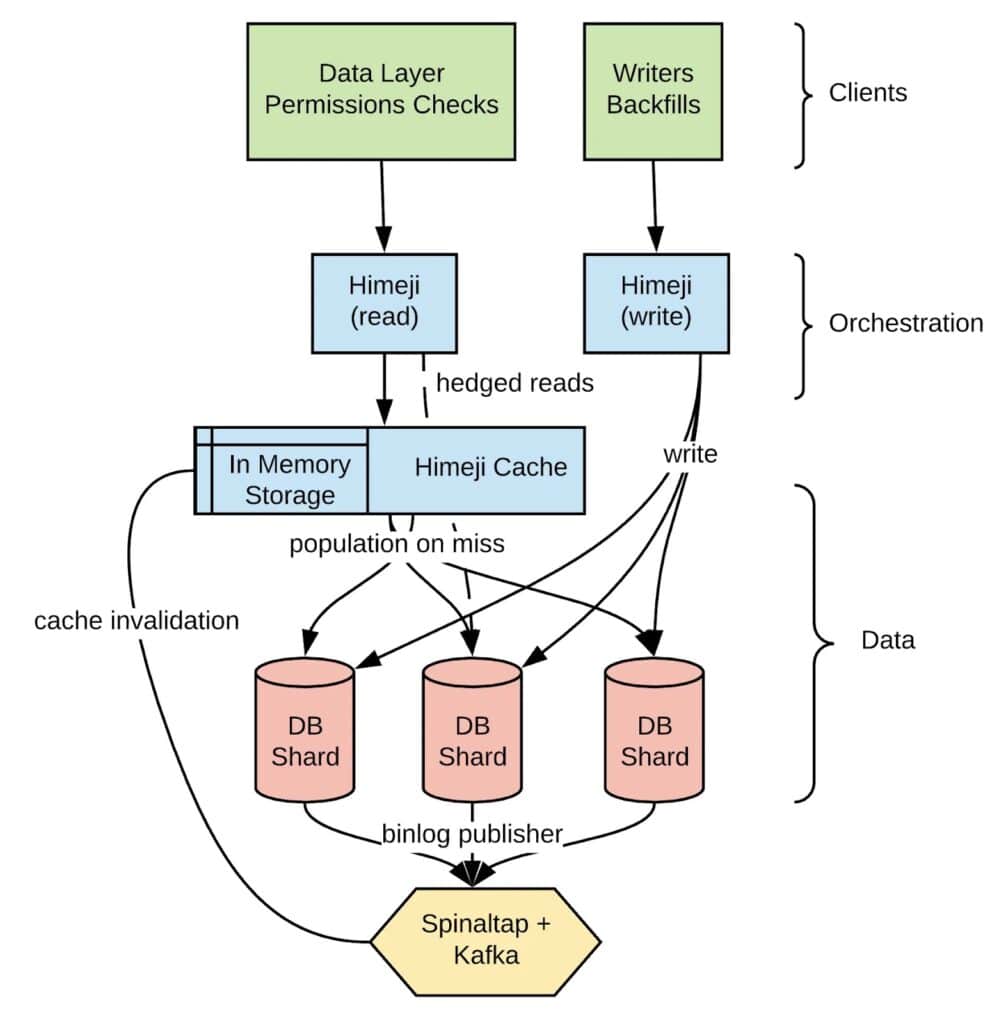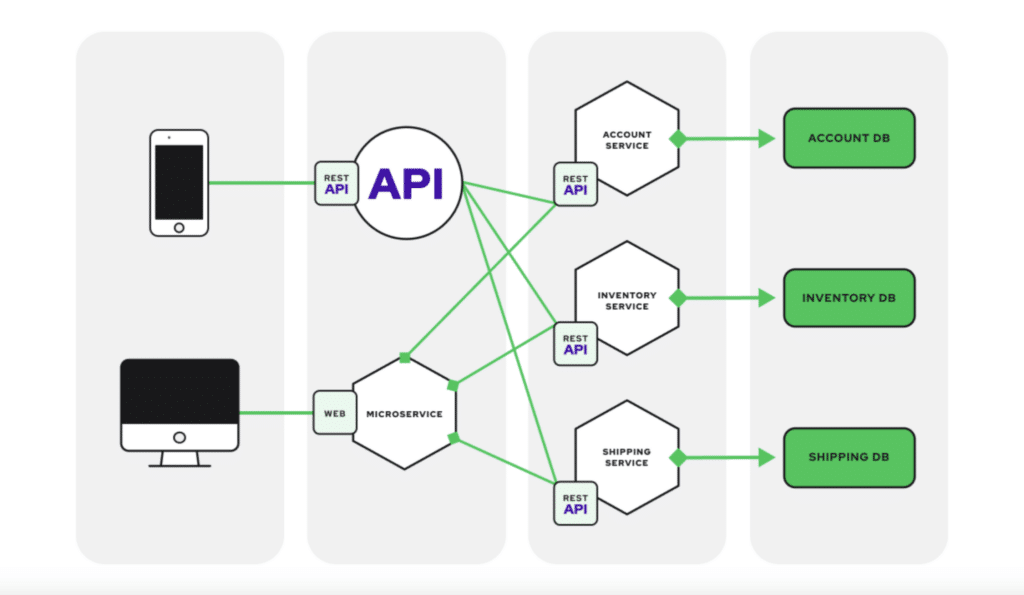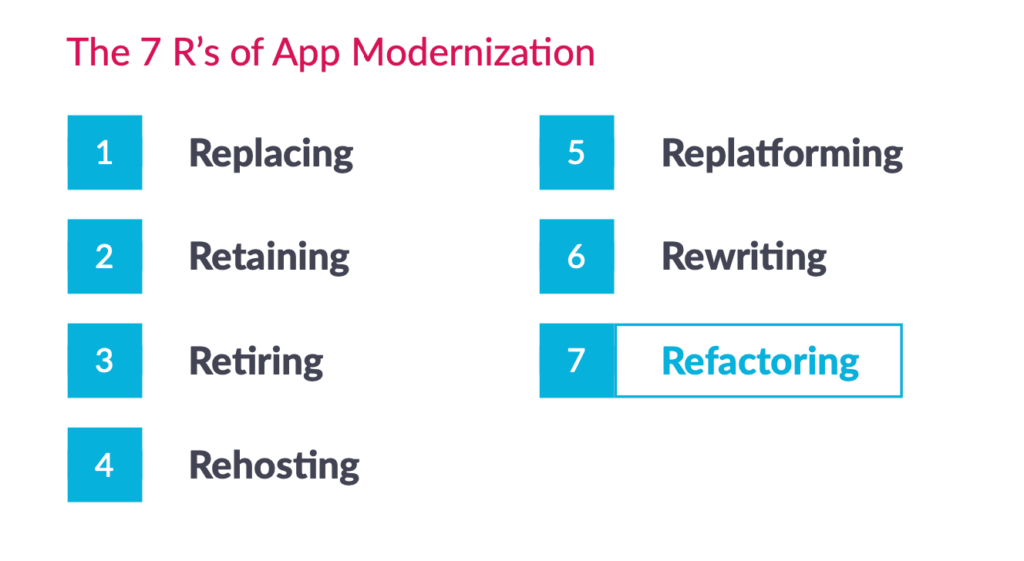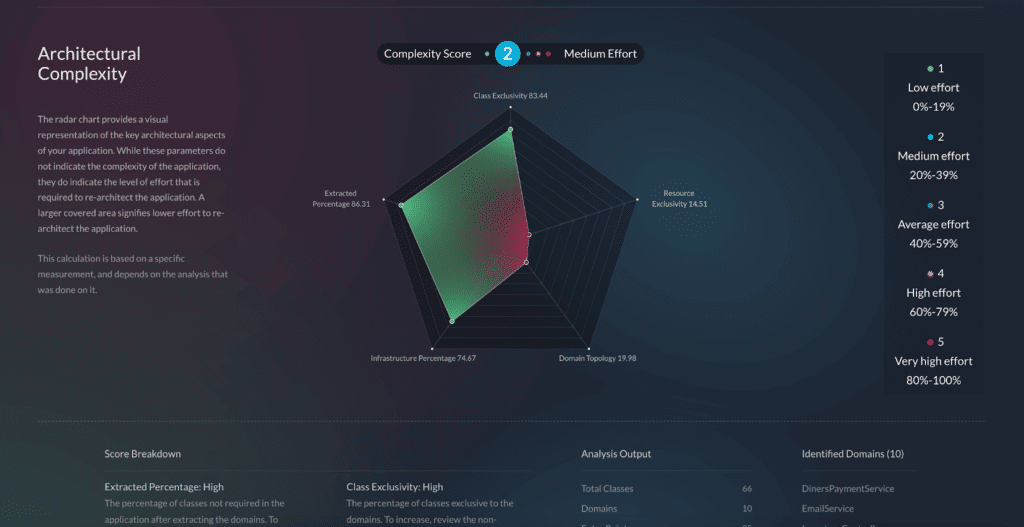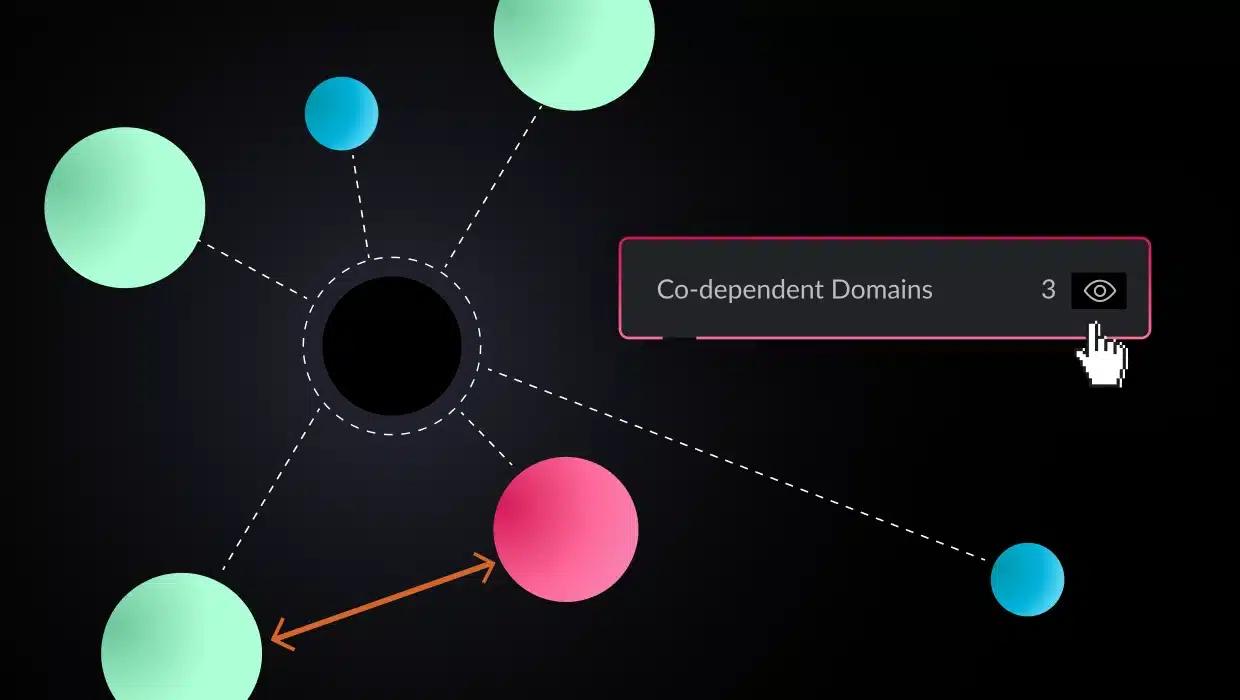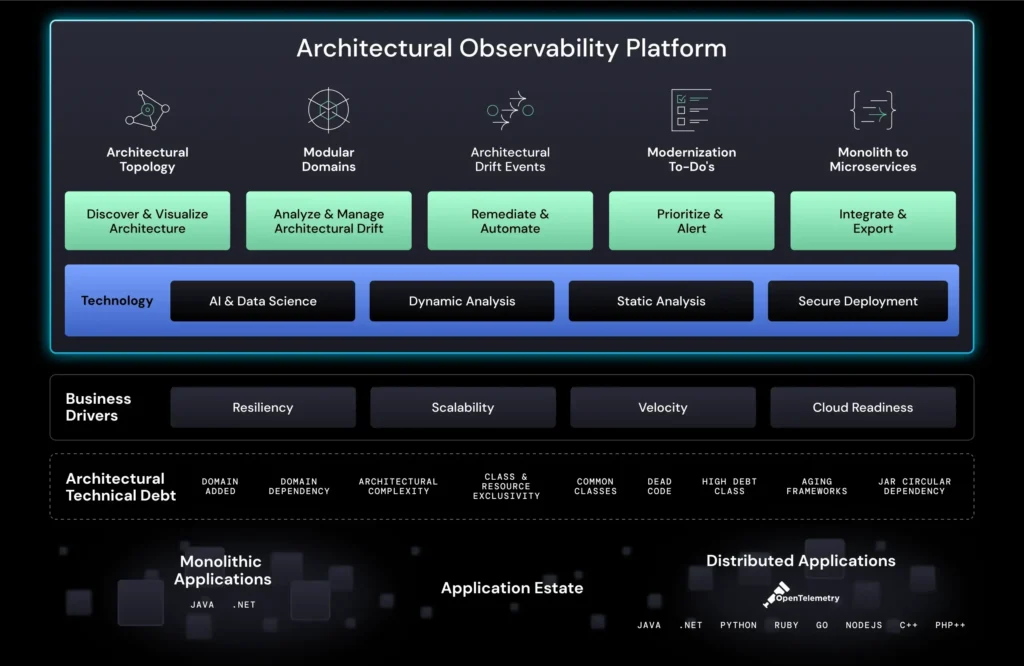
Microservices architecture has revolutionized software development. Decomposing monolithic applications into smaller, independently deployable services brings agility, scalability, and resilience to development teams. This modularity also introduces complexities, particularly when it comes to testing.
A microservices testing strategy is essential for managing this complexity. It involves focusing on the separate testing of each service, its APIs, and communication. Techniques like mocking and stubbing make it possible to get realistic responses without requiring computed logic to produce the response. The testing strategy should support continuous integration and continuous deployment (CI/CD) to ensure reliability.
Thorough testing is crucial to ensure that these services work together seamlessly. In this blog, we’ll explore strategies, tools, and best practices for microservices testing to help you build robust and reliable applications.
What is microservices testing?
Microservices testing verifies and validates that microservices and their interactions function as expected. It involves testing each service in isolation (unit tests, integration tests), and how services communicate and exchange data (component tests, contract tests and End-to–end tests).
Software testing ensures that microservices operate efficiently and effectively. Various testing methodologies, including exploratory testing and the testing pyramid, are essential to adapt to the complexities of microservice architectures. Both pre-production and production testing approaches are necessary to maintain the reliability and performance of these services.
The primary goal of microservices testing is to identify and fix defects early in the development cycle, ensuring the overall system remains stable and performant as individual services evolve.
Types of microservices tests
Microservices testing encompasses a variety of test types, each serving a specific purpose in ensuring the overall quality and reliability of the system. A well-configured test environment is crucial for microservices testing, as it allows components to be tested in isolation or alongside other services without impacting production systems.
Unit testing

Unit testing focuses on evaluating individual components or units of code in isolation. Its primary goal is to ensure that each unit of code functions correctly according to its specifications, without relying on external systems or dependencies, helping identify and fix issues early in the development cycle. Typically, specific units of code, like individual methods, do not exist in isolation. Hence, the usage of mocks and stubs becomes imperative. While utilizing mocks in unit tests can be beneficial, it’s important to be aware of potential challenges, such as maintenance overhead and the risk of misaligned understandings of system behavior. To mitigate these challenges, focus on testing crucial units of functionality rather than superficial aspects of the code.
Integration testing
Integration testing focuses on verifying the functionality of an isolated microservice holistically considering the various integration layers like message queues, datastores and caches. It plays a crucial role in identifying and resolving issues that arise when a microservice is considered as a subsystem and validates its functional correctness. It helps ensure correct data flow between the various integration layers and graceful errors handling.
Common integration testing techniques include testing API endpoints, message queues, and database interactions to validate the successful exchange of data and the proper handling of various scenarios.
Component testing
Component testing evaluates a group of related microservices as a single unit, focusing on verifying the behavior and functionality of a specific component or subsystem within the larger system.
By treating a collection of microservices as a cohesive component, this testing approach allows for a more comprehensive assessment of how different services collaborate to achieve specific functionalities. It bridges the gap between integration testing (which isolates individual services) and end-to-end testing (which examines the entire system). Component testing can uncover issues that might not be apparent when testing services in isolation, such as inconsistencies in data handling, unexpected side effects, or performance bottlenecks. Component tests provide valuable insights into the functionality and performance of a specific subsystem within the microservices architecture.
Contract testing

Contract testing verifies that the interactions between microservices adhere to predefined contracts or agreements between teams. It focuses on validating that the inputs and outputs of each service conform to the agreed-upon contract, ensuring that changes to one service do not inadvertently disrupt the functionality of other dependent services.
By establishing and enforcing contracts, teams can work autonomously while maintaining confidence that their changes will not negatively impact the overall system. Contract testing promotes loose coupling between services and enables them to evolve independently, fostering agility and flexibility in the development process.
End-to-end testing
End-to-end testing tests the complete system from the user’s perspective, simulating real-world scenarios to validate the entire application flow, from UI interactions to backend services and database operations.
This approach ensures all components work cohesively to deliver the expected user experience. End-to-end tests help identify potential issues arising from interactions between services, databases, and external systems.
End-to-end testing provides a critical final check to ensure the system functions correctly. It validates both the individual services and their integration within the larger ecosystem.
How to test microservices
Testing microservices requires a combination of traditional strategies and specialized techniques to address the unique challenges of this architectural style. It is a crucial part of the software development lifecycle (SDLC), especially in a modern microservices architecture, e.g. component testing and contract testing were generally not considered for monolithic applications.
Testing strategies
You can combine and adapt these strategies to fit your needs and constraints; the key is establishing a clearly defined testing process covering functional and non-functional requirements.
Documentation-first strategy
Documentation-first strategy prioritizes clear contracts or specifications for each microservice, detailing its behavior and interactions. This enables independent development and testing while ensuring adherence to agreed-upon specifications.
Stack in-a-box strategy
Creates isolated testing environments mirroring the production technology stack as closely as possible, allowing for comprehensive testing without affecting the live system. This builds confidence in microservice reliability and performance before deployment.
Shared testing instances strategy
Optimizes resource utilization by sharing test environments among teams. This ensures that all the relevant teams test on the same environment, therefore, avoiding version mismatches. This requires careful coordination to avoid conflicts and maintain data integrity.
Stubbed services strategy
Replaces dependencies with stubs or mocks for isolated testing, enabling faster and more focused testing without relying on external services.
Automated microservices testing

Manual testing of microservices can be time-consuming and error-prone, especially as the system grows in complexity. Test automation brings numerous benefits.
Benefits of automated testing
Automated testing offers many advantages in microservices testing. It enables faster feedback loops, allowing developers to assess the impact of code changes quickly and proactively address any issues. Automation streamlines the testing process, eliminating the need for repetitive, tedious manual tasks and allowing developers to focus on more valuable activities.
By reducing human error, automated tests ensure consistent, reliable, and repeatable results, providing a solid foundation for informed decision-making. Their seamless integration with CI/CD pipelines enables thorough regression testing with every code change, proactively preventing regressions and maintaining the system’s integrity.
Steps to implement automated testing
There are many ways to implement automated testing for microservices. While you’ll need to validate your stack and environment to find the best approach for you, the general way to approach it is as follows:
- Choose the right tools: Select testing frameworks and tools that are compatible with your technology stack and support various test types.
- Write testable code: Design your microservices with testability in mind. Use clear separation of concerns, dependency injection, and well-defined interfaces to make testing easier.
- Create comprehensive test suites: Develop various tests, including unit tests, integration tests, component tests, and end-to-end tests, to cover different aspects of your system.
- Integrate with CI/CD: Incorporate automated tests into your CI/CD pipeline to ensure that tests are run automatically with every code change.
- Monitor and maintain: Regularly review and update your tests to keep them relevant and effective as your system evolves.
By embracing automated testing, you can significantly improve the quality and reliability of your microservices applications while streamlining your development process.
Microservices testing tools
Many tools and frameworks are designed to support microservices testing. Here’s an overview of some popular options categorized by test type.
Unit testing tools
JUnit and NUnit are unit-testing frameworks most frequently used by Java and .NET developers respectively, allowing them to create and execute comprehensive unit tests, ensuring the reliability of their microservices’ core components.
Meanwhile, Mockito simplifies the process of isolating units of code for testing by enabling the creation of test doubles (mocks) for dependencies. This allows for focused and controlled unit testing, promoting a deeper understanding of individual components’ behavior and interactions within the broader microservices architecture.
Integration testing tools
Postman is a user-friendly integration testing tool with a comprehensive feature set. It enables teams to design, execute, and monitor API interactions efficiently, making it a versatile tool for testing and development.
WireMock, another integration testing tool, specializes in creating stubs and mocks for HTTP-based APIs. WireMock simulates the behavior of external services, allowing developers to isolate individual microservices for testing. This provides greater control over the testing environment and makes it easier to explore various scenarios.
Testcontainers provide Docker containers for lightweight instances of databases, message brokers, web browsers, etc. They simplify integration testing by forgoing the need for tedious mocking and complicated environment configurations.
Component testing tools
Arquillian is for Java EE applications. It streamlines the complexities associated with component testing, enabling developers to test individual or groups of components seamlessly within a controlled and containerized environment.
PactFlow takes a different approach, focusing on contract testing to ensure compatibility between microservices. By verifying that interactions between services adhere to predefined agreements by teams, Pact promotes independent evolution and minimizes the risk of integration issues.
End-to-end testing tools
Selenium is used solution for automating web browsers, enabling teams to create and execute tests that mimic real user interactions, ensuring the seamless functionality of the entire application from the user’s perspective.
Cucumber supports behavior-driven development (BDD) by fostering collaboration among developers, testers, and business stakeholders. It facilitates the creation of executable specifications in a clear and accessible format.
Applying architecture governance to support microservices testing
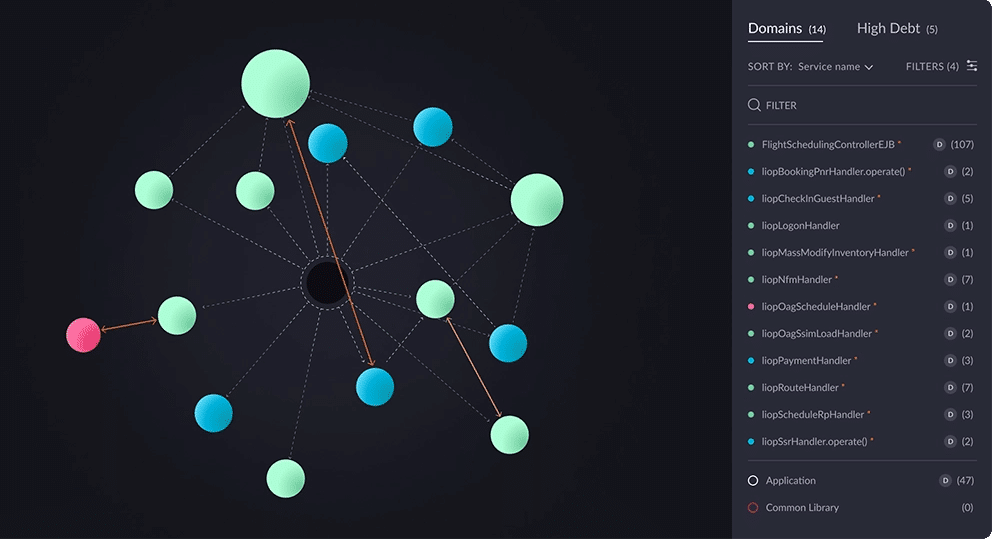
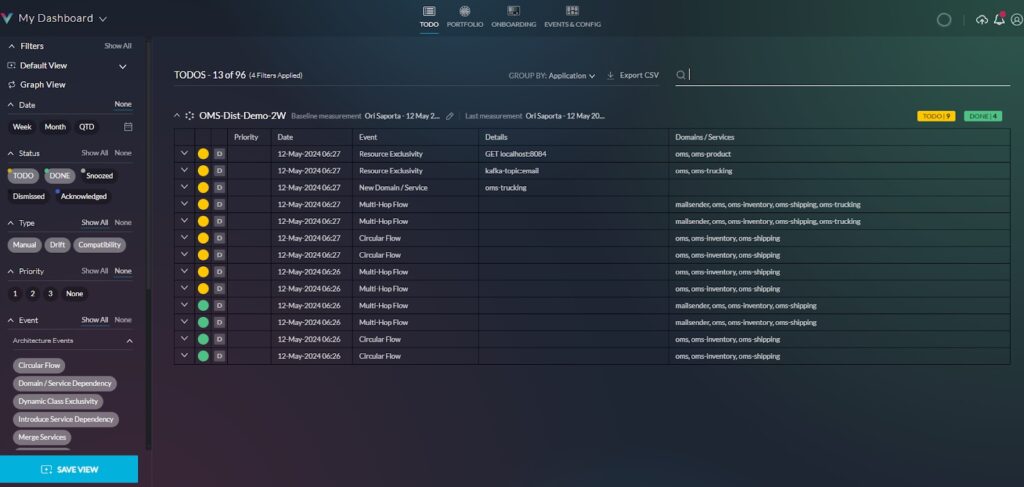
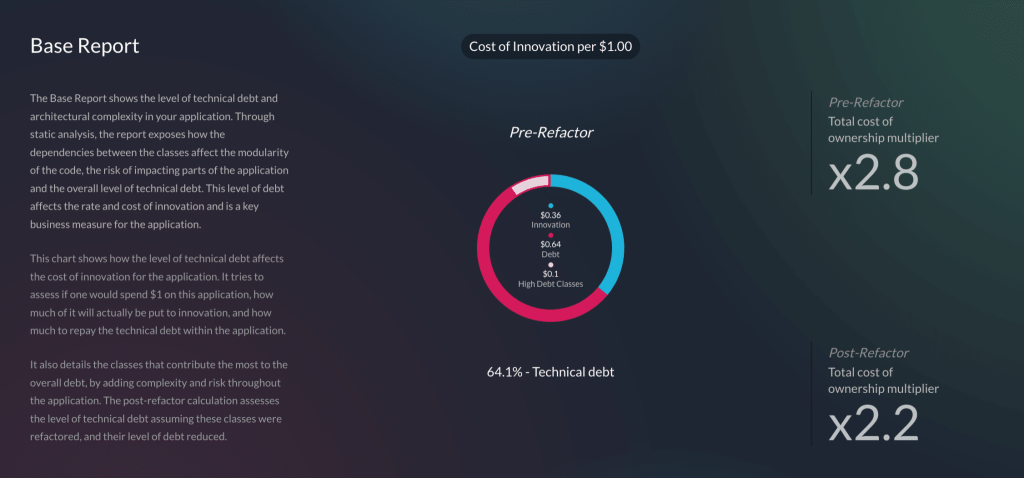
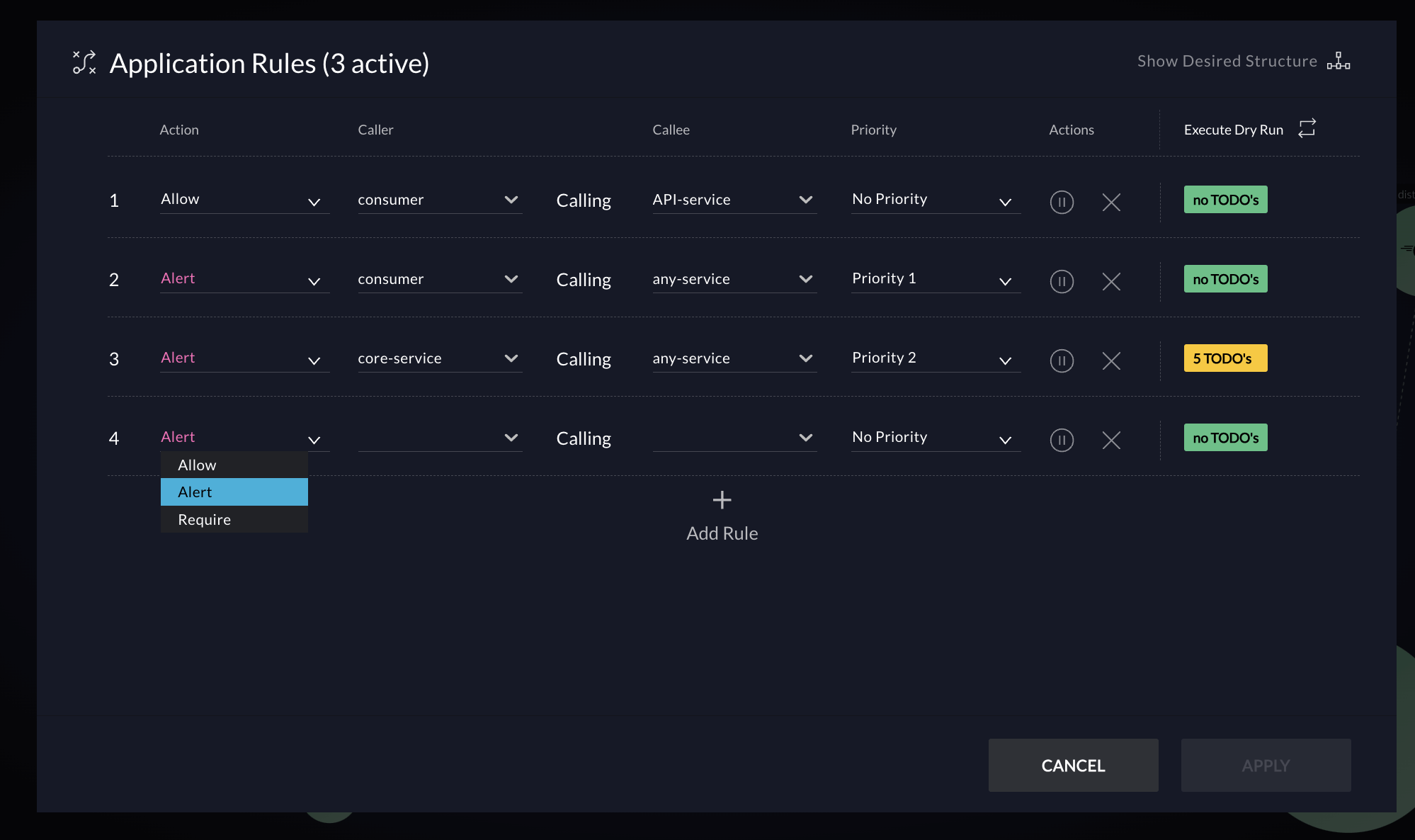
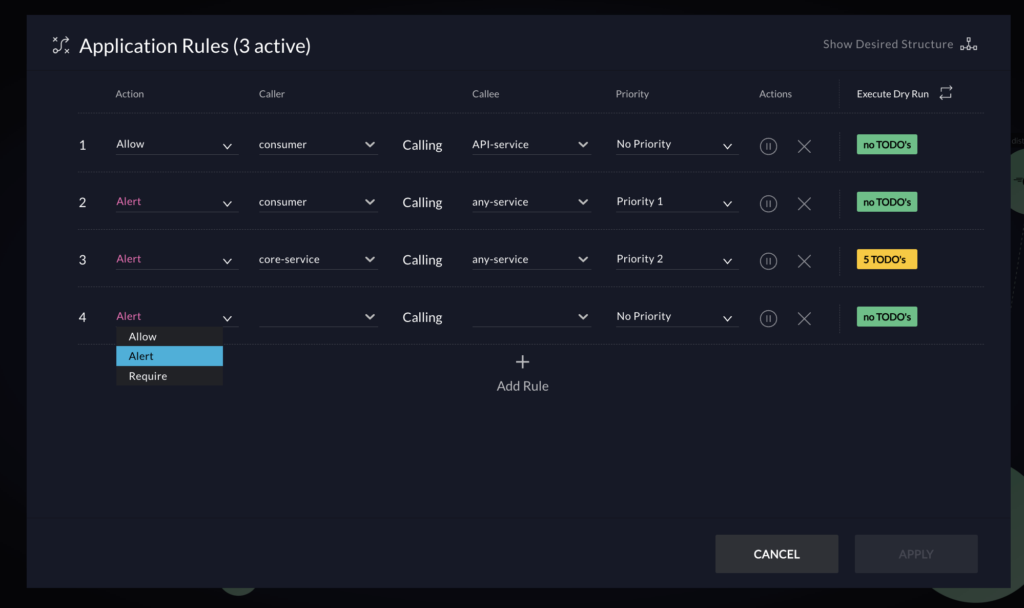
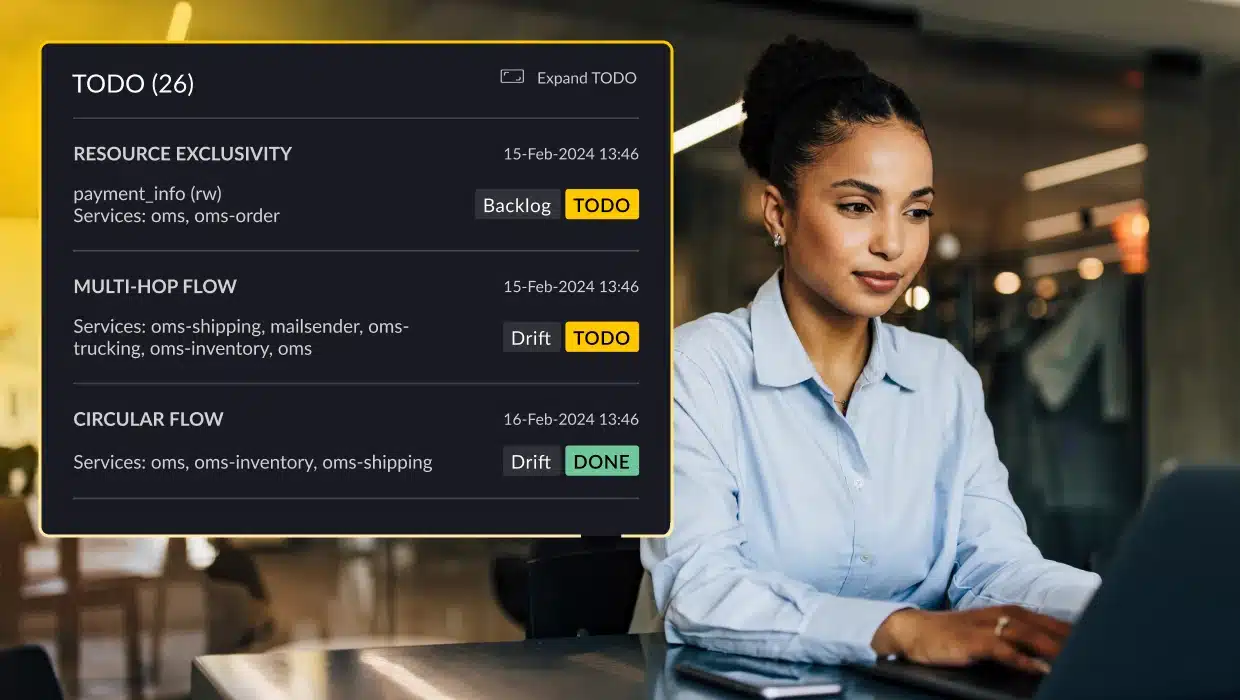
vFunction recently introduced architecture governance to its architectural observability platform to prevent and control microservices sprawl.
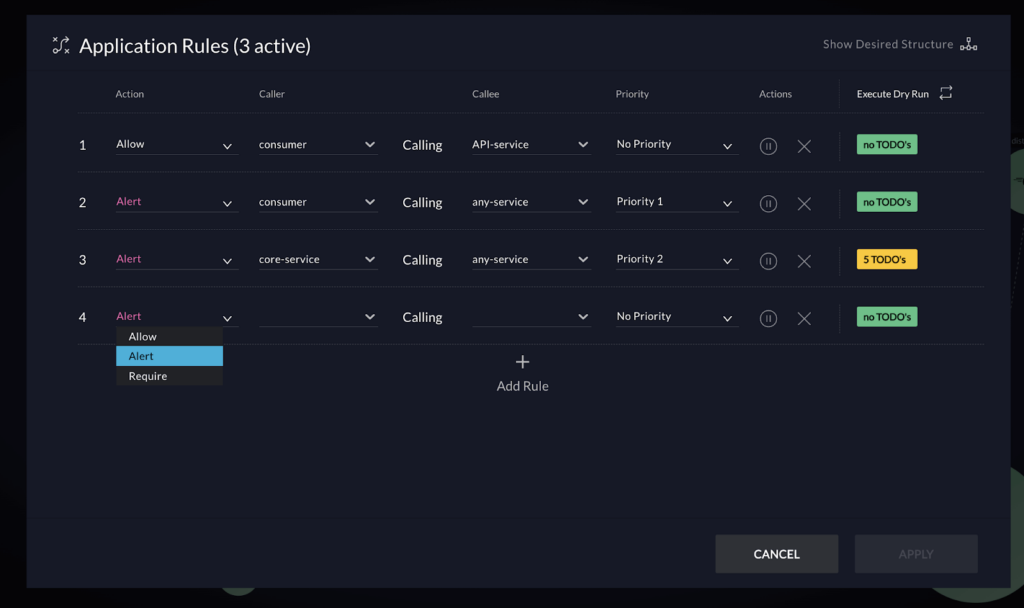
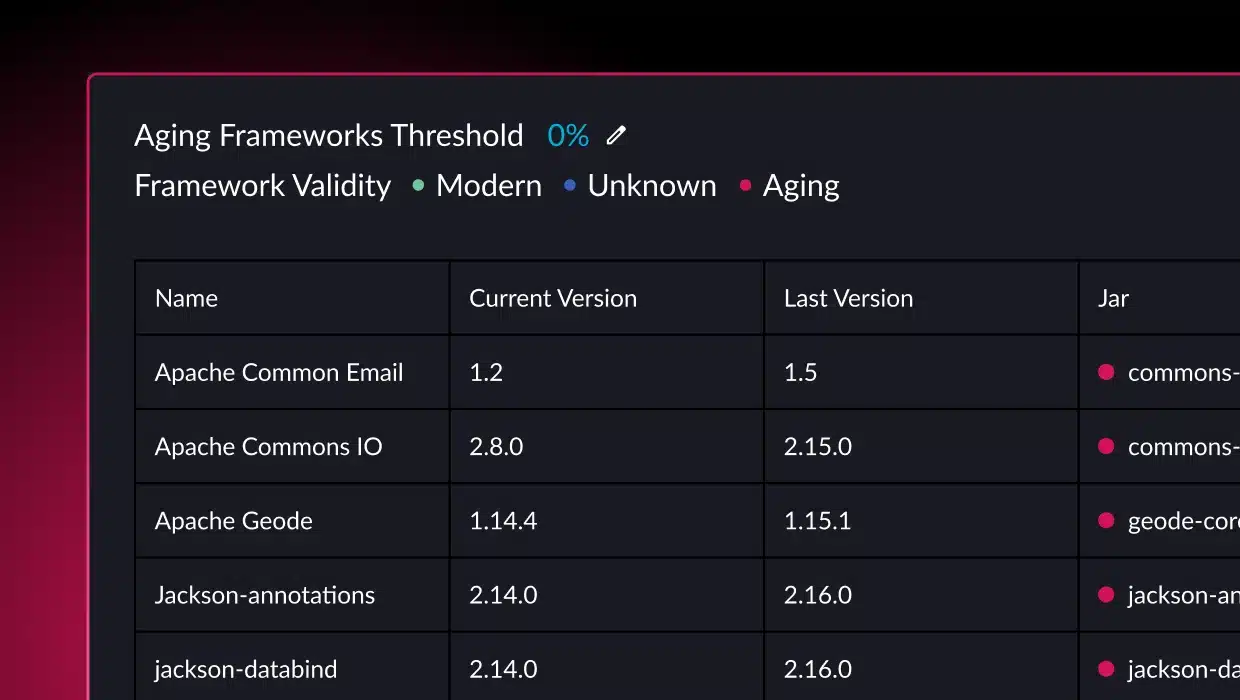
By enforcing clear standards and rules architecture governance creates a well-defined structure, making isolating and testing individual components easier. By identifying dependencies and potential bottlenecks, governance helps streamline testing workflows, reduces complexity, and minimizes the risk of errors. It also ensures that any architectural drift is detected early, allowing teams to address issues proactively and maintain system resilience, scalability, and performance during testing and in production.
Microservices testing best practices
Effective microservices testing is essential for maintaining high-quality and reliable applications. Here are some key practices to consider:
- Establishing a robust testing environment: Create dedicated test environments that closely mirror your production environment. This includes replicating infrastructure, configurations, and dependencies to ensure accurate and reliable test results.
- Ensuring test data integrity: Use realistic and representative test data that covers various scenarios and edge cases. To maintain data integrity, isolate test data from production data and regularly refresh test environments.
- Continuous integration and continuous deployment (CI/CD) practices: Integrate automated tests into your CI/CD pipeline to ensure you run tests with every code change. This enables early detection of issues and prevents regressions from reaching production.
- Shift-left testing: Incorporate testing early in the development cycle. The ability to test code earlier helps identify and address issues sooner, reducing the cost and effort of fixing them later.
- Observability and monitoring: Implement robust monitoring and logging to gain insights into the behavior of your microservices in production. This helps identify performance bottlenecks, errors, and anomalies that may require further testing.
- Use architectural observability to identify the root cause of issues by identifying unnecessary dependencies or multihop flows in software architecture. This is in contrast to the symptoms of problems, such as incidents or outages, identified by APM observability tools. By correlating APM incidents with architectural issues, teams can significantly reduce mean time to repair (MTTR).
- Collaboration and communication: Foster collaboration between developers, testers, and operations teams to ensure that everyone is aligned on testing goals and strategies. Effective communication helps identify and resolve issues quickly.
By following these best practices, you can establish a solid foundation for microservices testing and build confidence in the quality and reliability of your applications.
Common challenges in microservices testing

Microservices testing presents a unique set of challenges due to the interconnected and distributed nature of the architecture. Identifying and addressing integration issues can be complex.
With numerous services interacting, pinpointing the root cause of a failure typically requires thorough integration testing and effective logging mechanisms to trace the flow of data and identify bottlenecks or inconsistencies.
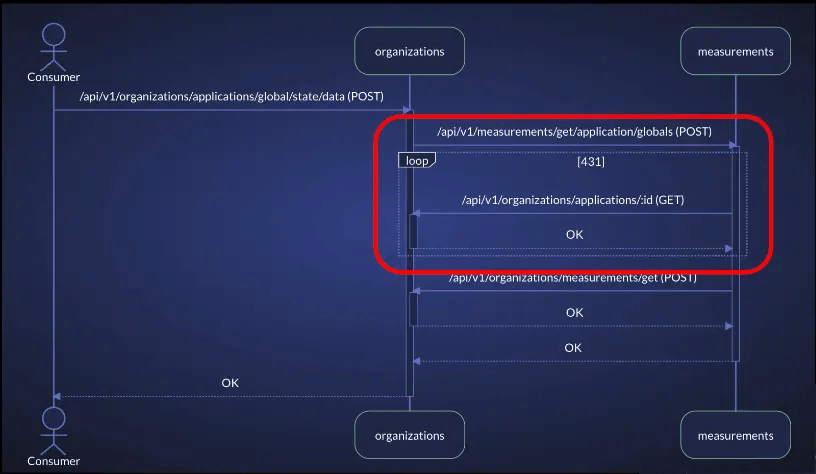
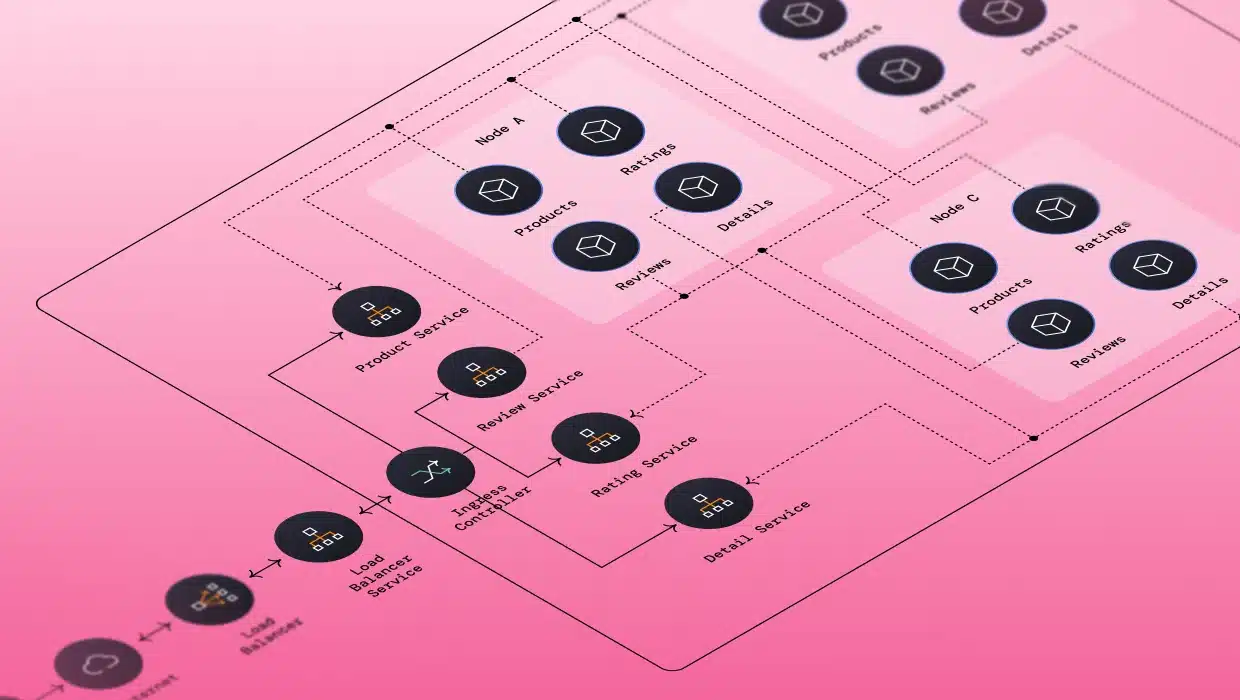
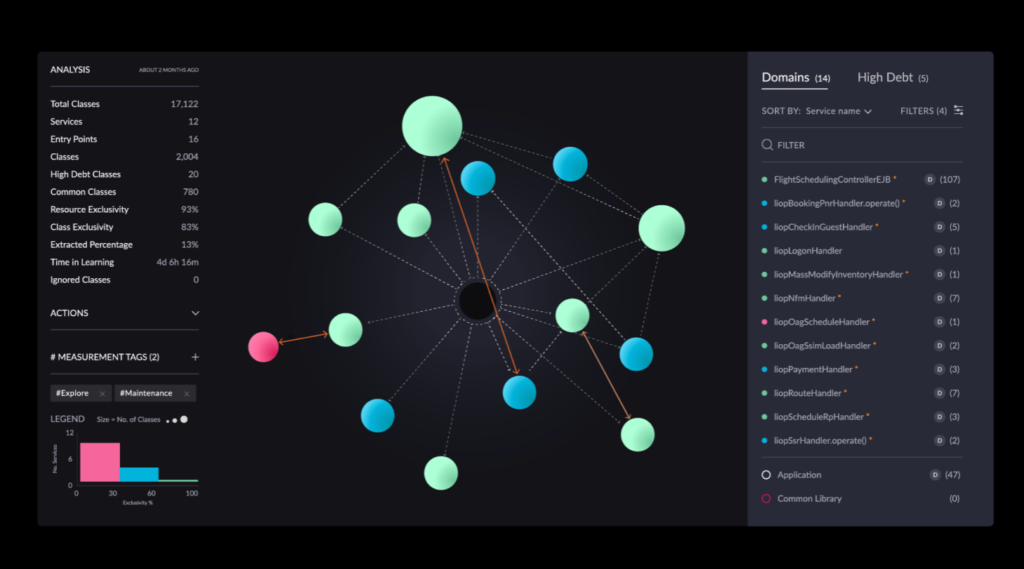
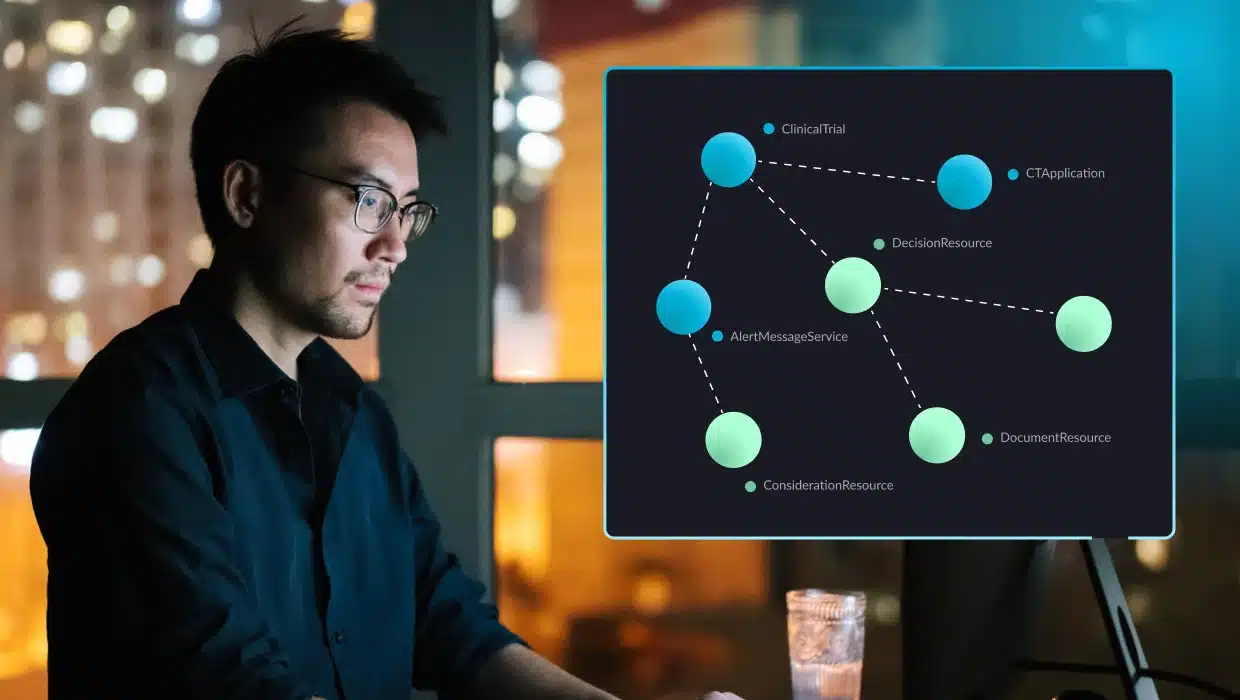
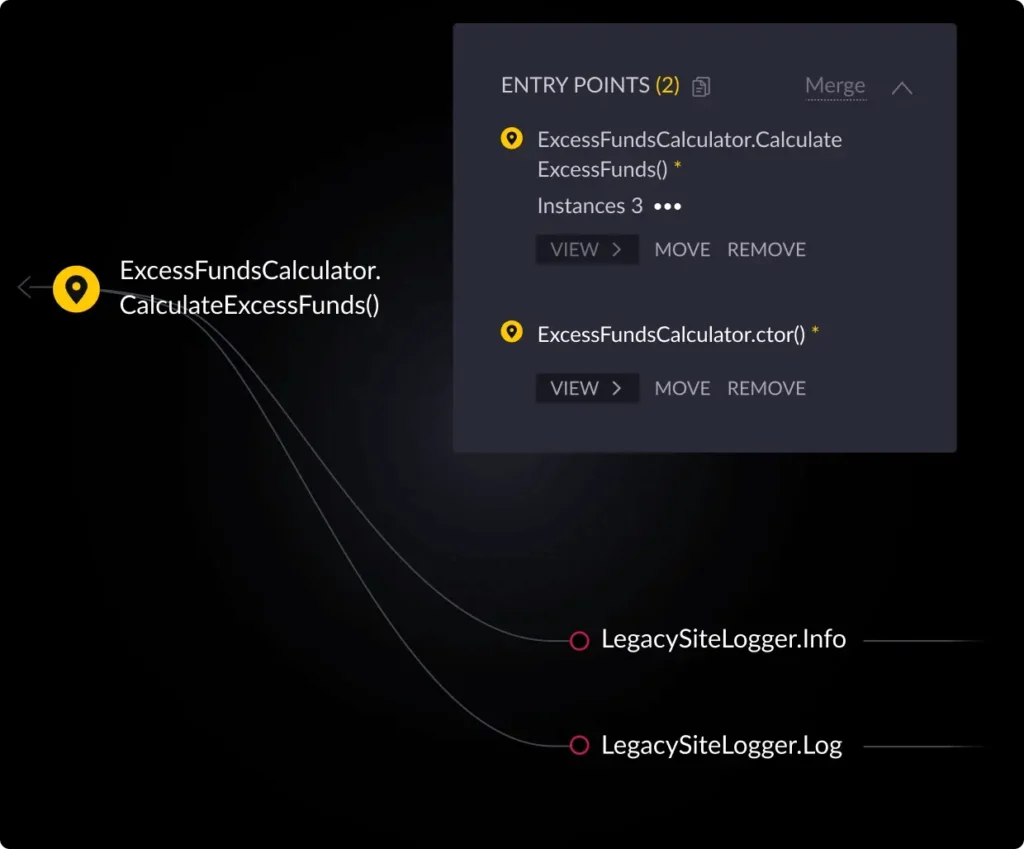
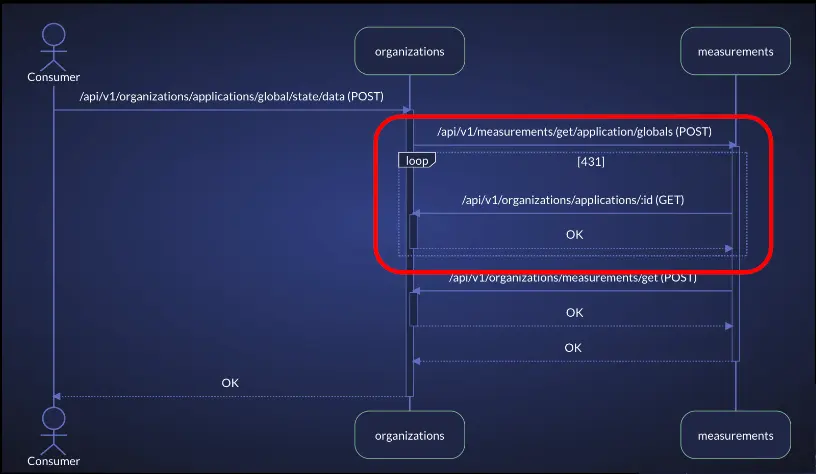
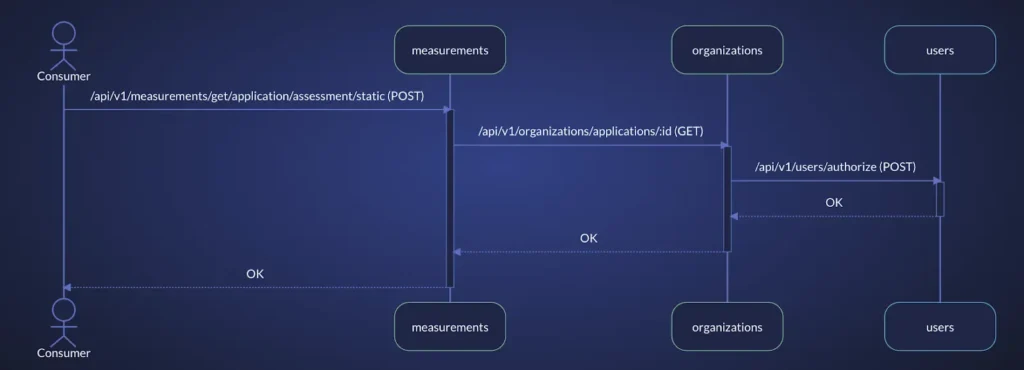
Alternatively, vFunction’s architectural observability uses tracing data in distributed microservices environments to create sequence diagrams that illuminate application flows, allowing teams to detect bottlenecks and overly complex processes before they degrade performance. By visualizing these flows, teams can quickly link incidents to architectural issues.

Managing dependencies
Managing dependencies adds another layer of complexity. Microservices often rely on external services or APIs, which can be unavailable or unstable during testing. Strategies like stubbing or mocking these dependencies provide a controlled environment for testing individual services without relying on external systems.
Maintaining consistent and representative test data across multiple environments is also a hurdle. Data integrity is crucial, and establishing processes for managing test data and refreshing test environments regularly is essential.
Ensuring adequate test coverage
Ensuring adequate test coverage remains an ongoing challenge as microservices evolve and new services are introduced. Regularly reviewing and updating test suites is essential to keep up with changes and ensure high confidence in the system’s reliability.
Replicating production environments
Replicating the production environment for testing can be complex and resource-intensive. Cloud-based solutions and containerization technologies offer scalable and realistic test environments, but careful planning and configuration are necessary to ensure accuracy and avoid unexpected discrepancies.
Addressing challenges in microservices testing
Being aware of these challenges and having strategies to address them is key for successful microservices testing. Don’t hesitate to leverage tools, techniques, and best practices to overcome these obstacles and build reliable and resilient microservices applications.
Real-world examples and case studies
Netflix
Pioneering the microservices architecture, Netflix has developed a robust testing ecosystem that includes extensive unit testing, integration testing, and chaos engineering. They emphasize the importance of automation and continuous testing to ensure the resilience of their streaming platform.
Amazon
With a vast array of microservices powering their e-commerce platform, Amazon relies heavily on automated testing and canary deployments to validate changes before releasing them to production. They also prioritize monitoring and observability to detect and address issues proactively.
Uber
Managing a complex network of microservices for their ride-hailing platform, Uber leverages contract testing and service virtualization to ensure compatibility between services. They also invest in performance testing to maintain optimal user experience even under high load.
These examples demonstrate that successful microservices testing requires a combination of strategies, tools, and a commitment to continuous improvement. By learning from industry leaders and adapting their practices to your context, you can achieve similar success in your microservices testing journey.
How vFunction enhances microservices testing
Testing microservices can be complex and requires testing from multiple angles. On top of more traditional testing methods, such as unit or integration testing, vFunction’s platform augments the testing process by providing AI-powered insights and tools that can help enhance test coverage and service reliability. Here are a few areas where vFunction can help:
- Comprehensive architecture analysis: vFunction uses AI-powered architectural observability in distributed applications to map real-time relationships and dependencies within the services contained in your microservices architecture. This gives architects and developers a deeper understanding of the architecture and ensures that all critical interactions are tested thoroughly.
- Architecture governance: vFunction’s AI-driven architecture governance provides essential guardrails for distributed applications, helping teams combat microservices sprawl and reduce technical debt. By setting rules for service communication, enforcing boundaries, and maintaining database-to-microservice relationships, vFunction ensures architectural integrity.
- Sequence flow diagrams: Get a detailed view of application flows to identify efficient processes and those at risk due to complexity. By visualizing flows in distributed architectures, vFunction simplifies tracking problematic flows and monitoring changes over time.
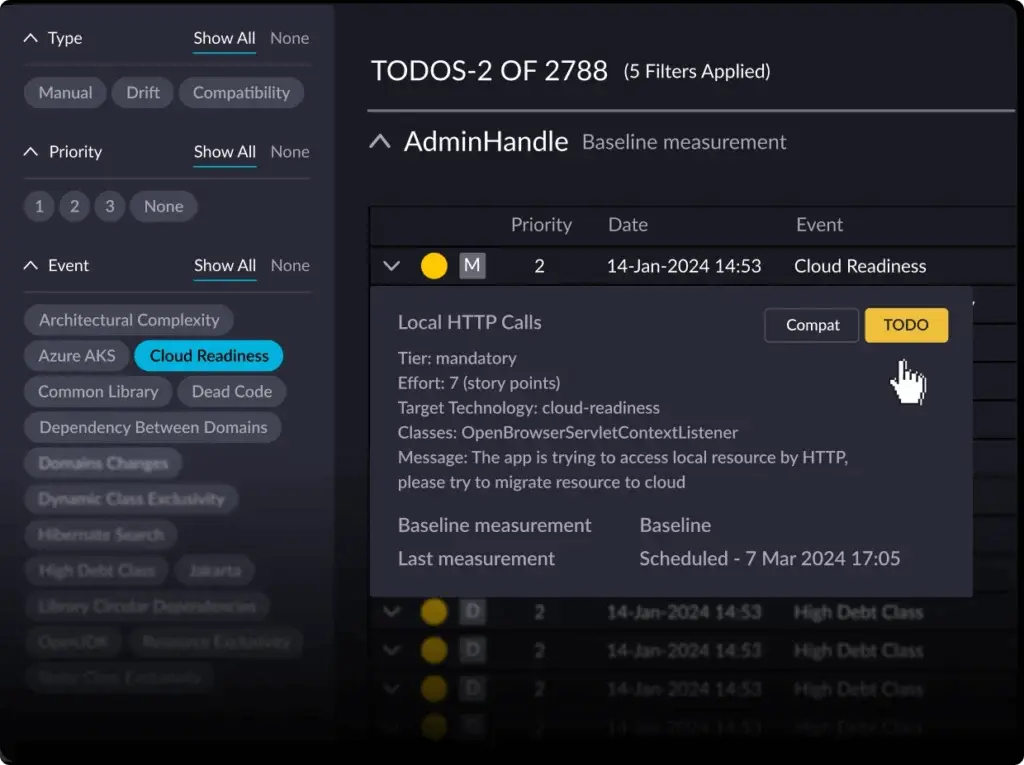
- Testing for architectural drift: Most applications have a current and target state for their architecture. With vFunction, microservices can be tracked to test for architectural drift and team members notified when architecture changes. This helps ensure that the application’s architecture aligns with the target state and does not drift too far off the mark.
- Continuous observability: vFunction’s platform offers continuous architectural observability, allowing teams to monitor changes, refactor iteratively, and maintain high standards of reliability in their microservices testing. When testing and fixing defects and bugs uncovered through other testing methods, vFunction continuously observes the changes within the application. This gives architects a real-time and direct line of sight for changes happening within the application.
Integrating vFunction into your testing workflow ensures that your microservices architecture remains robust, scalable, and ready for continuous development and deployment. By keeping an eye on architectural changes that may occur throughout the development and testing processes associated with microservices development, vFunction helps to ensure that the underlying architecture is resilient and aligns with your target state.
Conclusion
Microservices testing is an integral part of building robust and reliable applications. By understanding the different types of tests, adopting effective strategies, leveraging automation, and following best practices, you can overcome the complexities of microservices testing and deliver high-quality software that meets the demands of your users.
Testing is an ongoing process, as your microservices evolve and new services are added, it’s crucial to continuously refine your testing approach. Embrace the challenges, learn from industry leaders, and invest in the right tools and techniques to ensure the success of your microservices testing efforts.
And if you’re looking for a powerful solution to provide visibility, analysis and control across your microservices, consider exploring vFunction’s AI-driven platform. vFunction empowers teams to visualize their distributed architecture, identify complex flows and duplicate functionality, and establish self-governance by setting architectural rules for more manageable microservices.