How to avoid mistakes when modernizing applications
As Chief Ecosystem Officer at vFunction, Bob Quillin is considered an expert in the topic of application modernization, specifically, modernizing monolithic Java applications into microservices and building a business case to do so. In his role at vFunction, inevitably, he is asked the question, “Where do I start?”
Modernizing can be a massive undertaking that consumes resources and takes years, if it’s ever done at all. Unfortunately, because of its scale, many organizations postpone the effort, only deciding to tackle it when there is a catastrophic system failure. Those who do dive into the deep waters of modernization frequently approach it from the wrong perspective and without the proper tools.
Where to start with modernizing applications boils down to which part of the application needs attention first. There are three layers to an application: The base layer is the database layer, the middle layer is the business logic layer, and the top layer is the UI layer.
In this interview with Bob, we discuss the challenges facing software architects and how approaching modernization by tackling the wrong layers first inevitably leads to failure, either in the short term or the long term.
Q: What do you see as the most common challenge enterprises face when deciding to modernize?
Bob: Most organizations recognize they have legacy monolithic applications that they need to modernize, but it’s not as easy as simply lifting the application and shifting it to the cloud. Applications are complicated, and their components are interconnected. Architects don’t know where to start. You have to be able to observe the application itself, how the monolithic application is constructed, and what is the best way to modernize it. Unfortunately, there isn’t a blueprint with clear steps, so the architect is going in blind. They’re looking for help in any form – clear best practices, tooling, and advice.
Q: With a 3-tier application, you’d think there are 3 ways to approach modernization, but you say this is where application teams often go wrong.
Bob: Many technology leaders want to do the easiest thing first, which is to modernize the user interface because it has the most visual impact on their boss or customers. If not the UI, they frequently go for the database where they store the data perhaps to reduce licensing costs or storage requirements. But the business logic layer is where business services reside and where the most competitive advantage and intellectual property are embedded. It isn’t the easiest layer to begin with, but by doing so, you make the rest of your modernization efforts much easier and more lasting.
Q: What’s the problem starting with the UI layer?
Bob: When you start with the UI, you actually haven’t addressed modernization at all. Modernization is designed to help you increase your engineering velocity, reduce costs, and optimize the application for the cloud. A new UI can have short term, visual benefits but does little to target the underlying problem – and when you do refactor that application, you’ll likely have to rewrite the UI again! Our recommendation is to start with the business logic layer — this is where you’ll find the services that have specific business value to be extracted. This allows you to directly solve the issue of architectural technical debt that is dragging your business down.
Q: What’s the value of extracting these services from the monolith?
Bob: In the past, everything was thrown together in one large monolithic “ball of mud.” The modernization goal is to break that ball of mud apart into smaller, more manageable microservices in the business logic layer so that you can achieve the benefits of the cloud and then focus on micro front-ends and data stores associated with each service. By breaking down the monolith into microservices, you can modernize the pieces you need to, and at that point, upgrading the UI and database becomes much easier.
Q: Tell me more about the database layer and the pitfalls of starting there.
Bob: The database layer should only be decomposed once as it often stores the crown jewels of the organization and should be handled carefully. It also a very expensive part of the monolith, mostly because of the licensing, so it often seems like a good place to start to cut costs. But decomposing the database is virtually impossible to do without understanding how the business logic is using it. What are the business logic domains that use the database? Each microservice should have its own data store, so you need the microservice architecture designed first. You can’t put the cart before the horse.
Data structures are sensitive. You’re storing a lot of business information in the database. It’s the lifeblood of the business. You only want to change that once, so change it after decomposing your business logic into services that access independent parts of the database. If you don’t do the business logic layer first, you’ll just have to decompose the database again later.
Q: Explain how breaking down monoliths in the business logic layer into microservices works with the database layer.
Bob: Every microservice should have its own database and set of tables or data services, so if you change one microservice, you don’t have to test or impact another. If you decompose the business logic with the database in mind, you can create five different microservices that have five different data stores, for example. This sequencing makes more sense and prevents having to cycle on the database more than once.
Also, clearly, you want to organize your access to the database according to the business logic needs versus the opposite. One thing we find when people lift and shift to the cloud, their data store is typically using the most expensive services that are available from cloud providers. The data layer is very expensive, especially if you don’t break down the business logic first. If you modernize first, you can have more economical data layer services from the get-go. If you start decomposing your business logic first, you have more efficient and optimized data services that save you money and are more cloud-native, fitting into a model going forward that gives you the cloud benefits you’re looking for. Go to business logic first, and it unlocks the opportunities.
Q: What’s the problem with starting modernization with whatever layer feels the most logical?
Bob: Modernization is littered with shortcuts and ways to avoid dealing with the hardest part, which is refactoring, breaking up and decomposing business logic. UI projects put a shiny front on top of an older app. If that’s a need for the business, that’s fine, but in the end, you still have a monolith with the same issues. It just now looks a little better.
A similar approach is taking the whole application and lifting and shifting it to the cloud. Sure, you’ve reduced data center costs by moving it to the cloud, but you’re delaying the inevitable. You just moved from one data center (your own) to a cloud data center (like AWS). It’s still a monolith with issues that only get bigger and cause more damage later.
Q: How does vFunction help with this?
Bob: Until vFunction, architects didn’t have the right tools. They couldn’t see the problem so they couldn’t fix it. vFunction enables organizations to do the hard part first, starting with getting visibility and observability into the architecture to see how it’s operating and where the architectural technical debt is, then measuring it regularly. Software architects need that visibility. If we can make it easier, faster, and data-driven, it’s a much more efficient path so that you don’t have to do it again and again.
Q: How do you focus on the business logic with vFunction?
Bob: If you’re going to build microservices, you need to understand what key business services are inside a monolith; you need a way to begin to pull those out and clearly identify them, establish their boundaries, and set up coherent APIs. That’s really what vFunction does. It looks for clusters of activities that represent business domains and essential services. You can begin to detangle and unpack these services, seeing the services that are providing key value streams for the business that are worth modernizing.
You can pull each out as a separate microservice to then run it more efficiently in the cloud, scale it, and pick the right cloud instances that conform to it. You can use all of the elasticity available in containers, Kubernetes, and serverless architectures through the cloud. You can then split up a database to represent just that part of the data domain the microservice needs, decomposing the database based on that microservice.
Q: Visibility is key here, right?
Bob: Yes. The difficulty is having visibility inside the monolithic application, and since you can’t see inside it or track technical debt, you have no idea what’s going on or how much technical debt is in there. The first step is to have the tools to observe and measure that technical debt and understand the profile, baseline it, and track the architectural patterns and drift over time.
Q: How does technical debt accumulate, and what can architects do about it?
Bob: You may see an application that was constructed in a way that maybe wasn’t perfect, but it was viable, and over time it erodes and gathers more and more architectural technical debt. There are now more business layers on top of it, more code that’s copied, and new architects come in. There are a lot of permutations that happen, and that monolith becomes untenable in its ability to fulfill changing requirements, updates, and maintenance. Monoliths are very brittle. Southwest Airlines and Twitter know this all too well.
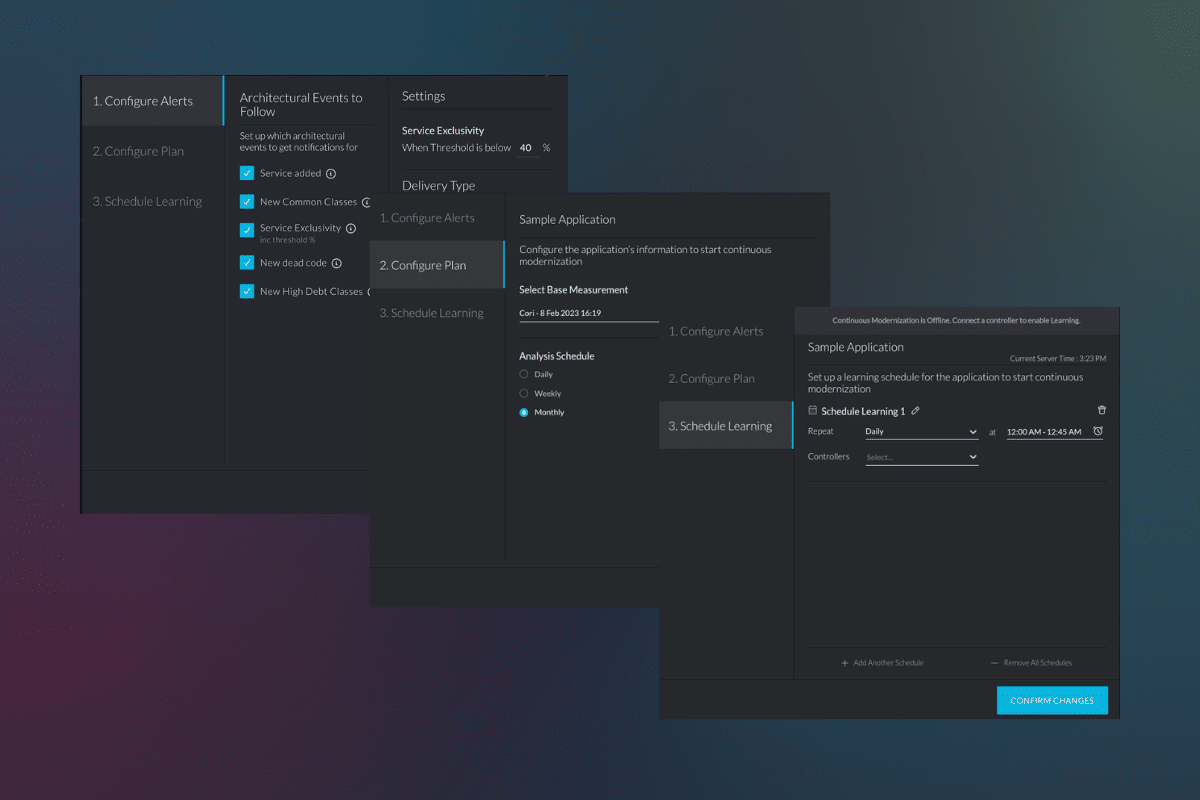
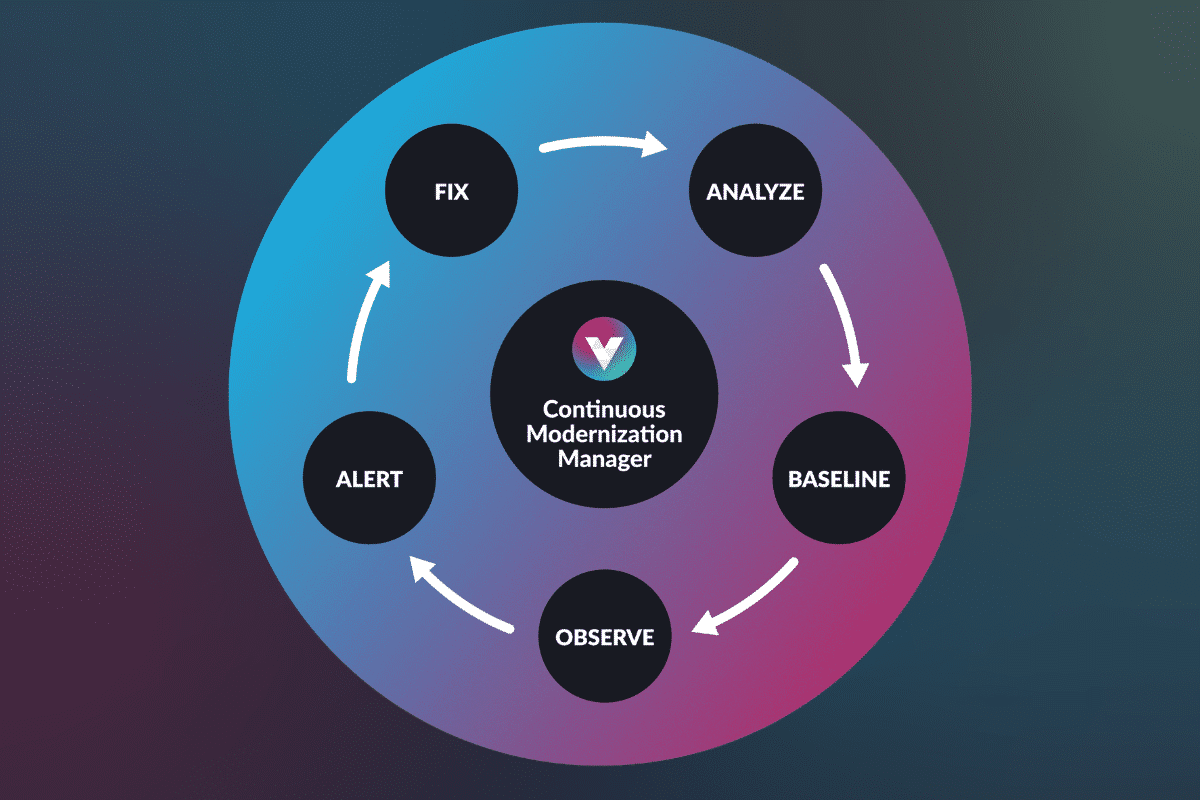
But this is where vFunction comes in to help you understand where that architectual technical debt is. You can use our Continuous Modernization Manager and Assessment Hub to provide visibility and tracking, and then our Modernization Hub helps you pull apart and identify the business domains and services.
Q: What infrastructure and platforms support the business logic?
Bob: Application servers run the business logic. Typically, we find Oracle WebLogic, IBM WebSphere, Red Hat JBoss, and many others. Monoliths are thus dependent on these legacy technology platforms because the business logic is managed by these application server technologies. This means that both the app server and database are based on older and more expensive systems that have older licensed technology written for another architecture or domain 10-20 years ago.
Q: What are the key benefits of looking at the business logic layer first?
Bob: By starting with the key factors that compose your architecture including the classes, resources, and dependencies, you start to deintirfy the key sources of architectural technical debt that need to be fixed. Within this new architecture, you want to create high levels of exclusivity, meaning that you want these components that contain and depend on the resource that are exclusive to each microservice. The primary goal is to architect highly independent of each other.
Q: And what does that mean for the developer?
Bob: For the developer, it increases engineering velocity.
In a monolith, if I want to change one thing, I have to test everything because I don’t know the dependencies. With independent microservices, I can make quick changes and turns, testing cycles go down, and I can make faster, more regular releases because my test coverage is much smaller and my cycles are much faster.
Microservices are smaller and easier to deal with, requiring smaller teams and a smaller focus. You can respond faster to customer feature requests. As a developer, you have much more freedom to make changes and move to a more Agile development environment. You can start using more DevOps approaches, where you’re shifting left all of the testing, operational and security work into that service because everything is now much more contained and managed.
Q: What does it mean from an operational perspective?
Bob: From an operational perspective, if the application is architected with microservices, you have more scalability in case there’s a spike in demand. With microservices and container technology, you can scale horizontally and add more capacity. With a monolith, if I do that, I might only have a certain amount of headroom, and I can’t buy a bigger machine. With memory and CPU limits, I can’t scale any further. I may have to start replicating that machine somewhere else. By moving to microservices, I have more headroom to operate and meet customer demand.
So, developers get higher velocity, it’s easier to test features, there’s more independence, and operationally, they get more scalability and resilience in the business. These benefits aren’t available with a monolith.
Q: This sounds like it requires a cultural shift to get organizations thinking differently about modernization.
Bob: Definitely. From a cultural perspective, you can start to adopt more modern practices and more DevOps technologies like CI/CD for continuous integration and continuous delivery. You’re then working in a modern world versus a world that was 20-30 years ago.
As you start moving monoliths to microservices, we hear all the time that engineering morale goes up, and retention and recruiting are easier. It’s frustrating for engineers to have a backlog of feature requests you can’t respond to because you have a long test cycle. The business gets frustrated, and engineers get frustrated, which leads to burnout. Modernizing puts you in a better position to meet business demands and, honestly, have more fun.
Q: Are all monoliths bad?
Bob: No, not all monoliths are bad. When you start decomposing a monolith that results in many microservices and teams, you should have a more efficient, scalable, higher-velocity organization, but you also have more complexity. While you’ve traded one set of complexities for another you are getting extensive benefits from the cloud. With the monolith, you couldn’t make changes easily, but now, with microservices, it’s much easier to make changes since you are dealing with fewer interdependencies While the application may be more efficient it may not be as predictable as it was before given its new native elasticity.
As with any new technology, this evolution requires new skillsets, training, and making sure your organization is prepared with the relevant cloud experience with container technologies and DevOps methodologies, for instance. Most of our customers already have applications on the cloud already and have developed a modern skillset to support that. But, with every new architecture comes a new set of challenges.
Modernization needs to be done for the right reasons and requires a technical and cultural commitment as a company to be ready for that. If you haven’t made those changes or aren’t ready to make those changes, then it’s probably too soon to go through a modernization exercise.
Q: What is the difference between an architect trying to modernize on their own versus using a toolset like vFunction offers?
Bob: Right now, architects are running blind when it comes to understanding the current state of their monolithic architectures. There are deep levels of dependencies with long dependency chains, making it challenging to understand how one change affects another and thus how to untangle these issues.
Most tools today look at code quality through static analysis, not architectural technical debt. This is why we say vFunction can help architects shift left back into the software development lifecycle. We provide observability into their architecture which is critical because architectural complexity is the biggest predictor of how difficult it will be to modernize your application and how long it will take. If you can’t understand and measure the architectural complexity of an application, you won’t be able to modernize it.
Q: Is vFunction the first of its kind in terms of the toolset it provides architects?
Bob: Yes. We have built a set of visibility, observability, and modernization tools based on science, data, and measurement to give architects an understanding of what’s truly happening inside their applications.
We also provide guidance and automation to identify where the opportunities are to decompose the monolith into microservices, with clear boundaries between those microservices. We offer consistent API calls and a “what if” mode — an interactive, safe sandbox environment where architects can make changes, rollback those changes, and share with other architects for greater collaboration, even with globally dispersed teams.
vFunction provides the tooling, measurement, and environment so architect and developers have a proactive model that prevents future monoliths from forming. We create an iterative best practice and organizational strategy so you can detect, fix, and prevent technical debt from happening in the future. Architects can finally understand architectural technical debt, prevent architectural drift, and efficiently move their monoliths into microservices.
Bob Quillin not only serves as Chief Ecosystem Officer at vFunction but works closely with customers helping enterprises accelerate their journey to the cloud faster, smarter, and at scale. His insights have helped dozens of companies successfully modernize their application architecture with a proven strategy and best practices. Learn more at vFunction.com.
Related Posts: