Are you wondering about the differences between monolithic applications and microservices? It can be confusing, but as more companies move to a cloud-first architecture, it’s essential to understand these terms.
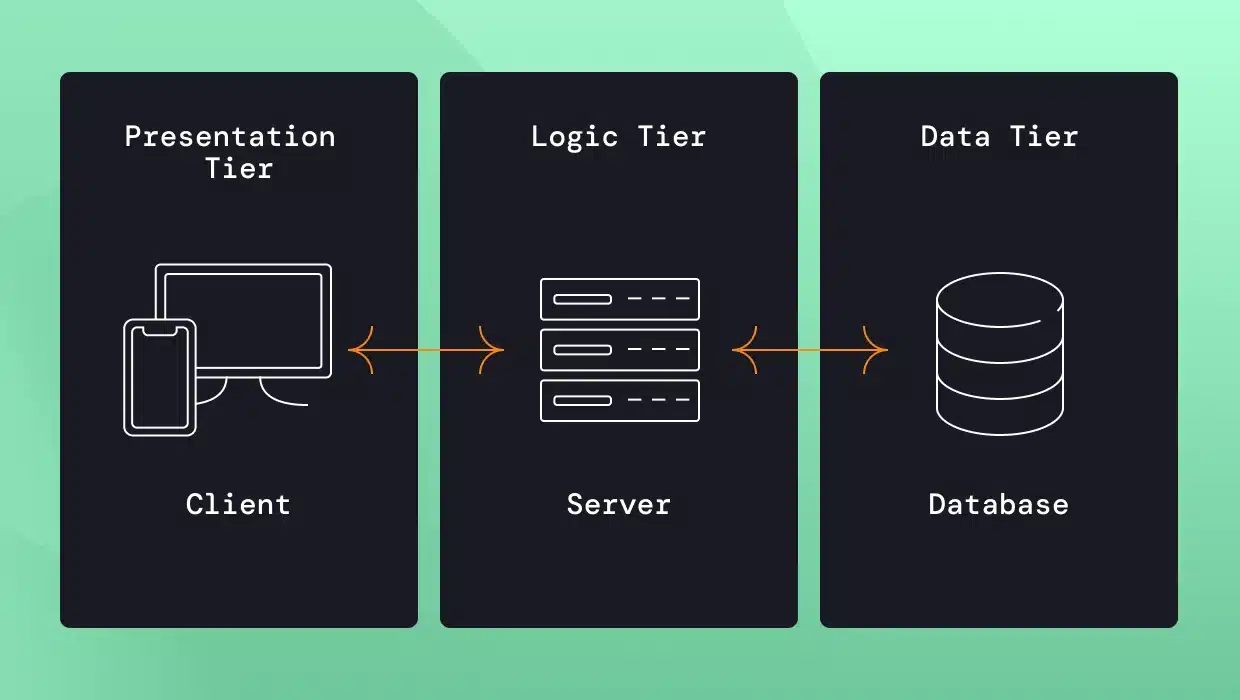
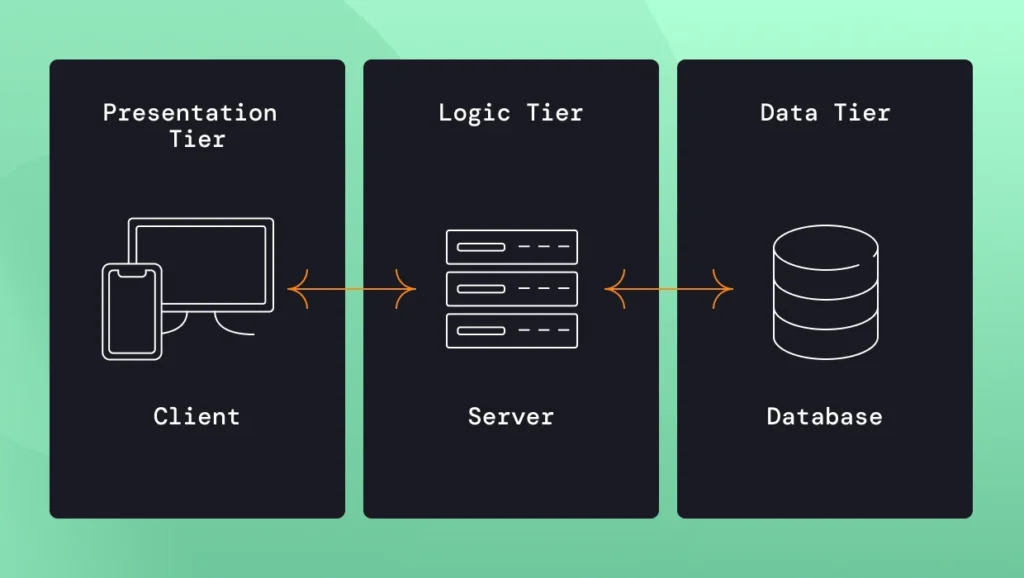
An enterprise application usually consists of three parts: a client-side application, a server-side application, and a database. Our focus is on the server-side application, which handles the business logic, interacts with various clients and potentially other external systems, and uses one or more databases to manage the data. This part is typically the most complex and requires most of the development and testing efforts.
It may be built as one large “monolithic” block of code or as a collection of small, independent, and reusable pieces called microservices. Most legacy applications have been built as monoliths, and converting them to microservices has benefits and challenges.
What is a monolithic architecture?
A monolithic architecture is a traditional software design approach where all components of an application are tightly integrated into a single, unified codebase. Think of it as a large container housing the entire application’s functionality, including:
- User interface (UI): The frontend layer presents information to users.
- Business logic: The core application logic processes data and implements business rules.
- Data access layer: The component that interacts with databases or other data sources.
In this 3 tier architecture, the three tiers are not independent components and there are dependencies between classes across the layers which typically becomes very complex as the application evolves. This leads to a high risk of causing regressions when introducing changes to the code because it is hard to predict how a change in one class will impact others. The application is deployed as a single unit; for example, a Java WAR (Web Archive) is deployed into an application server or a native executable file.
While this approach offers simplicity in the early stages of development, it can lead to challenges as the application grows in size and complexity. The tight coupling of components can make it challenging to scale, update, or maintain individual parts without affecting the entire system. In contrast, microservices architecture, which we will cover later, addresses these issues by breaking down the application into smaller, independent services, making it easier to manage, scale, and maintain.
Advantages of a monolithic architecture
Understanding the benefits of monolithic and microservices architecture is critical to making an informed decision about the right approach for your project.
Simplified development and deployment
Monoliths excel in simplicity. A typical monolithic application, where all data objects and actions are handled by a single codebase and stored in a single database, makes development and deployment more straightforward, especially for smaller applications or projects with limited resources. There’s no need to manage complex inter-service communication or orchestrate multiple deployments.
End-to-end testing
End-to-end testing is typically easier to perform in a monolithic structure. Since all components reside within a single unit, testing the entire application flow is more streamlined, potentially reducing the complexity and time required.
Performance
In some cases, monolithic applications can outperform microservices regarding raw speed. This is because inter-service communication in microservices can introduce latency. With their unified codebase and shared memory, Monoliths can sometimes offer faster execution for certain operations.
Debugging
Monoliths often provide a more straightforward debugging experience. With all code residing in one place, tracing issues and identifying root causes can be more intuitive compared to navigating the distributed nature of microservices.
Reduced operational overhead
Initially, monolithic architectures may require less operational overhead. Managing a single application can be easier than managing a multitude of microservices, each with its own deployment and scaling requirements.
Cost-effectiveness
Monolithic architecture can be a more cost-effective option for smaller projects or those with limited budgets. However, the complexity of setting up and maintaining a microservices infrastructure can introduce additional expenses.
Remember, the ideal architectural choice depends on your project’s specific needs. While monoliths offer simplicity and ease of use, they may not be suitable for larger, complex applications where scalability, flexibility, and independent development are paramount.
Disadvantages of a monolithic architecture
While monolithic architecture offers simplicity and ease of use, it has drawbacks. These limitations become increasingly apparent as applications grow in size and complexity.

Scalability challenges
Monolithic systems can be challenging to scale. To cater to high workloads, you can either add more resources (CPU, memory) and/or replicate the entire monolith over multiple computational nodes with a load balancer, even if only specific components are experiencing high demand. This is inefficient resource utilization leading to increased costs.
Limited technology flexibility
Monolithic applications are built using a single technology stack. This can limit the ability to adopt new technologies or frameworks, as changes require rewriting a large part of the application.
Tight coupling and reduced agility
In a monolithic architecture, components are tightly coupled, making changes or updates to individual parts more challenging. This can slow development and deployment cycles, hindering agility and responsiveness to changing requirements. Also, testing the entire functional scope of a complex monolith is challenging, as is achieving sufficient coverage.
Increased complexity over time
As monolithic applications grow, their data storage mechanisms typically rely on a single database, which can lead to an increasingly complex and difficult-to-manage codebase. This can result in longer development cycles, a higher risk of errors, and challenges in understanding the system’s overall behavior.
Single point of failure
Monolithic architectures represent a single point of failure. If a critical component fails, the entire application can go down, impacting availability and causing significant disruptions.
Deployment risks
Deploying updates to a monolithic application can be risky. Even minor changes require a full redeployment of the entire system, increasing the likelihood of introducing errors or unforeseen side effects.
Remember, the disadvantages of monolithic architecture become more pronounced as applications scale. For large, complex systems, the limitations of monoliths can significantly impact development, deployment, scalability, and overall agility.
What are microservices?
A microservice architecture consists of small, independent, and loosely coupled services. It offers significant benefits and challenges when migrating from a monolithic architecture to a microservices architecture. Microservices are small autonomous services organized around business or functional domains. A single small development team often owns each service.
Every service can be an independent application with its own programming language, development and deployment framework, and database. Each service can be modified independently and deployed by itself. A Gartner study shows that microservices can deliver better scalability and flexibility.
Advantages of microservices
There are many benefits to choosing a microservices architecture, including scalability, agility, velocity, upgradability, cost, and many others. The Boston Consulting Group has listed the following benefits.
Emphasis on capabilities and values
Well designed microservices correspond to functional domains, or business capabilities, and have well defined boundaries. Users of a microservice don’t need to know how it works, what programming language it uses, or its internal logic. All that they need to know is how to call an API (Application Programming Interface) method provided by the microservice (usually routed through an API gateway) and what data it returns. When designed well, microservices can be reused across applications and deliver business capabilities more flexibly.
Agility
A microservice is designed to be decoupled, so changes made to it will have little or no impact on the rest of the system. The developers don’t need to worry about complex integrations. This makes it easier to make and release changes. For the same reason, the testing effort can be focused, reducing testing time as well. This results in increased agility.
Upgradability
One of the biggest differentiators between monolithic applications and microservices is upgradability, which is critical in today’s fast-moving marketplace. You can deploy a microservice independently, making fixing bugs and releasing new features easier.
You can also roll out a single service without redeploying the entire application. If you find issues during deployment, the erring service can be rolled back, which is easier than rolling back the full application. A good analogy is the watertight compartments of a ship—flooding is confined.
Small teams
A well-designed microservice is small enough for a single team to develop, test, and release. The smaller code base makes it easier to understand, increasing team productivity. Microservices are not coupled by business logic or data stores, minimizing dependencies. All this leads to better team communication and reduced management costs.
Flexibility in the development environment
Microservices are self-contained. So, developers can use any programming language, framework, database, or other tools. They are free to upgrade to newer versions or migrate to using different languages or tools if they wish. No one else is impacted if the exposed APIs are not changed.
Scalability
If a monolith uses up all available resources, it can be scaled by creating another instance. If a microservice uses up all resources, only that service will need more instances, while other services can remain as is. So scaling is easy and precise. The least possible number of resources is used, making it cheaper to scale.
Automation
When comparing monolithic applications to microservices, the benefit of automation can’t be stressed enough. Microservices architecture enables the automation of several otherwise tedious and manual core processes, such as integration, building, testing, and continuous deployment. This leads to increased productivity and employee satisfaction.
Velocity
All the benefits listed above result in teams focusing on rapidly creating and delivering value, which increases velocity. Organizations can respond quickly to changing business and technology requirements.
How to convert monoliths to microservices
There are two ways of migrating monolithic apps to microservices: manually or through software automation.
A well-defined migration strategy is crucial for planning and executing the transition from monolithic applications to microservices. The migration process needs to consider several factors. The guidelines below have been recommended by Martin Fowler and are applicable whether you are trying to manually modernize your app or using automated tools.
Identify a simple, decoupled functionality
Start with functionality that is already somewhat decoupled from the monolith, does not require changes to client-facing applications, and does not use a data store. Convert this to a microservice. This helps the team upskill and set up the minimum DevOps architecture to build and deploy the microservice.
Cut the dependency on the monolith
The dependency of newly created microservices on the monolith should be reduced or eliminated. In fact, during the decomposition process, new dependencies are created from the monolith to the microservices. This is okay, as it does not impact the pace of writing new microservices. Identifying and removing dependencies is often the most challenging part of refactoring.
Identify and split “sticky” capabilities early
The monolith may have “sticky” functionality that makes several monolith capabilities depend on it. This makes it difficult to remove more decoupled microservices from the monolith. To proceed, it may be necessary to refactor the relevant monolith code, which can also be very frustrating and time-consuming.
Decouple vertically
Most decoupling efforts start with separating the user-facing functionality to allow UI changes to be made independently. This approach results in the monolithic data store being a velocity limiting factor. Functionality should instead be decoupled in vertical “slices,” where each includes functionality encompassing the UI, business logic, and data store. Having a clear understanding of what business logic relies on what database tables can be the hardest thing to untangle.
Decouple the most used and most changed functionality
One goal of moving microservices to the cloud is to speed up changes to features existing in the monolith. The development team must identify the most frequently modified functionality to enable this. Moving this capability to microservices provides the quickest and most ROI. Prioritize the business domain with the highest business value to refactor first.
Go macro, then micro
The new “micro” services should not be too small initially because this creates a complex and hard-to-debug system. The preferred approach is to start with fewer services, each offering more functionality, then break them up later.
Migrate in evolutionary steps
The migration process should be completed in small but atomic steps. An atomic step consists of creating a new service, routing users to the new service, and retiring the code in the monolith that has been providing this functionality so far. This ensures the team is closer to the desired architecture with every atomic step.
What are the challenges of migrating monoliths to microservices?
While the strategic benefits of microservices are clear, the technical hurdles involved in the migration process can be significant. Understanding these challenges is crucial for planning a successful transition.
Decomposition of the monolith
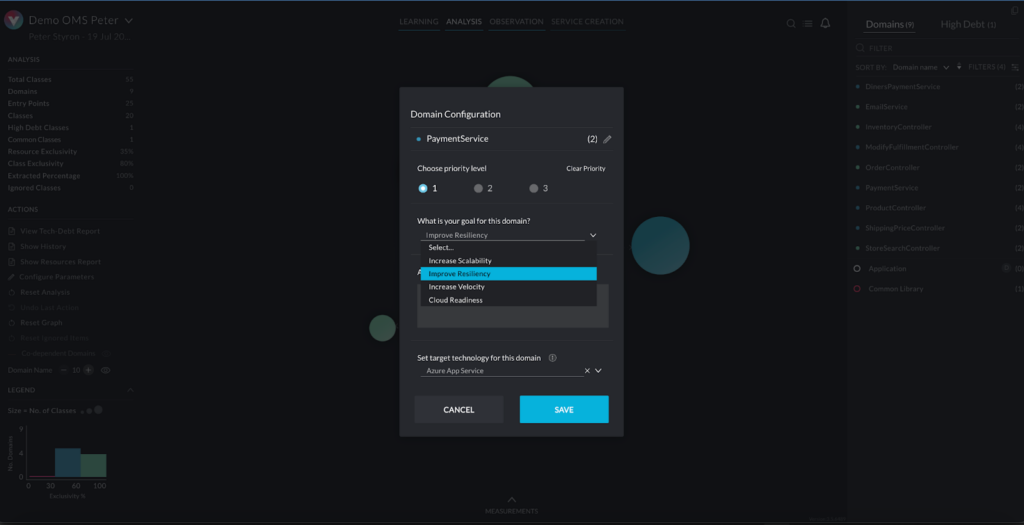
Breaking down a monolithic application into independent microservices is a complex task. Identifying service boundaries, managing dependencies, and refactoring code can be time-consuming and error-prone. Ensuring a smooth decomposition requires a deep understanding of the application’s domain and careful planning. Some teams try to use Domain Driven Design (DDD) techniques, such as event storming, to define the domains and their boundaries, but doing these whiteboard exercises may overlook critical details you can only discover by analyzing the actual implementation.
Data refactoring
Monolithic applications often rely on a single, centralized database. Migrating to microservices typically involves splitting this database into smaller, service-specific databases. This can involve complex data migration, ensuring data consistency across services, and managing distributed transactions. Pulling components and data objects out of the monolithic system often involves data replication, crucial for maintaining data integrity during the transition. Splitting the database requires a detailed understanding of how the various components are using the database tables and transactions.
Network latency and communication
Microservices communicate over a network, introducing latency that can impact performance. Designing efficient communication patterns, handling network failures, and managing potential bottlenecks are crucial for maintaining system responsiveness. Different approaches and protocols are used for microservices communications, such as using REST API, gRPC, or RabbitMQ. In some cases, microservices may exchange data over the data store instead of direct communications. Having a consistent approach for service-to-service communication is a key architectural decision.
Testing and monitoring
Testing and monitoring a distributed microservices architecture is more challenging than a monolithic one. Each service needs independent testing, and end-to-end testing becomes more complex due to the increased number of components and their interactions. Comprehensive monitoring and logging are essential to identify and address issues promptly.
Infrastructure and deployment
Microservices require a more sophisticated infrastructure and deployment pipeline. Each service needs independent deployment, scaling, and management, which can be a significant overhead compared to deploying a single monolith. Tools like containerization and orchestration platforms can help manage this complexity.
Technology diversity
Microservices allow for using different technologies for different services. While this offers flexibility, it also introduces challenges in managing multiple languages, frameworks, and libraries and ensuring their compatibility.
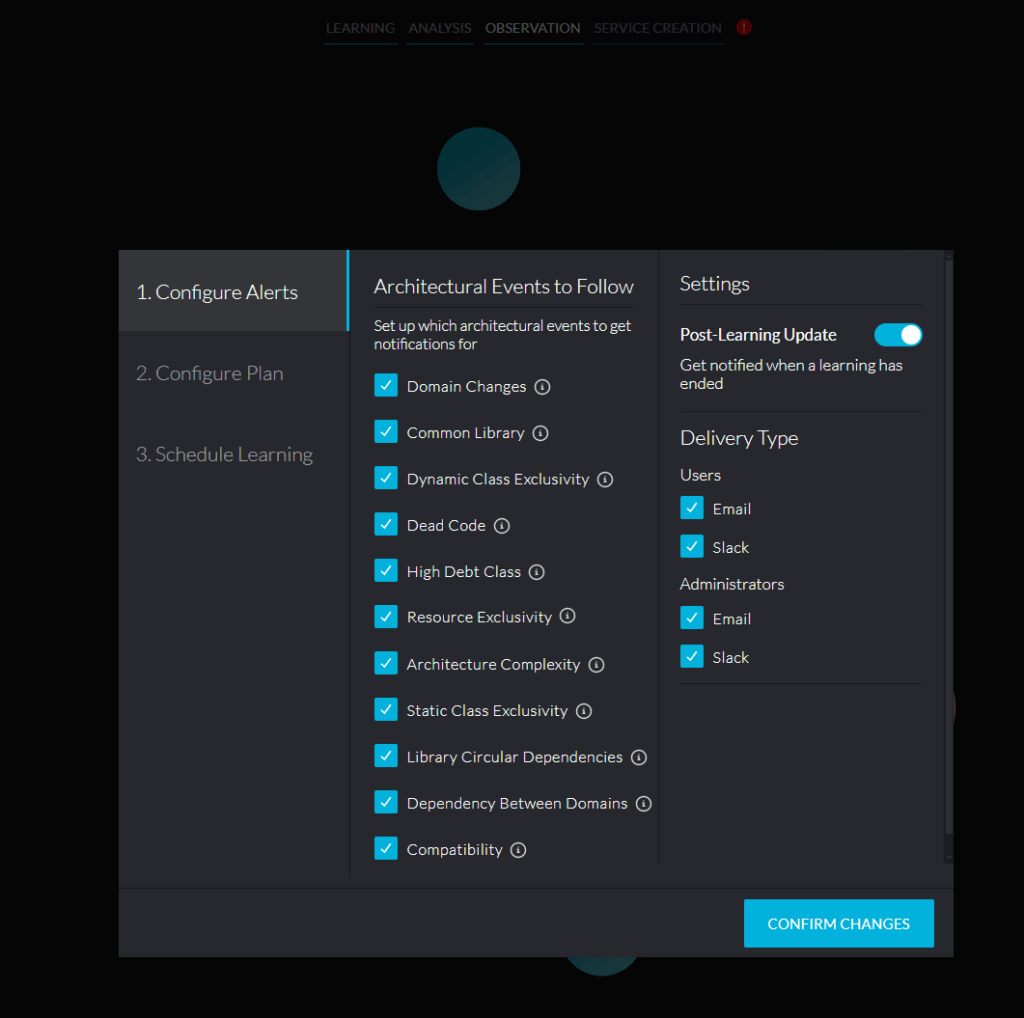
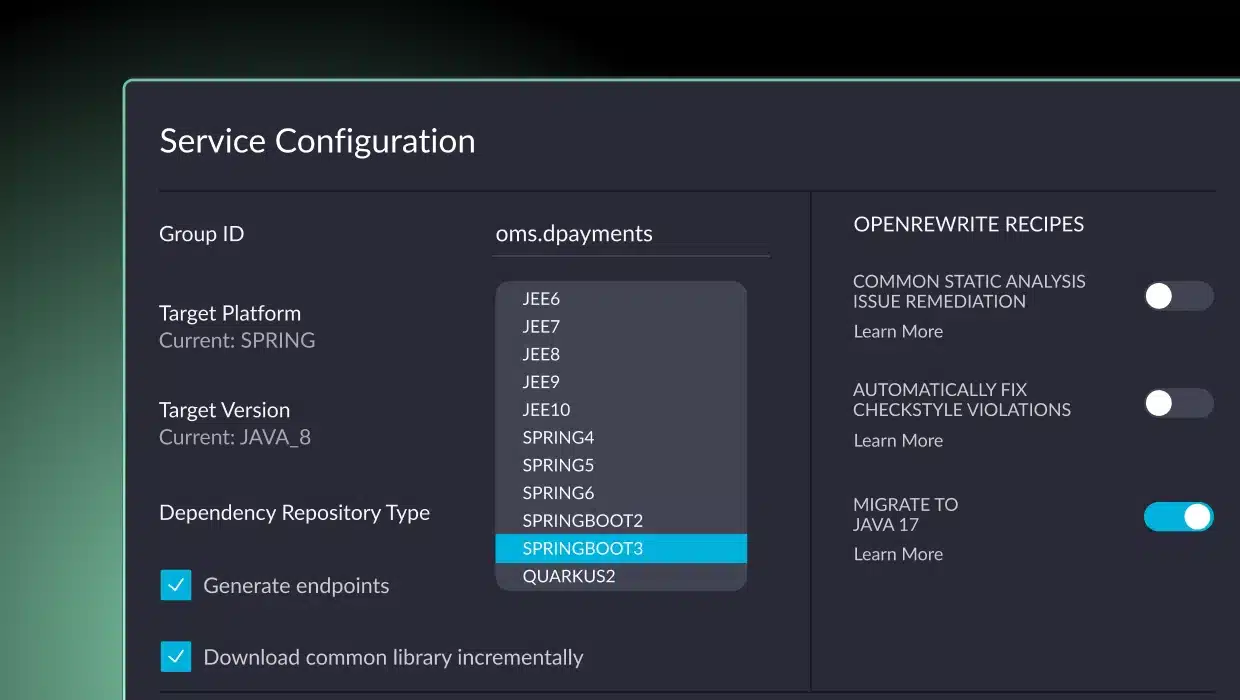
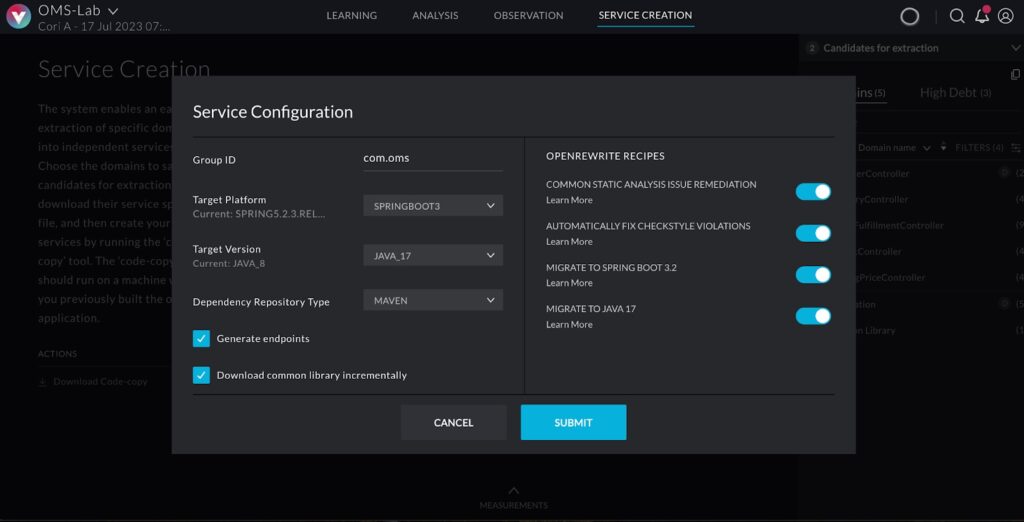
Using vFunction to expedite migrating from monoliths to microservices
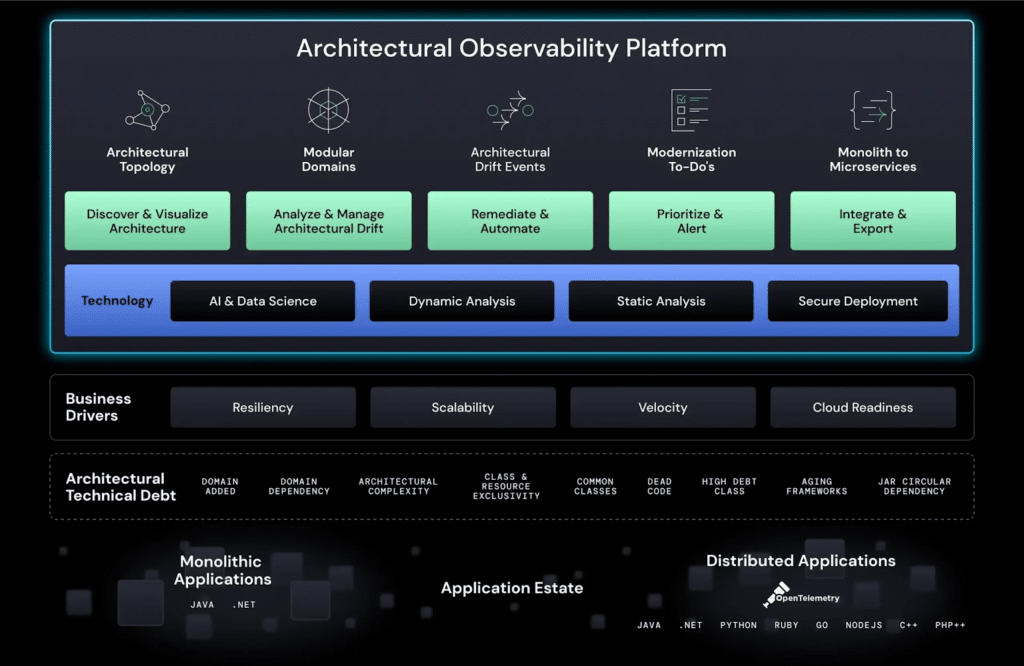
vFunction architectural observability platform automates and simplifies the decomposition of monoliths into microservices. How does it do this?
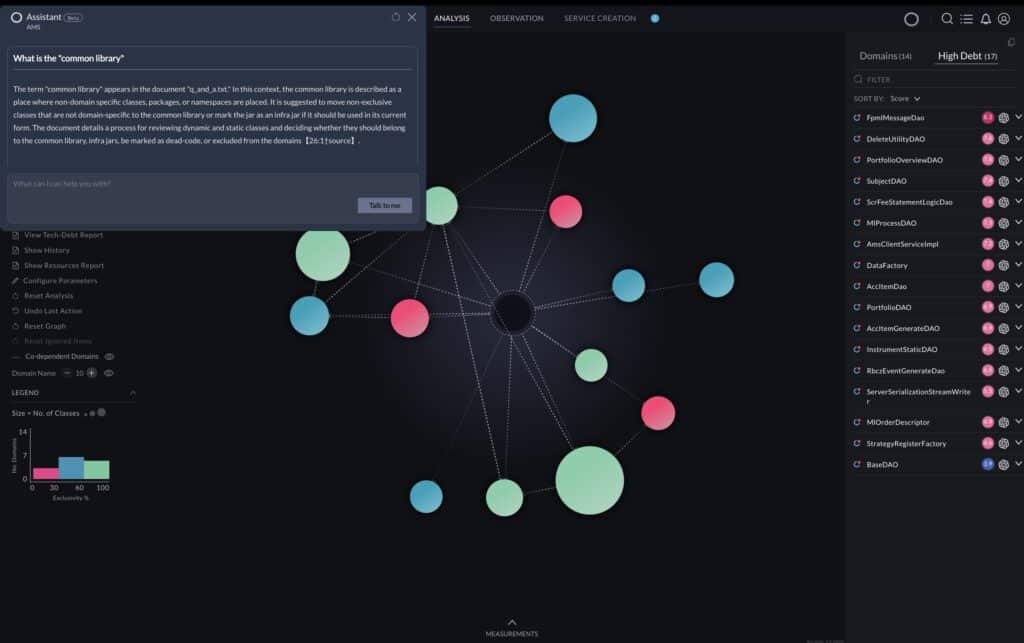
The platform collects dynamic and static analysis data using two components: for dynamic analysis, an agent traces the running application, which samples the call stacks and detects the usage of resources such as accessing databases and I/O operation of files and network sockets. For static analysis, there is a component called “Viper”, which analyzes the application’s binary files to derive compile time dependencies and analyze the application configuration files (e.g.. Bean definitions). Both data sets are provided to an analysis engine running on the vFunction server, which uses machine learning algorithms, to identify the business domains in the legacy monolithic app.
The combination of dynamic and static data provides a complete view of the application. This enables architects to specify a new system architecture in which functionality is provided by a set of smaller applications corresponding to the various domains rather than a single monolith.
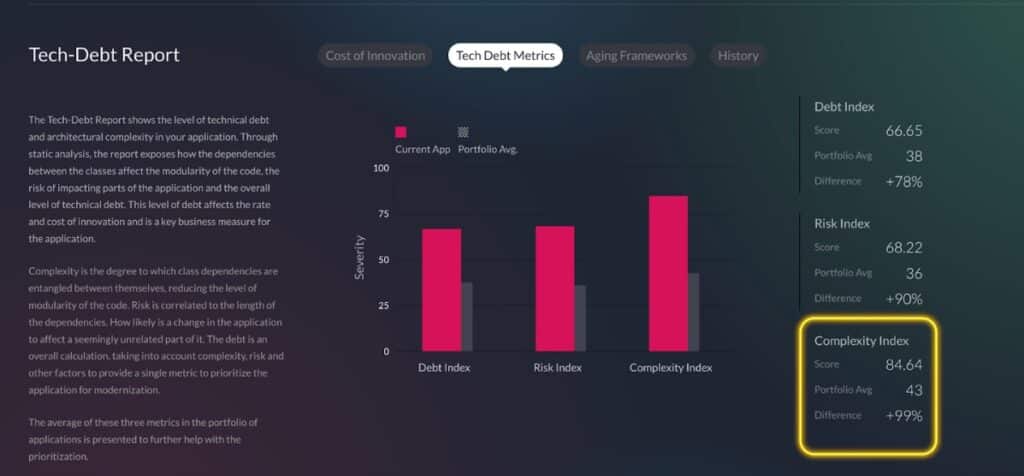
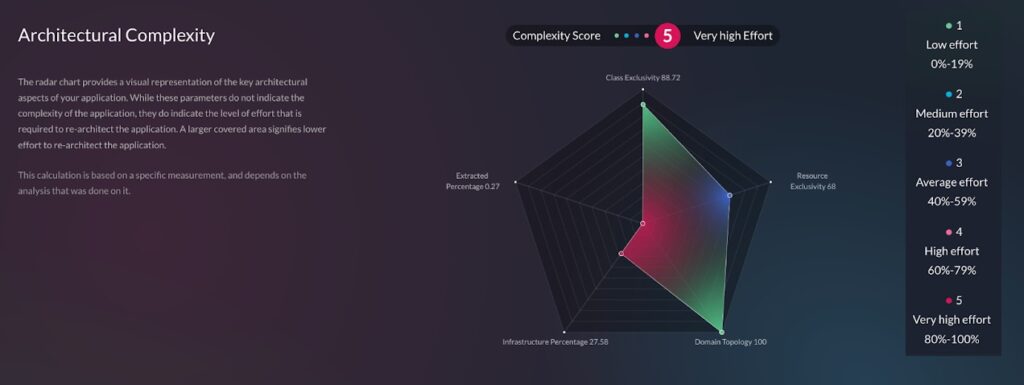
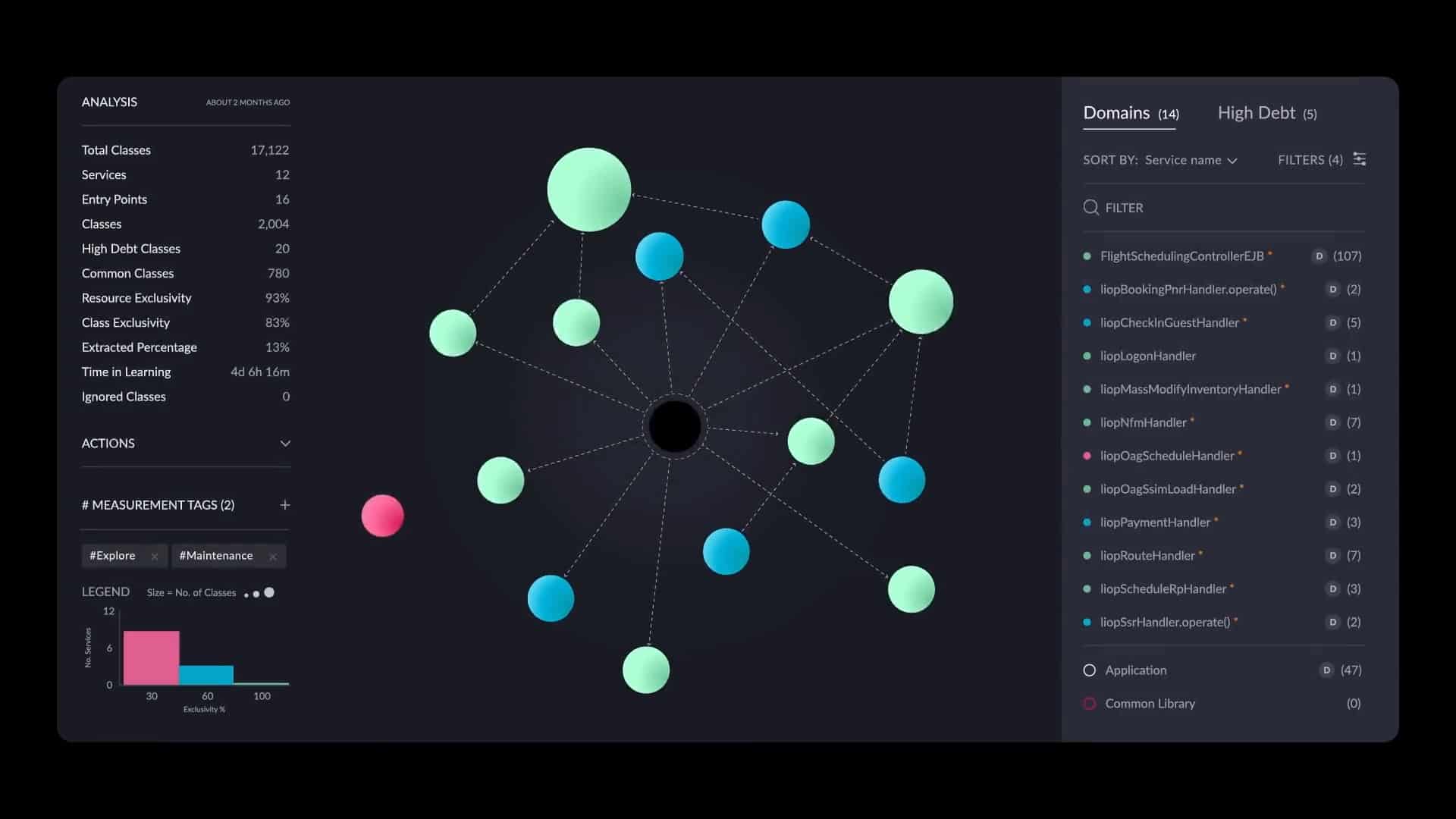
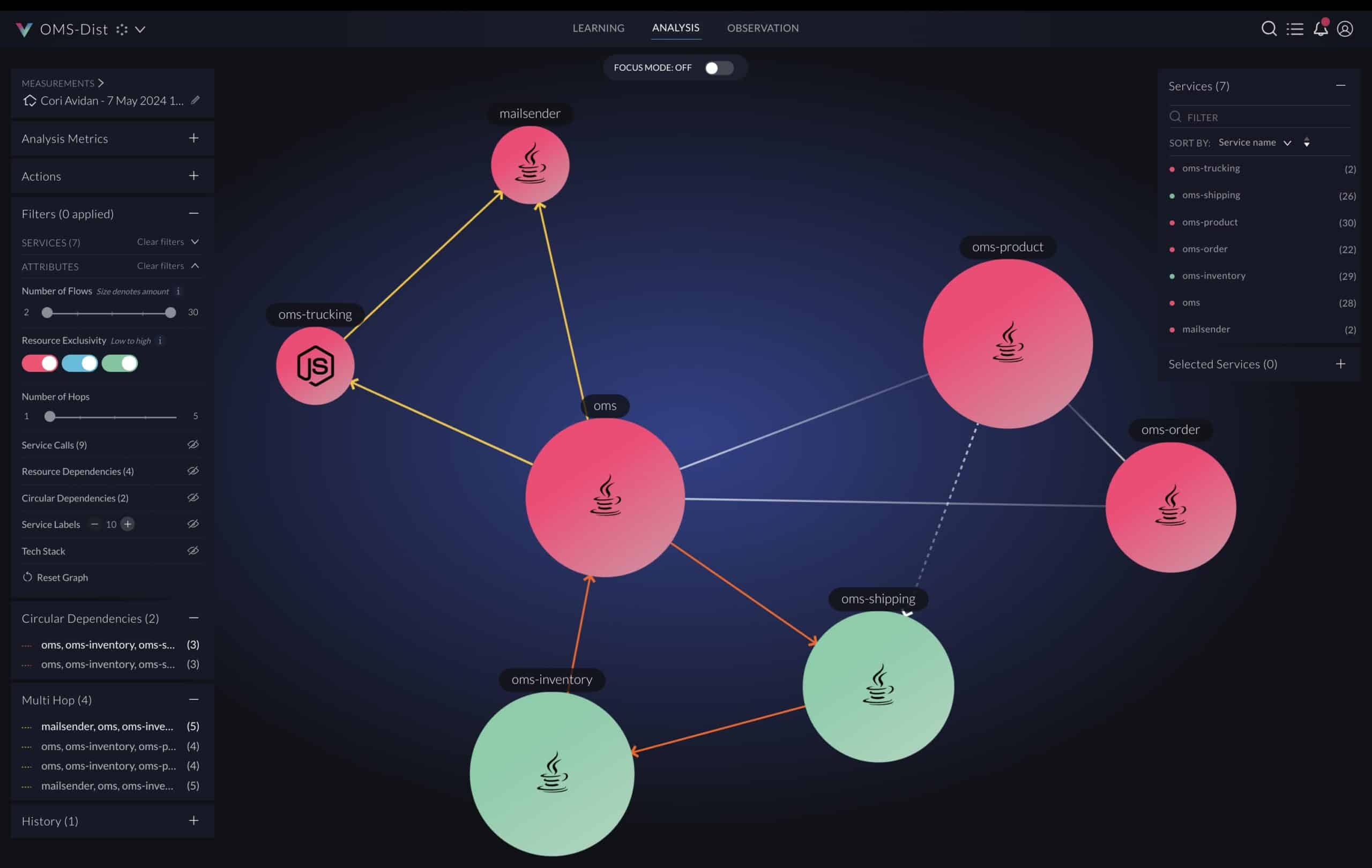
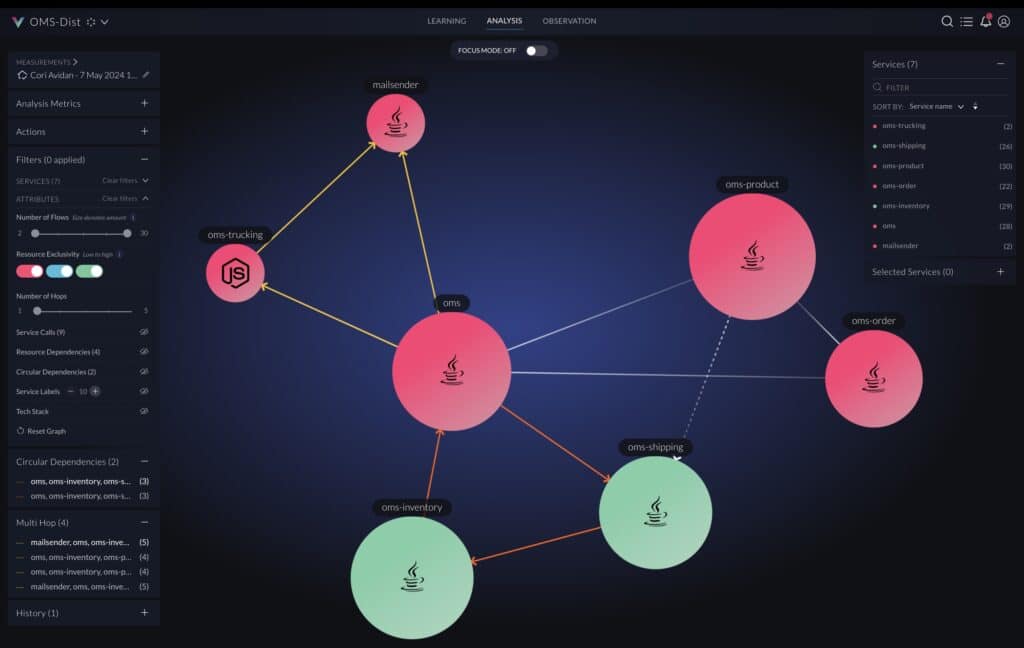
The platform includes custom analysis and visualization tools that observe the app running in real time and help architects see how it is behaving and what code paths are followed, including how various resources, such as database tables, files, and network sockets, are used from within these flows. The software uses this analysis to recommend how to refactor and restructure the application. These tools help maximize exclusivity (resources used only by one service), enabling horizontal scaling with no side effects. It handles code bases of millions of lines of code, speeding up the migration process by a factor of 15.
Many companies attempt the decomposition process using Java Profilers, Design and Analysis Tools, Java Application Performance Tools, and Java Application Tooling. However, these tools are not designed to aid modernization. They can’t help breaking down the monolith because they don’t understand the underlying interdependencies. So, the new architecture needs to be specified manually when using these tools.
Monolith to microservice examples
To illustrate how a monolith to microservices migration can be done, let’s look at a simple example of an e-commerce application called Order Management System (OMS) and how it could be refactored. The monolithic code of this application can be found here. As you can see in the readme file, it uses a classical 3-layer architecture:
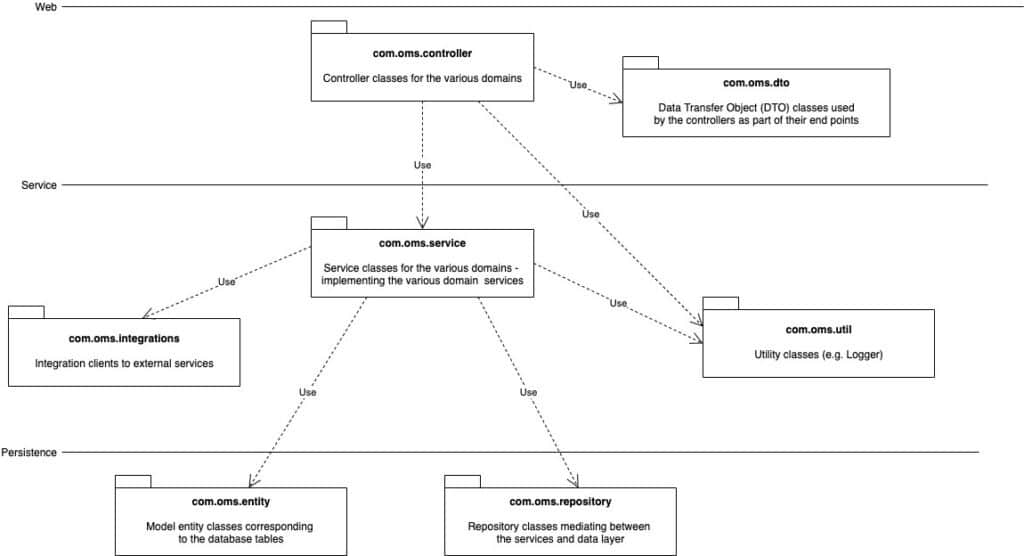
The web layer contains a package for controller classes exposing all the functionality of the monolith along with data transfer object (DTO) classes.
The service layer contains three packages implementing all the business logic, including integration with external systems, and the persistence layer contains the entity and repository classes to manage all the data in a MySQL database.
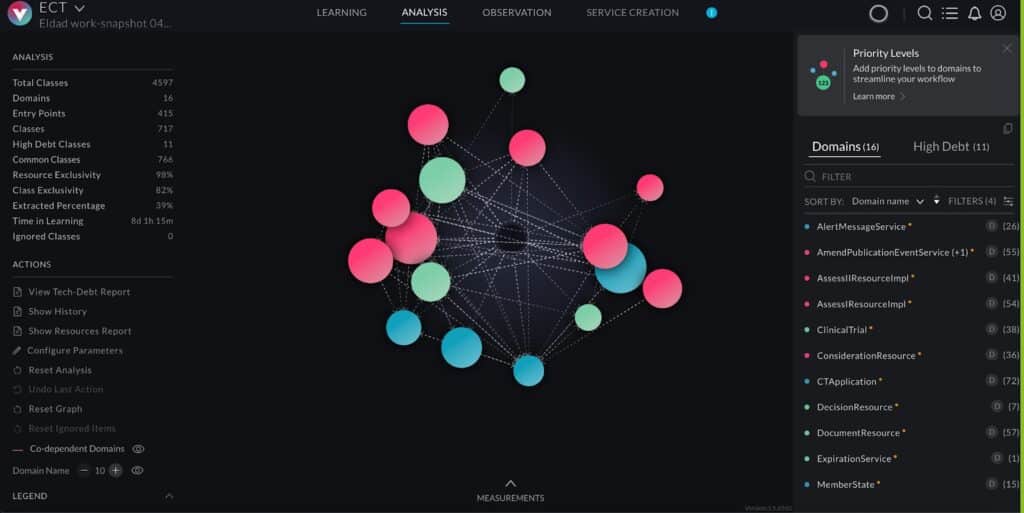
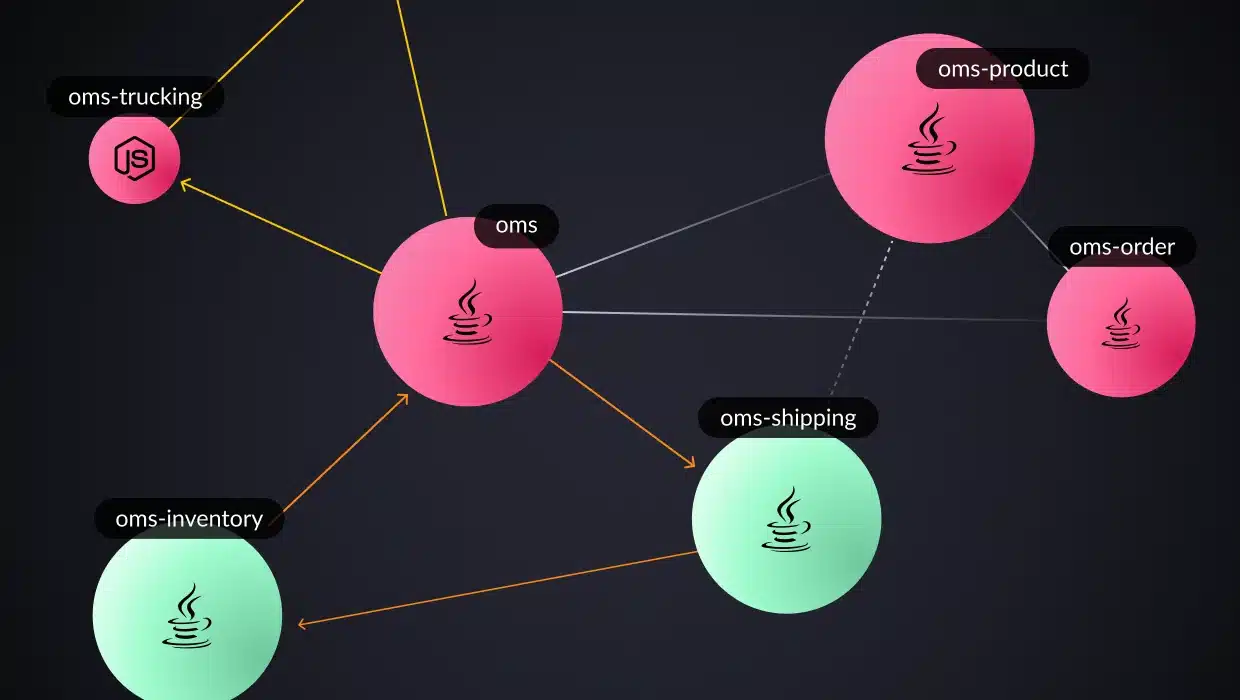
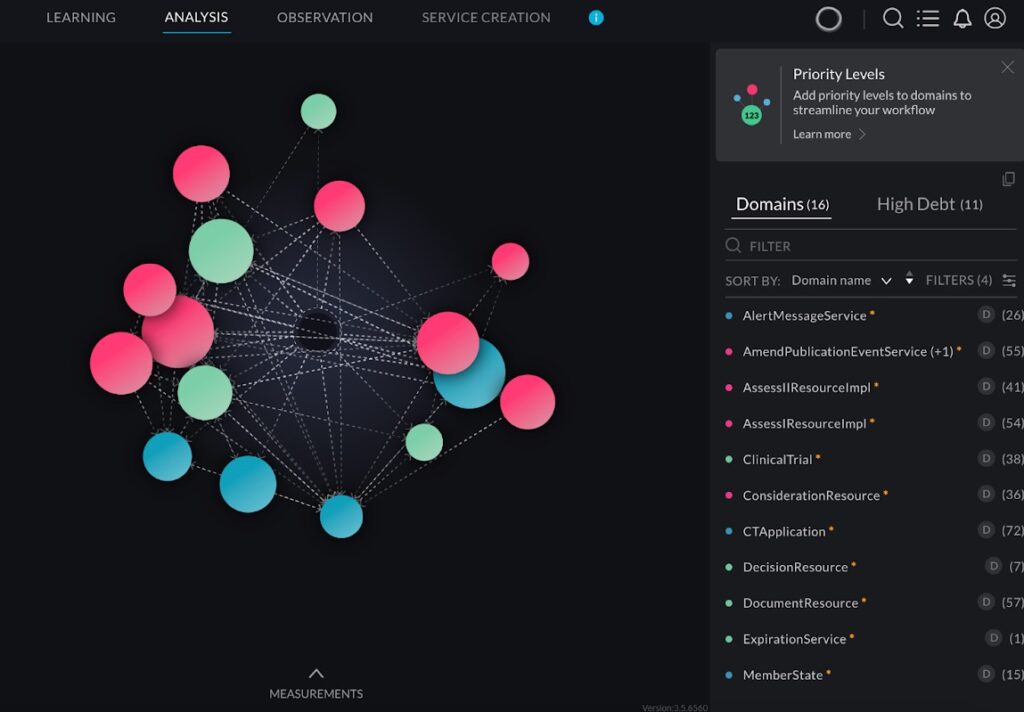
Analyzing the actual flows and the application binaries, the application is re-architected as a system of services corresponding to business domains, as seen in the figure below. Every sphere represents a service, and every dashed line represents calls triggering the services. Every service is defined by a set of entry points, classes that implement it, and the resources it uses. The specifications of the services can be used as input for vFunction Code Copy to create an implementation baseline for the services out of the original monolithic code.

Watch this short video on architectural observability to see how vFunction transforms monoliths into microservices.
Conclusion
Companies want to move fast. The tools provided by vFunction enable the modernization of apps (i.e., conversion from monoliths to microservices) in days and weeks, not months or years.
vFunction’s architectural observability platform for software engineers and architects intelligently and automatically transforms complex monolithic Java or .NET applications into microservices. Designed to eliminate the time, risk, and cost constraints of manually modernizing business applications, vFunction delivers a scalable, repeatable model for cloud-native modernization. Leading companies use vFunction to accelerate the journey to cloud-native architecture. To see precisely how vFunction can speed up your application’s journey to a modern, high-performing, scalable, true cloud-native, request a demo.